 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeServing Large Language Models on Huawei CloudMatrix384
Jun 15, 2025



The rapid evolution of large language models (LLMs), driven by growing parameter scales, adoption of mixture-of-experts (MoE) architectures, and expanding context lengths, imposes unprecedented demands on AI infrastructure. Traditional AI clusters face limitations in compute intensity, memory bandwidth, inter-chip communication, and latency, compounded by variable workloads and strict service-level objectives. Addressing these issues requires fundamentally redesigned hardware-software integration. This paper introduces Huawei CloudMatrix, a next-generation AI datacenter architecture, realized in the production-grade CloudMatrix384 supernode. It integrates 384 Ascend 910C NPUs and 192 Kunpeng CPUs interconnected via an ultra-high-bandwidth Unified Bus (UB) network, enabling direct all-to-all communication and dynamic pooling of resources. These features optimize performance for communication-intensive operations, such as large-scale MoE expert parallelism and distributed key-value cache access. To fully leverage CloudMatrix384, we propose CloudMatrix-Infer, an advanced LLM serving solution incorporating three core innovations: a peer-to-peer serving architecture that independently scales prefill, decode, and caching; a large-scale expert parallelism strategy supporting EP320 via efficient UB-based token dispatch; and hardware-aware optimizations including specialized operators, microbatch-based pipelining, and INT8 quantization. Evaluation with the DeepSeek-R1 model shows CloudMatrix-Infer achieves state-of-the-art efficiency: prefill throughput of 6,688 tokens/s per NPU and decode throughput of 1,943 tokens/s per NPU (<50 ms TPOT). It effectively balances throughput and latency, sustaining 538 tokens/s even under stringent 15 ms latency constraints, while INT8 quantization maintains model accuracy across benchmarks.
Look Before You Leap: Safe Model-Based Reinforcement Learning with Human Intervention
Nov 16, 2021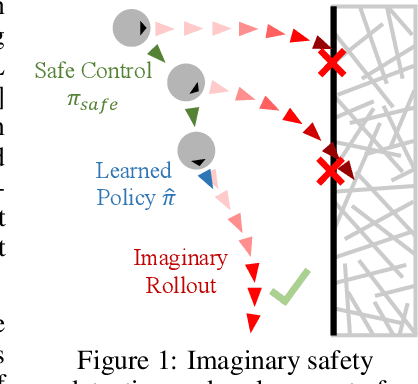
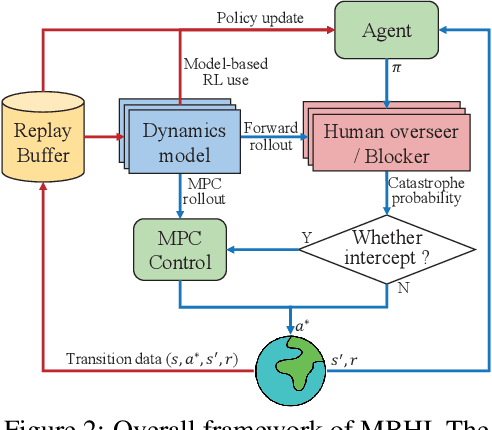
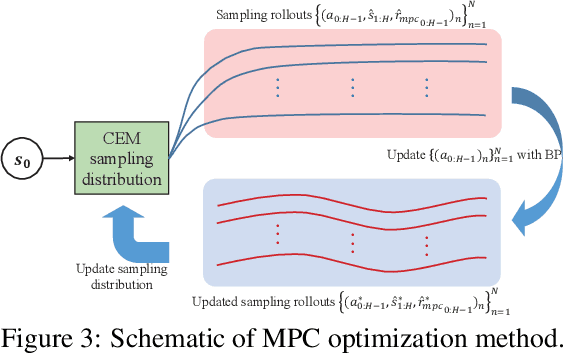
Safety has become one of the main challenges of applying deep reinforcement learning to real world systems. Currently, the incorporation of external knowledge such as human oversight is the only means to prevent the agent from visiting the catastrophic state. In this paper, we propose MBHI, a novel framework for safe model-based reinforcement learning, which ensures safety in the state-level and can effectively avoid both "local" and "non-local" catastrophes. An ensemble of supervised learners are trained in MBHI to imitate human blocking decisions. Similar to human decision-making process, MBHI will roll out an imagined trajectory in the dynamics model before executing actions to the environment, and estimate its safety. When the imagination encounters a catastrophe, MBHI will block the current action and use an efficient MPC method to output a safety policy. We evaluate our method on several safety tasks, and the results show that MBHI achieved better performance in terms of sample efficiency and number of catastrophes compared to the baselines.
SimROD: A Simple Adaptation Method for Robust Object Detection
Jul 28, 2021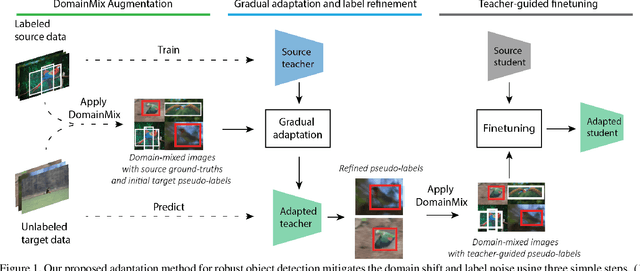
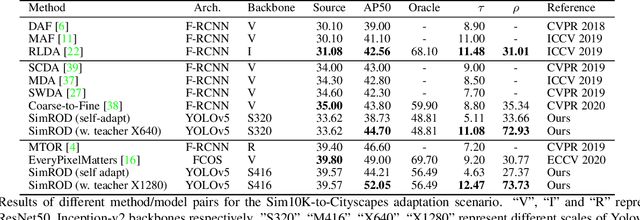

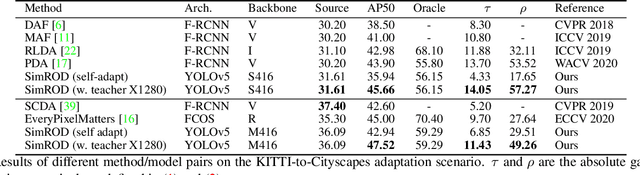
This paper presents a Simple and effective unsupervised adaptation method for Robust Object Detection (SimROD). To overcome the challenging issues of domain shift and pseudo-label noise, our method integrates a novel domain-centric augmentation method, a gradual self-labeling adaptation procedure, and a teacher-guided fine-tuning mechanism. Using our method, target domain samples can be leveraged to adapt object detection models without changing the model architecture or generating synthetic data. When applied to image corruptions and high-level cross-domain adaptation benchmarks, our method outperforms prior baselines on multiple domain adaptation benchmarks. SimROD achieves new state-of-the-art on standard real-to-synthetic and cross-camera setup benchmarks. On the image corruption benchmark, models adapted with our method achieved a relative robustness improvement of 15-25% AP50 on Pascal-C and 5-6% AP on COCO-C and Cityscapes-C. On the cross-domain benchmark, our method outperformed the best baseline performance by up to 8% AP50 on Comic dataset and up to 4% on Watercolor dataset.
Privacy Loss in Apple's Implementation of Differential Privacy on MacOS 10.12
Sep 11, 2017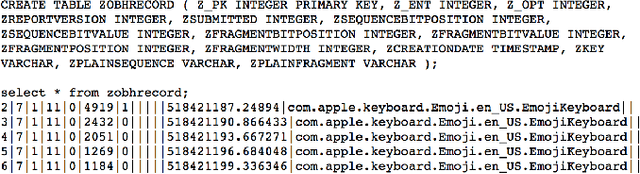
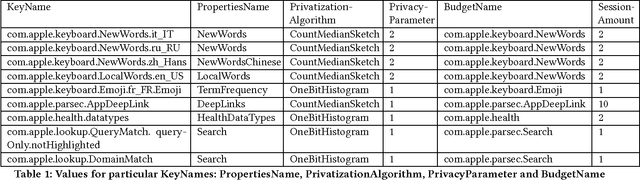
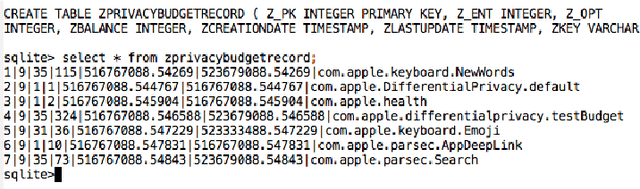
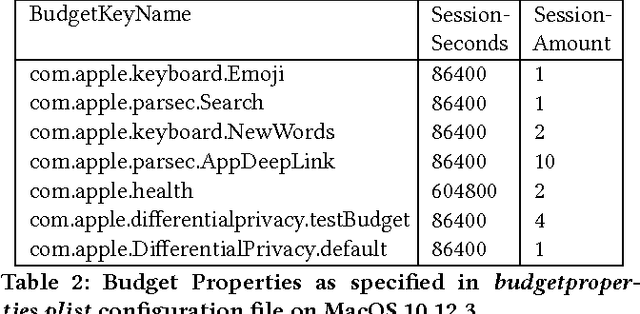
In June 2016, Apple announced that it will deploy differential privacy for some user data collection in order to ensure privacy of user data, even from Apple. The details of Apple's approach remained sparse. Although several patents have since appeared hinting at the algorithms that may be used to achieve differential privacy, they did not include a precise explanation of the approach taken to privacy parameter choice. Such choice and the overall approach to privacy budget use and management are key questions for understanding the privacy protections provided by any deployment of differential privacy. In this work, through a combination of experiments, static and dynamic code analysis of macOS Sierra (Version 10.12) implementation, we shed light on the choices Apple made for privacy budget management. We discover and describe Apple's set-up for differentially private data processing, including the overall data pipeline, the parameters used for differentially private perturbation of each piece of data, and the frequency with which such data is sent to Apple's servers. We find that although Apple's deployment ensures that the (differential) privacy loss per each datum submitted to its servers is $1$ or $2$, the overall privacy loss permitted by the system is significantly higher, as high as $16$ per day for the four initially announced applications of Emojis, New words, Deeplinks and Lookup Hints. Furthermore, Apple renews the privacy budget available every day, which leads to a possible privacy loss of 16 times the number of days since user opt-in to differentially private data collection for those four applications. We advocate that in order to claim the full benefits of differentially private data collection, Apple must give full transparency of its implementation, enable user choice in areas related to privacy loss, and set meaningful defaults on the privacy loss permitted.