 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHalf-Truth: A Partially Fake Audio Detection Dataset
Apr 08, 2021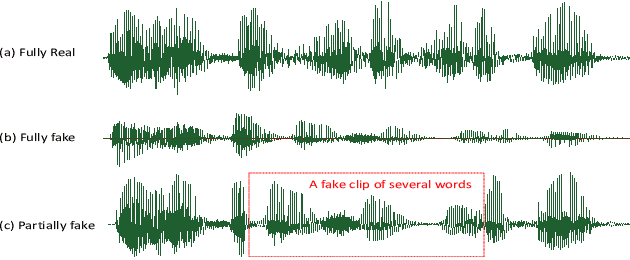
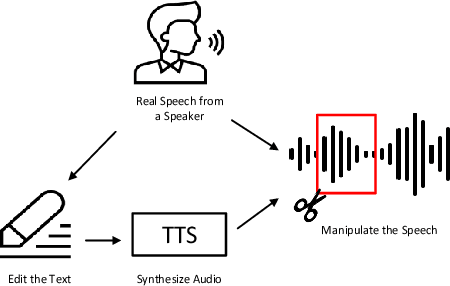
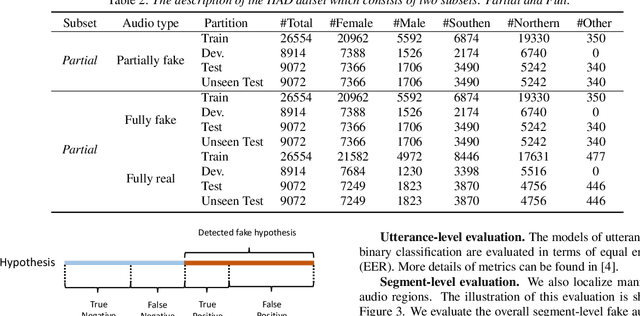
Diverse promising datasets have been designed to hold back the development of fake audio detection, such as ASVspoof databases. However, previous datasets ignore an attacking situation, in which the hacker hides some small fake clips in real speech audio. This poses a serious threat since that it is difficult to distinguish the small fake clip from the whole speech utterance. Therefore, this paper develops such a dataset for half-truth audio detection (HAD). Partially fake audio in the HAD dataset involves only changing a few words in an utterance.The audio of the words is generated with the very latest state-of-the-art speech synthesis technology. We can not only detect fake uttrances but also localize manipulated regions in a speech using this dataset. Some benchmark results are presented on this dataset. The results show that partially fake audio presents much more challenging than fully fake audio for fake audio detection.
FSR: Accelerating the Inference Process of Transducer-Based Models by Applying Fast-Skip Regularization
Apr 07, 2021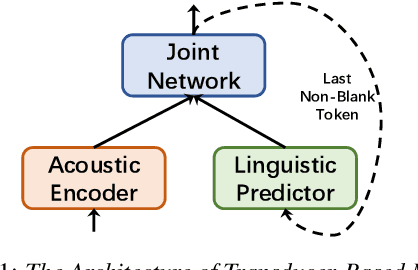
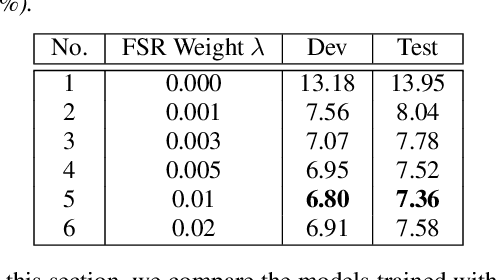
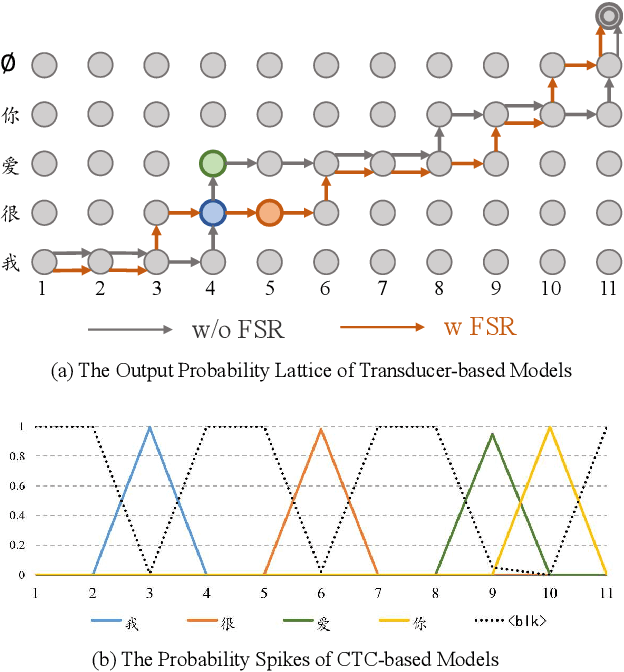

Transducer-based models, such as RNN-Transducer and transformer-transducer, have achieved great success in speech recognition. A typical transducer model decodes the output sequence conditioned on the current acoustic state and previously predicted tokens step by step. Statistically, The number of blank tokens in the prediction results accounts for nearly 90\% of all tokens. It takes a lot of computation and time to predict the blank tokens, but only the non-blank tokens will appear in the final output sequence. Therefore, we propose a method named fast-skip regularization, which tries to align the blank position predicted by a transducer with that predicted by a CTC model. During the inference, the transducer model can predict the blank tokens in advance by a simple CTC project layer without many complicated forward calculations of the transducer decoder and then skip them, which will reduce the computation and improve the inference speed greatly. All experiments are conducted on a public Chinese mandarin dataset AISHELL-1. The results show that the fast-skip regularization can indeed help the transducer model learn the blank position alignments. Besides, the inference with fast-skip can be speeded up nearly 4 times with only a little performance degradation.
TSNAT: Two-Step Non-Autoregressvie Transformer Models for Speech Recognition
Apr 04, 2021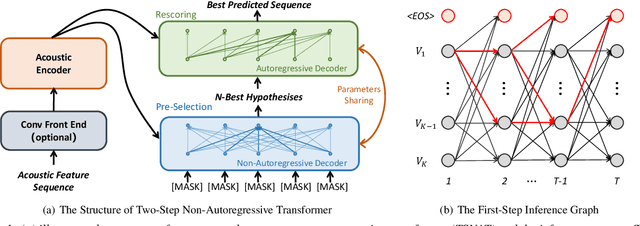
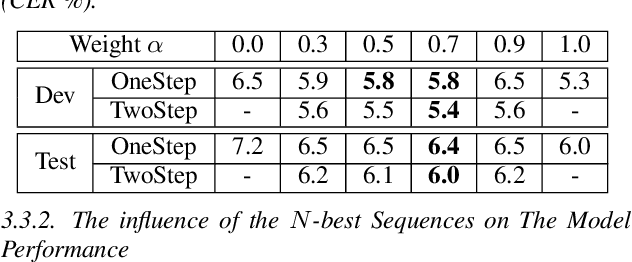
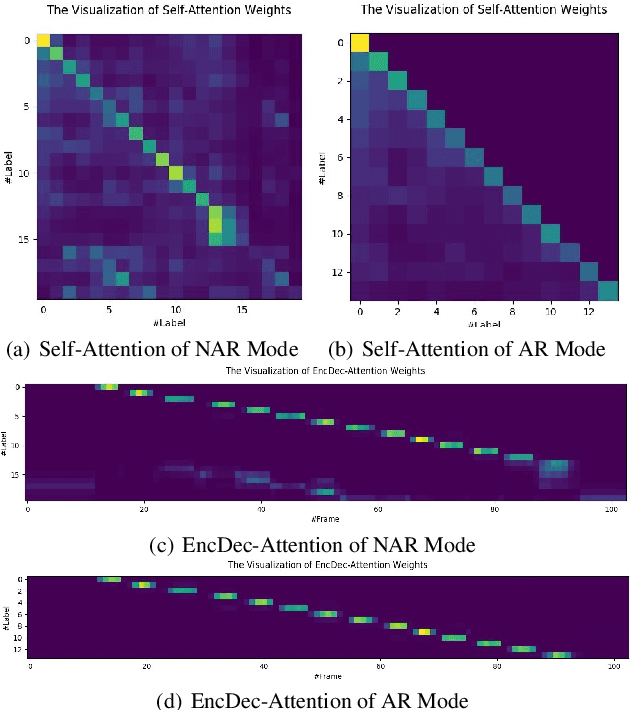
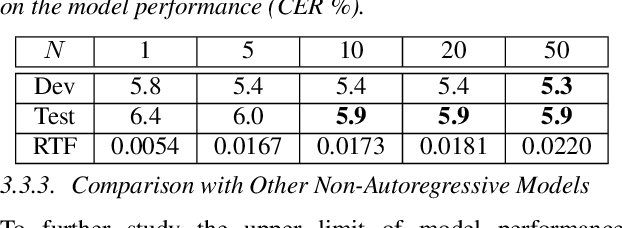
The autoregressive (AR) models, such as attention-based encoder-decoder models and RNN-Transducer, have achieved great success in speech recognition. They predict the output sequence conditioned on the previous tokens and acoustic encoded states, which is inefficient on GPUs. The non-autoregressive (NAR) models can get rid of the temporal dependency between the output tokens and predict the entire output tokens in at least one step. However, the NAR model still faces two major problems. On the one hand, there is still a great gap in performance between the NAR models and the advanced AR models. On the other hand, it's difficult for most of the NAR models to train and converge. To address these two problems, we propose a new model named the two-step non-autoregressive transformer(TSNAT), which improves the performance and accelerating the convergence of the NAR model by learning prior knowledge from a parameters-sharing AR model. Furthermore, we introduce the two-stage method into the inference process, which improves the model performance greatly. All the experiments are conducted on a public Chinese mandarin dataset ASIEHLL-1. The results show that the TSNAT can achieve a competitive performance with the AR model and outperform many complicated NAR models.
Fast End-to-End Speech Recognition via a Non-Autoregressive Model and Cross-Modal Knowledge Transferring from BERT
Feb 20, 2021
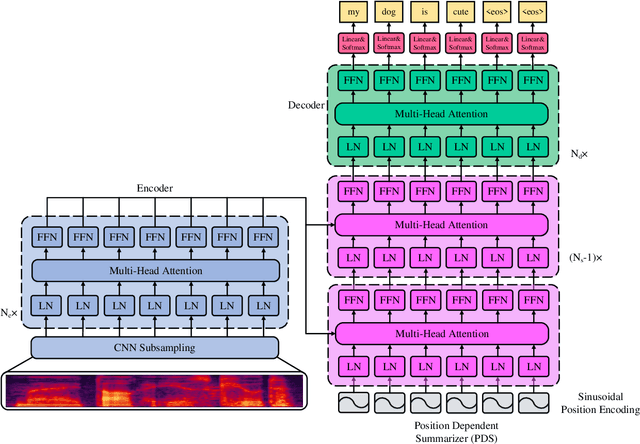
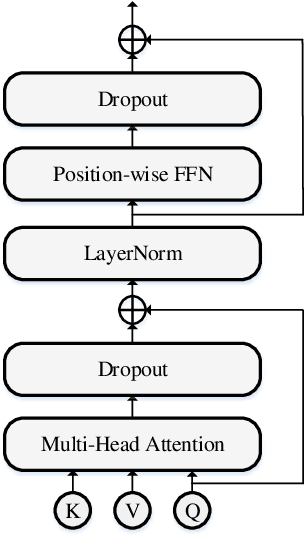
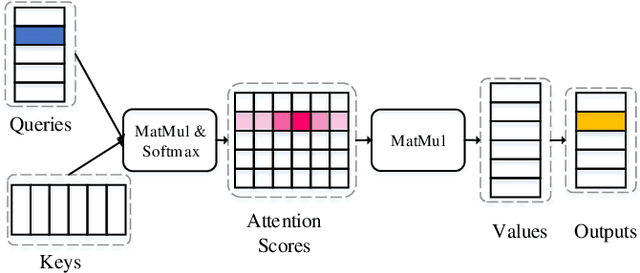
Attention-based encoder-decoder (AED) models have achieved promising performance in speech recognition. However, because the decoder predicts text tokens (such as characters or words) in an autoregressive manner, it is difficult for an AED model to predict all tokens in parallel. This makes the inference speed relatively slow. We believe that because the encoder already captures the whole speech utterance, which has the token-level relationship implicitly, we can predict a token without explicitly autoregressive language modeling. When the prediction of a token does not rely on other tokens, the parallel prediction of all tokens in the sequence is realizable. Based on this idea, we propose a non-autoregressive speech recognition model called LASO (Listen Attentively, and Spell Once). The model consists of an encoder, a decoder, and a position dependent summarizer (PDS). The three modules are based on basic attention blocks. The encoder extracts high-level representations from the speech. The PDS uses positional encodings corresponding to tokens to convert the acoustic representations into token-level representations. The decoder further captures token-level relationships with the self-attention mechanism. At last, the probability distribution on the vocabulary is computed for each token position. Therefore, speech recognition is re-formulated as a position-wise classification problem. Further, we propose a cross-modal transfer learning method to refine semantics from a large-scale pre-trained language model BERT for improving the performance.
Gated Recurrent Fusion with Joint Training Framework for Robust End-to-End Speech Recognition
Nov 09, 2020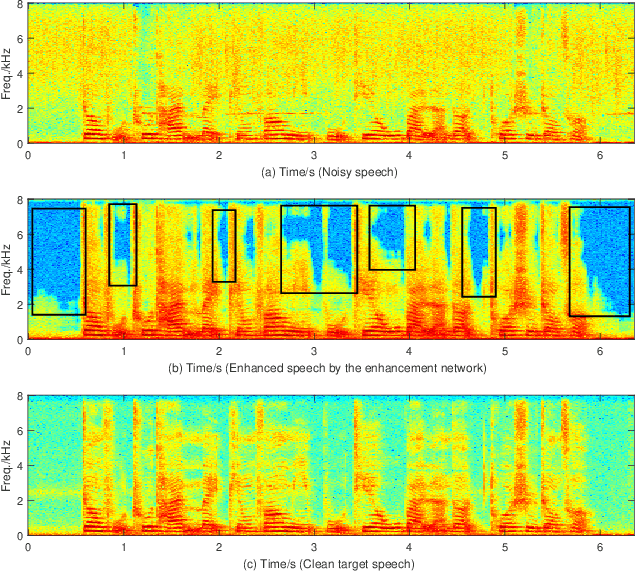
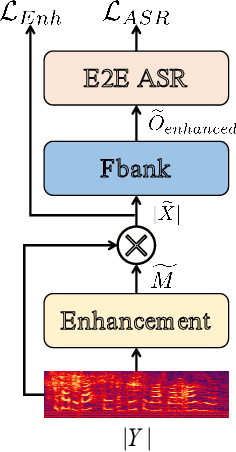
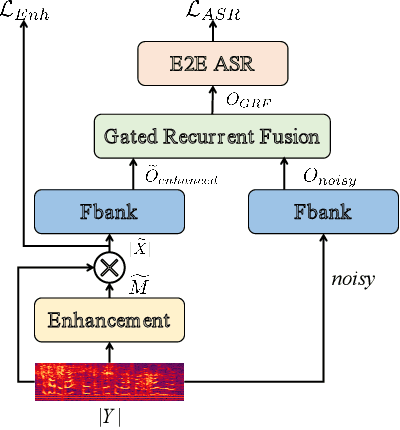
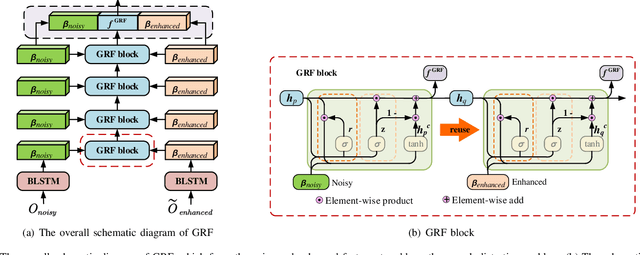
The joint training framework for speech enhancement and recognition methods have obtained quite good performances for robust end-to-end automatic speech recognition (ASR). However, these methods only utilize the enhanced feature as the input of the speech recognition component, which are affected by the speech distortion problem. In order to address this problem, this paper proposes a gated recurrent fusion (GRF) method with joint training framework for robust end-to-end ASR. The GRF algorithm is used to dynamically combine the noisy and enhanced features. Therefore, the GRF can not only remove the noise signals from the enhanced features, but also learn the raw fine structures from the noisy features so that it can alleviate the speech distortion. The proposed method consists of speech enhancement, GRF and speech recognition. Firstly, the mask based speech enhancement network is applied to enhance the input speech. Secondly, the GRF is applied to address the speech distortion problem. Thirdly, to improve the performance of ASR, the state-of-the-art speech transformer algorithm is used as the speech recognition component. Finally, the joint training framework is utilized to optimize these three components, simultaneously. Our experiments are conducted on an open-source Mandarin speech corpus called AISHELL-1. Experimental results show that the proposed method achieves the relative character error rate (CER) reduction of 10.04\% over the conventional joint enhancement and transformer method only using the enhanced features. Especially for the low signal-to-noise ratio (0 dB), our proposed method can achieves better performances with 12.67\% CER reduction, which suggests the potential of our proposed method.
Decoupling Pronunciation and Language for End-to-end Code-switching Automatic Speech Recognition
Oct 28, 2020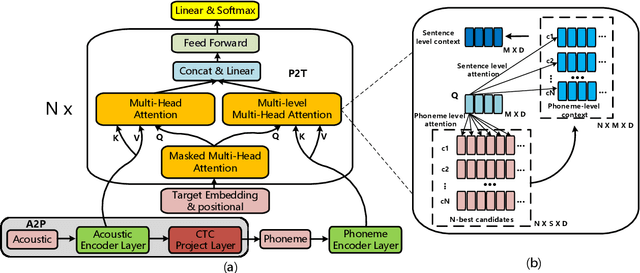
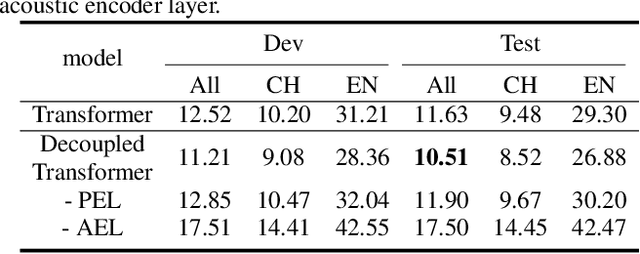
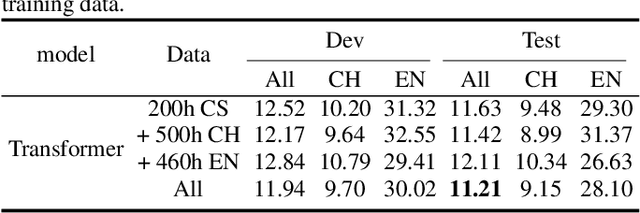
Despite the recent significant advances witnessed in end-to-end (E2E) ASR system for code-switching, hunger for audio-text paired data limits the further improvement of the models' performance. In this paper, we propose a decoupled transformer model to use monolingual paired data and unpaired text data to alleviate the problem of code-switching data shortage. The model is decoupled into two parts: audio-to-phoneme (A2P) network and phoneme-to-text (P2T) network. The A2P network can learn acoustic pattern scenarios using large-scale monolingual paired data. Meanwhile, it generates multiple phoneme sequence candidates for single audio data in real-time during the training process. Then the generated phoneme-text paired data is used to train the P2T network. This network can be pre-trained with large amounts of external unpaired text data. By using monolingual data and unpaired text data, the decoupled transformer model reduces the high dependency on code-switching paired training data of E2E model to a certain extent. Finally, the two networks are optimized jointly through attention fusion. We evaluate the proposed method on the public Mandarin-English code-switching dataset. Compared with our transformer baseline, the proposed method achieves 18.14% relative mix error rate reduction.
Listen Attentively, and Spell Once: Whole Sentence Generation via a Non-Autoregressive Architecture for Low-Latency Speech Recognition
May 30, 2020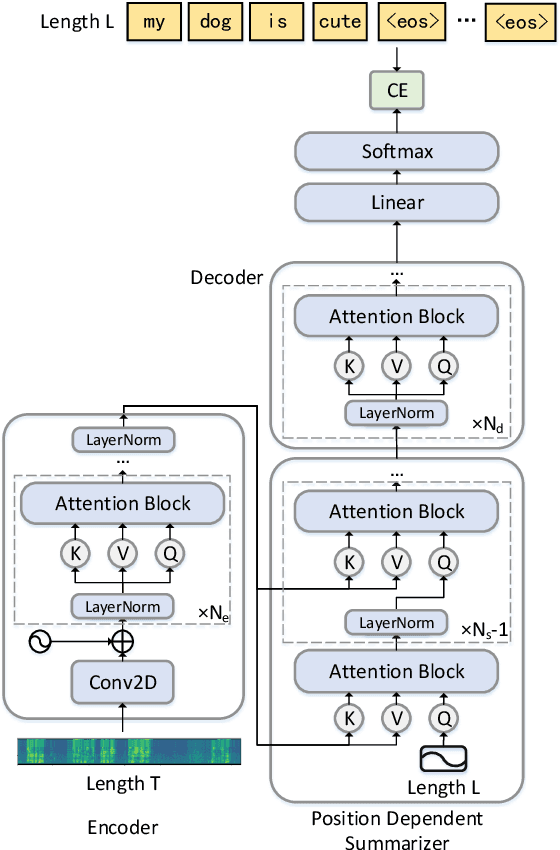
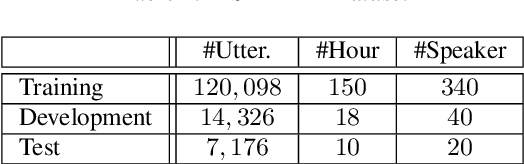
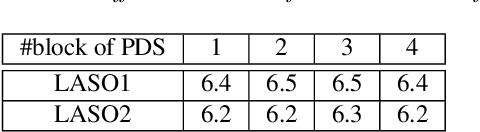
Although attention based end-to-end models have achieved promising performance in speech recognition, the multi-pass forward computation in beam-search increases inference time cost, which limits their practical applications. To address this issue, we propose a non-autoregressive end-to-end speech recognition system called LASO (listen attentively, and spell once). Because of the non-autoregressive property, LASO predicts a textual token in the sequence without the dependence on other tokens. Without beam-search, the one-pass propagation much reduces inference time cost of LASO. And because the model is based on the attention based feedforward structure, the computation can be implemented in parallel efficiently. We conduct experiments on publicly available Chinese dataset AISHELL-1. LASO achieves a character error rate of 6.4%, which outperforms the state-of-the-art autoregressive transformer model (6.7%). The average inference latency is 21 ms, which is 1/50 of the autoregressive transformer model.
Spike-Triggered Non-Autoregressive Transformer for End-to-End Speech Recognition
May 16, 2020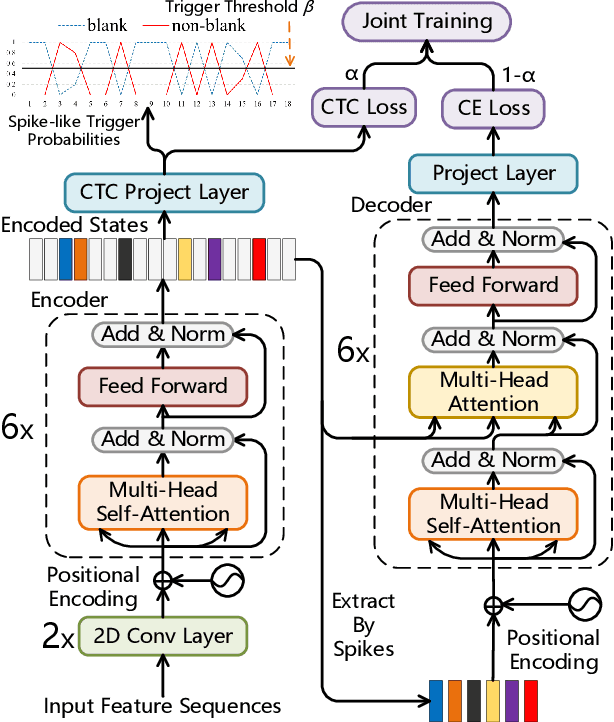
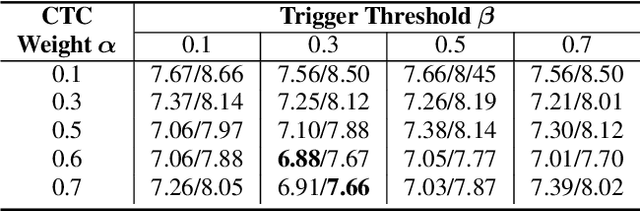
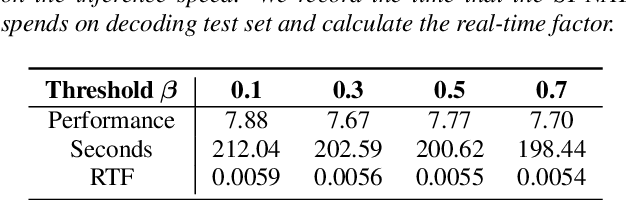
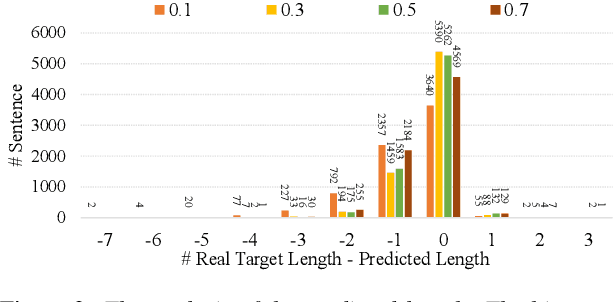
Non-autoregressive transformer models have achieved extremely fast inference speed and comparable performance with autoregressive sequence-to-sequence models in neural machine translation. Most of the non-autoregressive transformers decode the target sequence from a predefined-length mask sequence. If the predefined length is too long, it will cause a lot of redundant calculations. If the predefined length is shorter than the length of the target sequence, it will hurt the performance of the model. To address this problem and improve the inference speed, we propose a spike-triggered non-autoregressive transformer model for end-to-end speech recognition, which introduces a CTC module to predict the length of the target sequence and accelerate the convergence. All the experiments are conducted on a public Chinese mandarin dataset AISHELL-1. The results show that the proposed model can accurately predict the length of the target sequence and achieve a competitive performance with the advanced transformers. What's more, the model even achieves a real-time factor of 0.0056, which exceeds all mainstream speech recognition models.
Adversarial Transfer Learning for Punctuation Restoration
Apr 01, 2020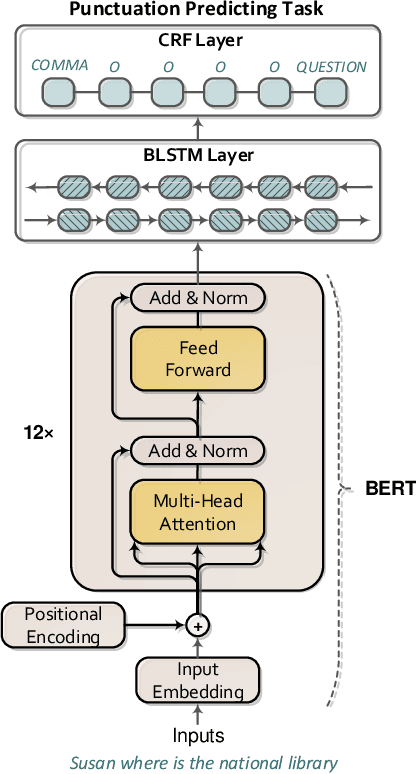
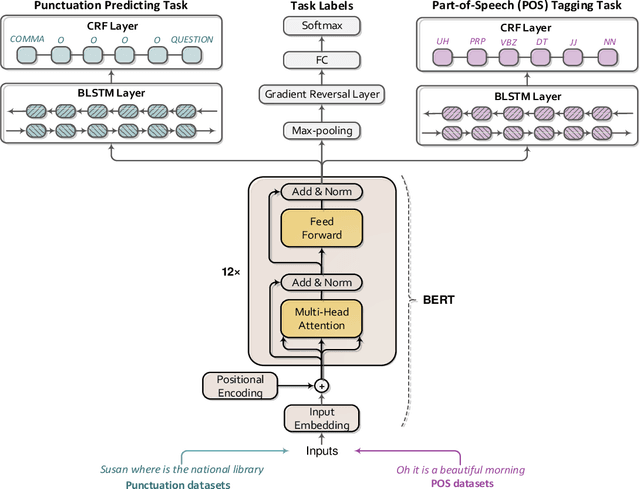
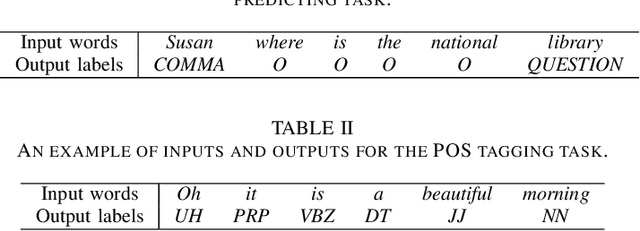

Previous studies demonstrate that word embeddings and part-of-speech (POS) tags are helpful for punctuation restoration tasks. However, two drawbacks still exist. One is that word embeddings are pre-trained by unidirectional language modeling objectives. Thus the word embeddings only contain left-to-right context information. The other is that POS tags are provided by an external POS tagger. So computation cost will be increased and incorrect predicted tags may affect the performance of restoring punctuation marks during decoding. This paper proposes adversarial transfer learning to address these problems. A pre-trained bidirectional encoder representations from transformers (BERT) model is used to initialize a punctuation model. Thus the transferred model parameters carry both left-to-right and right-to-left representations. Furthermore, adversarial multi-task learning is introduced to learn task invariant knowledge for punctuation prediction. We use an extra POS tagging task to help the training of the punctuation predicting task. Adversarial training is utilized to prevent the shared parameters from containing task specific information. We only use the punctuation predicting task to restore marks during decoding stage. Therefore, it will not need extra computation and not introduce incorrect tags from the POS tagger. Experiments are conducted on IWSLT2011 datasets. The results demonstrate that the punctuation predicting models obtain further performance improvement with task invariant knowledge from the POS tagging task. Our best model outperforms the previous state-of-the-art model trained only with lexical features by up to 9.2% absolute overall F_1-score on test set.
Rnn-transducer with language bias for end-to-end Mandarin-English code-switching speech recognition
Feb 19, 2020
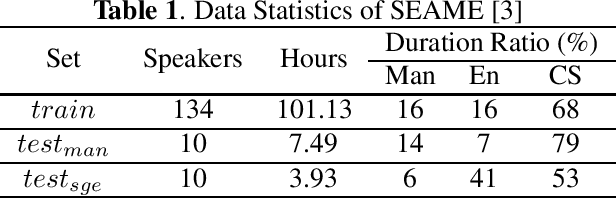
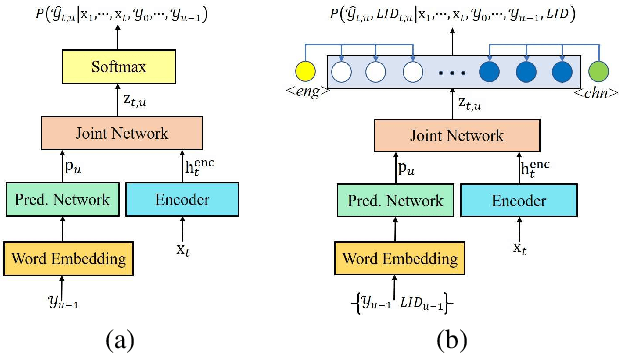
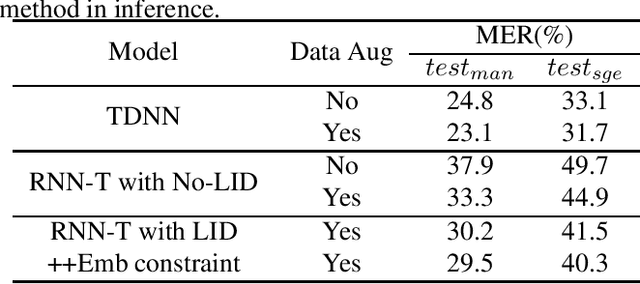
Recently, language identity information has been utilized to improve the performance of end-to-end code-switching (CS) speech recognition. However, previous works use an additional language identification (LID) model as an auxiliary module, which causes the system complex. In this work, we propose an improved recurrent neural network transducer (RNN-T) model with language bias to alleviate the problem. We use the language identities to bias the model to predict the CS points. This promotes the model to learn the language identity information directly from transcription, and no additional LID model is needed. We evaluate the approach on a Mandarin-English CS corpus SEAME. Compared to our RNN-T baseline, the proposed method can achieve 16.2% and 12.9% relative error reduction on two test sets, respectively.