 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKaLM-Embedding-V2: Superior Training Techniques and Data Inspire A Versatile Embedding Model
Jun 26, 2025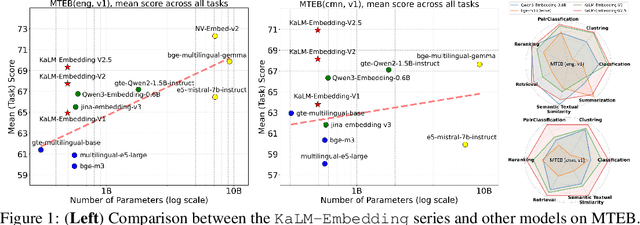
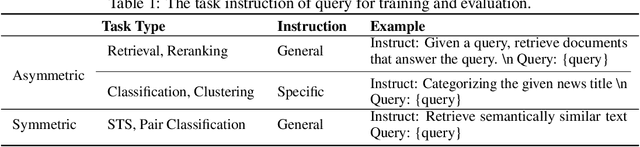

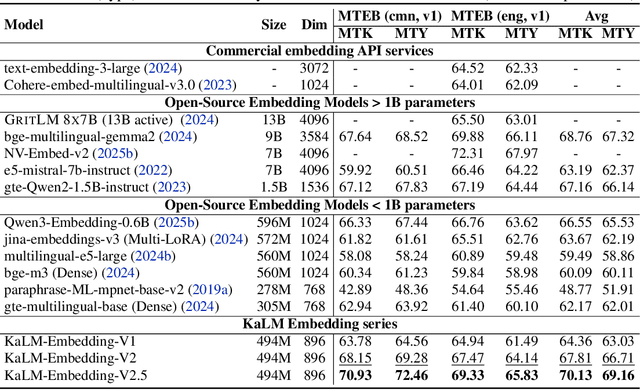
In this paper, we propose KaLM-Embedding-V2, a versatile and compact embedding model, which achieves impressive performance in general-purpose text embedding tasks by leveraging superior training techniques and data. Our key innovations include: (1) To better align the architecture with representation learning, we remove the causal attention mask and adopt a fully bidirectional transformer with simple yet effective mean-pooling to produce fixed-length embeddings; (2) We employ a multi-stage training pipeline: (i) pre-training on large-scale weakly supervised open-source corpora; (ii) fine-tuning on high-quality retrieval and non-retrieval datasets; and (iii) model-soup parameter averaging for robust generalization. Besides, we introduce a focal-style reweighting mechanism that concentrates learning on difficult samples and an online hard-negative mixing strategy to continuously enrich hard negatives without expensive offline mining; (3) We collect over 20 categories of data for pre-training and 100 categories of data for fine-tuning, to boost both the performance and generalization of the embedding model. Extensive evaluations on the Massive Text Embedding Benchmark (MTEB) Chinese and English show that our model significantly outperforms others of comparable size, and competes with 3x, 14x, 18x, and 26x larger embedding models, setting a new standard for a versatile and compact embedding model with less than 1B parameters.
D2R: dual regularization loss with collaborative adversarial generation for model robustness
Jun 08, 2025The robustness of Deep Neural Network models is crucial for defending models against adversarial attacks. Recent defense methods have employed collaborative learning frameworks to enhance model robustness. Two key limitations of existing methods are (i) insufficient guidance of the target model via loss functions and (ii) non-collaborative adversarial generation. We, therefore, propose a dual regularization loss (D2R Loss) method and a collaborative adversarial generation (CAG) strategy for adversarial training. D2R loss includes two optimization steps. The adversarial distribution and clean distribution optimizations enhance the target model's robustness by leveraging the strengths of different loss functions obtained via a suitable function space exploration to focus more precisely on the target model's distribution. CAG generates adversarial samples using a gradient-based collaboration between guidance and target models. We conducted extensive experiments on three benchmark databases, including CIFAR-10, CIFAR-100, Tiny ImageNet, and two popular target models, WideResNet34-10 and PreActResNet18. Our results show that D2R loss with CAG produces highly robust models.
VerIPO: Cultivating Long Reasoning in Video-LLMs via Verifier-Gudied Iterative Policy Optimization
May 25, 2025


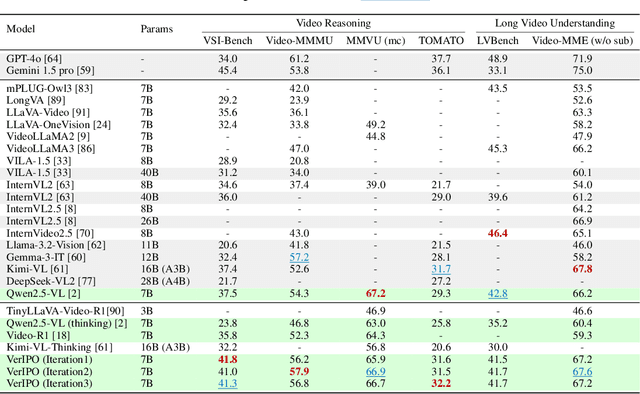
Applying Reinforcement Learning (RL) to Video Large Language Models (Video-LLMs) shows significant promise for complex video reasoning. However, popular Reinforcement Fine-Tuning (RFT) methods, such as outcome-based Group Relative Policy Optimization (GRPO), are limited by data preparation bottlenecks (e.g., noise or high cost) and exhibit unstable improvements in the quality of long chain-of-thoughts (CoTs) and downstream performance.To address these limitations, we propose VerIPO, a Verifier-guided Iterative Policy Optimization method designed to gradually improve video LLMs' capacity for generating deep, long-term reasoning chains. The core component is Rollout-Aware Verifier, positioned between the GRPO and Direct Preference Optimization (DPO) training phases to form the GRPO-Verifier-DPO training loop. This verifier leverages small LLMs as a judge to assess the reasoning logic of rollouts, enabling the construction of high-quality contrastive data, including reflective and contextually consistent CoTs. These curated preference samples drive the efficient DPO stage (7x faster than GRPO), leading to marked improvements in reasoning chain quality, especially in terms of length and contextual consistency. This training loop benefits from GRPO's expansive search and DPO's targeted optimization. Experimental results demonstrate: 1) Significantly faster and more effective optimization compared to standard GRPO variants, yielding superior performance; 2) Our trained models exceed the direct inference of large-scale instruction-tuned Video-LLMs, producing long and contextually consistent CoTs on diverse video reasoning tasks; and 3) Our model with one iteration outperforms powerful LMMs (e.g., Kimi-VL) and long reasoning models (e.g., Video-R1), highlighting its effectiveness and stability.
U2-BENCH: Benchmarking Large Vision-Language Models on Ultrasound Understanding
May 23, 2025Ultrasound is a widely-used imaging modality critical to global healthcare, yet its interpretation remains challenging due to its varying image quality on operators, noises, and anatomical structures. Although large vision-language models (LVLMs) have demonstrated impressive multimodal capabilities across natural and medical domains, their performance on ultrasound remains largely unexplored. We introduce U2-BENCH, the first comprehensive benchmark to evaluate LVLMs on ultrasound understanding across classification, detection, regression, and text generation tasks. U2-BENCH aggregates 7,241 cases spanning 15 anatomical regions and defines 8 clinically inspired tasks, such as diagnosis, view recognition, lesion localization, clinical value estimation, and report generation, across 50 ultrasound application scenarios. We evaluate 20 state-of-the-art LVLMs, both open- and closed-source, general-purpose and medical-specific. Our results reveal strong performance on image-level classification, but persistent challenges in spatial reasoning and clinical language generation. U2-BENCH establishes a rigorous and unified testbed to assess and accelerate LVLM research in the uniquely multimodal domain of medical ultrasound imaging.
Sparse Attention Remapping with Clustering for Efficient LLM Decoding on PIM
May 09, 2025Transformer-based models are the foundation of modern machine learning, but their execution, particularly during autoregressive decoding in large language models (LLMs), places significant pressure on memory systems due to frequent memory accesses and growing key-value (KV) caches. This creates a bottleneck in memory bandwidth, especially as context lengths increase. Processing-in-memory (PIM) architectures are a promising solution, offering high internal bandwidth and compute parallelism near memory. However, current PIM designs are primarily optimized for dense attention and struggle with the dynamic, irregular access patterns introduced by modern KV cache sparsity techniques. Consequently, they suffer from workload imbalance, reducing throughput and resource utilization. In this work, we propose STARC, a novel sparsity-optimized data mapping scheme tailored specifically for efficient LLM decoding on PIM architectures. STARC clusters KV pairs by semantic similarity and maps them to contiguous memory regions aligned with PIM bank structures. During decoding, queries retrieve relevant tokens at cluster granularity by matching against precomputed centroids, enabling selective attention and parallel processing without frequent reclustering or data movement overhead. Experiments on the HBM-PIM system show that, compared to common token-wise sparsity methods, STARC reduces attention-layer latency by 19%--31% and energy consumption by 19%--27%. Under a KV cache budget of 1024, it achieves up to 54%--74% latency reduction and 45%--67% energy reduction compared to full KV cache retrieval. Meanwhile, STARC maintains model accuracy comparable to state-of-the-art sparse attention methods, demonstrating its effectiveness in enabling efficient and hardware-friendly long-context LLM inference on PIM architectures.
Perception, Reason, Think, and Plan: A Survey on Large Multimodal Reasoning Models
May 08, 2025



Reasoning lies at the heart of intelligence, shaping the ability to make decisions, draw conclusions, and generalize across domains. In artificial intelligence, as systems increasingly operate in open, uncertain, and multimodal environments, reasoning becomes essential for enabling robust and adaptive behavior. Large Multimodal Reasoning Models (LMRMs) have emerged as a promising paradigm, integrating modalities such as text, images, audio, and video to support complex reasoning capabilities and aiming to achieve comprehensive perception, precise understanding, and deep reasoning. As research advances, multimodal reasoning has rapidly evolved from modular, perception-driven pipelines to unified, language-centric frameworks that offer more coherent cross-modal understanding. While instruction tuning and reinforcement learning have improved model reasoning, significant challenges remain in omni-modal generalization, reasoning depth, and agentic behavior. To address these issues, we present a comprehensive and structured survey of multimodal reasoning research, organized around a four-stage developmental roadmap that reflects the field's shifting design philosophies and emerging capabilities. First, we review early efforts based on task-specific modules, where reasoning was implicitly embedded across stages of representation, alignment, and fusion. Next, we examine recent approaches that unify reasoning into multimodal LLMs, with advances such as Multimodal Chain-of-Thought (MCoT) and multimodal reinforcement learning enabling richer and more structured reasoning chains. Finally, drawing on empirical insights from challenging benchmarks and experimental cases of OpenAI O3 and O4-mini, we discuss the conceptual direction of native large multimodal reasoning models (N-LMRMs), which aim to support scalable, agentic, and adaptive reasoning and planning in complex, real-world environments.
ResiTok: A Resilient Tokenization-Enabled Framework for Ultra-Low-Rate and Robust Image Transmission
May 03, 2025Real-time transmission of visual data over wireless networks remains highly challenging, even when leveraging advanced deep neural networks, particularly under severe channel conditions such as limited bandwidth and weak connectivity. In this paper, we propose a novel Resilient Tokenization-Enabled (ResiTok) framework designed for ultra-low-rate image transmission that achieves exceptional robustness while maintaining high reconstruction quality. By reorganizing visual information into hierarchical token groups consisting of essential key tokens and supplementary detail tokens, ResiTok enables progressive encoding and graceful degradation of visual quality under constrained channel conditions. A key contribution is our resilient 1D tokenization method integrated with a specialized zero-out training strategy, which systematically simulates token loss during training, empowering the neural network to effectively compress and reconstruct images from incomplete token sets. Furthermore, the channel-adaptive coding and modulation design dynamically allocates coding resources according to prevailing channel conditions, yielding superior semantic fidelity and structural consistency even at extremely low channel bandwidth ratios. Evaluation results demonstrate that ResiTok outperforms state-of-the-art methods in both semantic similarity and visual quality, with significant advantages under challenging channel conditions.
Take Off the Training Wheels Progressive In-Context Learning for Effective Alignment
Mar 13, 2025



Recent studies have explored the working mechanisms of In-Context Learning (ICL). However, they mainly focus on classification and simple generation tasks, limiting their broader application to more complex generation tasks in practice. To address this gap, we investigate the impact of demonstrations on token representations within the practical alignment tasks. We find that the transformer embeds the task function learned from demonstrations into the separator token representation, which plays an important role in the generation of prior response tokens. Once the prior response tokens are determined, the demonstrations become redundant.Motivated by this finding, we propose an efficient Progressive In-Context Alignment (PICA) method consisting of two stages. In the first few-shot stage, the model generates several prior response tokens via standard ICL while concurrently extracting the ICL vector that stores the task function from the separator token representation. In the following zero-shot stage, this ICL vector guides the model to generate responses without further demonstrations.Extensive experiments demonstrate that our PICA not only surpasses vanilla ICL but also achieves comparable performance to other alignment tuning methods. The proposed training-free method reduces the time cost (e.g., 5.45+) with improved alignment performance (e.g., 6.57+). Consequently, our work highlights the application of ICL for alignment and calls for a deeper understanding of ICL for complex generations. The code will be available at https://github.com/HITsz-TMG/PICA.
Picking the Cream of the Crop: Visual-Centric Data Selection with Collaborative Agents
Feb 27, 2025



To improve Multimodal Large Language Models' (MLLMs) ability to process images and complex instructions, researchers predominantly curate large-scale visual instruction tuning datasets, which are either sourced from existing vision tasks or synthetically generated using LLMs and image descriptions. However, they often suffer from critical flaws, including misaligned instruction-image pairs and low-quality images. Such issues hinder training efficiency and limit performance improvements, as models waste resources on noisy or irrelevant data with minimal benefit to overall capability. To address this issue, we propose a \textbf{Vi}sual-Centric \textbf{S}election approach via \textbf{A}gents Collaboration (ViSA), which centers on image quality assessment and image-instruction relevance evaluation. Specifically, our approach consists of 1) an image information quantification method via visual agents collaboration to select images with rich visual information, and 2) a visual-centric instruction quality assessment method to select high-quality instruction data related to high-quality images. Finally, we reorganize 80K instruction data from large open-source datasets. Extensive experiments demonstrate that ViSA outperforms or is comparable to current state-of-the-art models on seven benchmarks, using only 2.5\% of the original data, highlighting the efficiency of our data selection approach. Moreover, we conduct ablation studies to validate the effectiveness of each component of our method. The code is available at https://github.com/HITsz-TMG/ViSA.
Importance-Aware Source-Channel Coding for Multi-Modal Task-Oriented Semantic Communication
Feb 22, 2025This paper explores the concept of information importance in multi-modal task-oriented semantic communication systems, emphasizing the need for high accuracy and efficiency to fulfill task-specific objectives. At the transmitter, generative AI (GenAI) is employed to partition visual data objects into semantic segments, each representing distinct, task-relevant information. These segments are subsequently encoded into tokens, enabling precise and adaptive transmission control. Building on this frame work, we present importance-aware source and channel coding strategies that dynamically adjust to varying levels of significance at the segment, token, and bit levels. The proposed strategies prioritize high fidelity for essential information while permitting controlled distortion for less critical elements, optimizing overall resource utilization. Furthermore, we address the source-channel coding challenge in semantic multiuser systems, particularly in multicast scenarios, where segment importance varies among receivers. To tackle these challenges, we propose solutions such as rate-splitting coded progressive transmission, ensuring flexibility and robustness in task-specific semantic communication.