 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSMI: Fast computation of Shannon Mutual Information for information-theoretic mapping
May 06, 2019
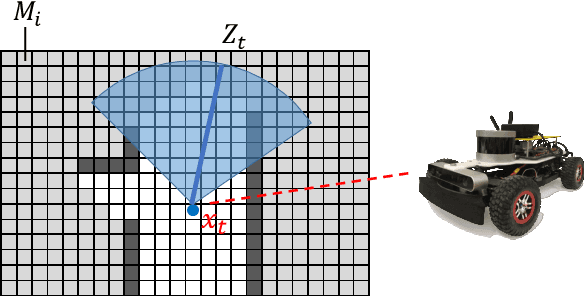
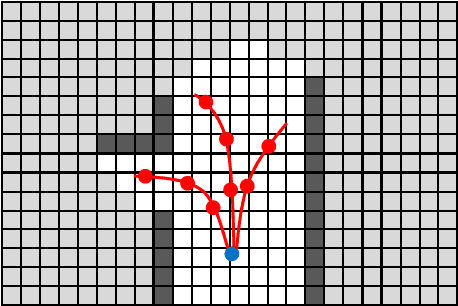

Exploration tasks are embedded in many robotics applications, such as search and rescue and space exploration. Information-based exploration algorithms aim to find the most informative trajectories by maximizing an information-theoretic metric, such as the mutual information between the map and potential future measurements. Unfortunately, most existing information-based exploration algorithms are plagued by the computational difficulty of evaluating the Shannon mutual information metric. In this paper, we consider the fundamental problem of evaluating Shannon mutual information between the map and a range measurement. First, we consider 2D environments. We propose a novel algorithm, called the Fast Shannon Mutual Information (FSMI). The key insight behind the algorithm is that a certain integral can be computed analytically, leading to substantial computational savings. Second, we consider 3D environments, represented by efficient data structures, e.g., an OctoMap, such that the measurements are compressed by Run-Length Encoding (RLE). We propose a novel algorithm, called FSMI-RLE, that efficiently evaluates the Shannon mutual information when the measurements are compressed using RLE. For both the FSMI and the FSMI-RLE, we also propose variants that make different assumptions on the sensor noise distribution for the purpose of further computational savings. We evaluate the proposed algorithms in extensive experiments. In particular, we show that the proposed algorithms outperform existing algorithms that compute Shannon mutual information as well as other algorithms that compute the Cauchy-Schwarz Quadratic mutual information (CSQMI). In addition, we demonstrate the computation of Shannon mutual information on a 3D map for the first time.
Navion: A 2mW Fully Integrated Real-Time Visual-Inertial Odometry Accelerator for Autonomous Navigation of Nano Drones
Sep 15, 2018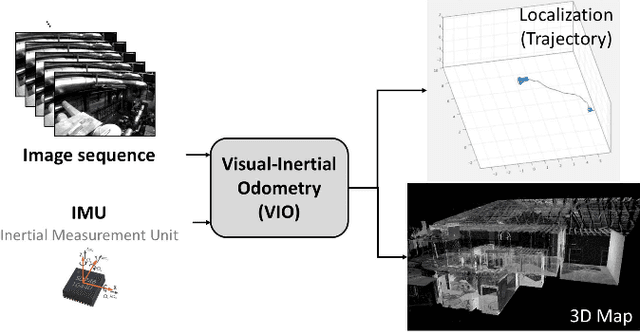
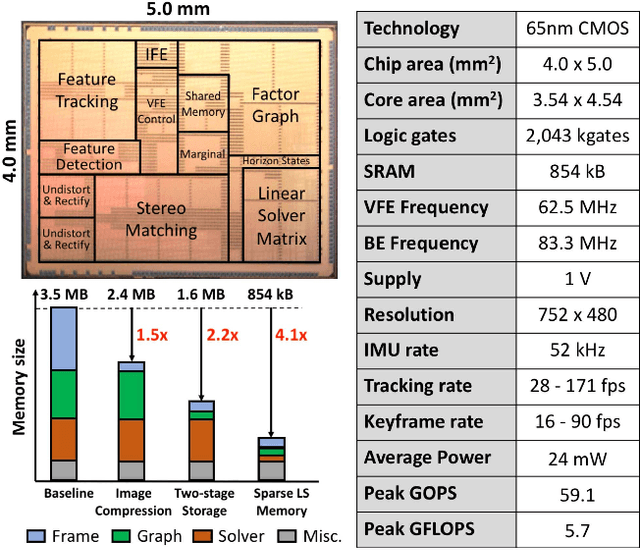
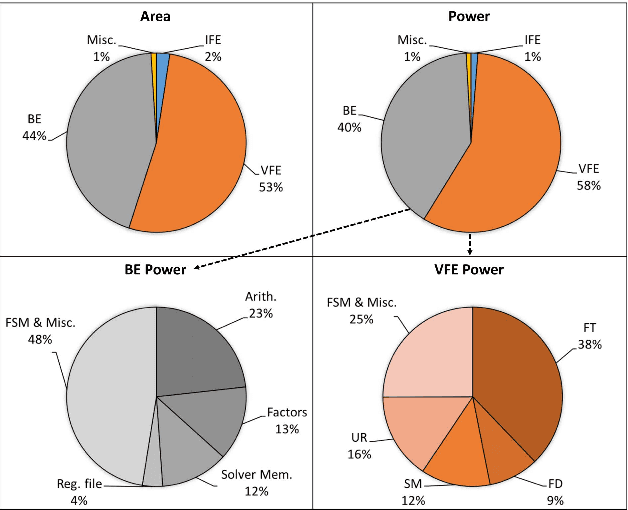
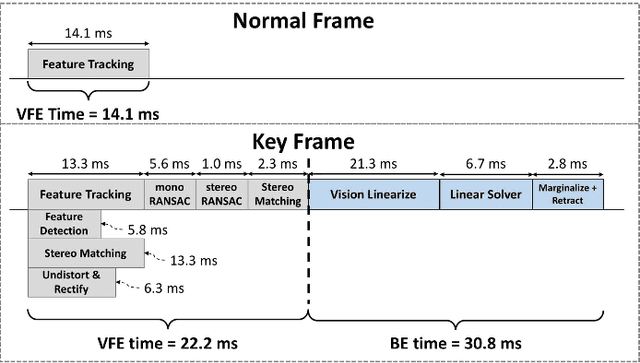
This paper presents Navion, an energy-efficient accelerator for visual-inertial odometry (VIO) that enables autonomous navigation of miniaturized robots (e.g., nano drones), and virtual/augmented reality on portable devices. The chip uses inertial measurements and mono/stereo images to estimate the drone's trajectory and a 3D map of the environment. This estimate is obtained by running a state-of-the-art VIO algorithm based on non-linear factor graph optimization, which requires large irregularly structured memories and heterogeneous computation flow. To reduce the energy consumption and footprint, the entire VIO system is fully integrated on chip to eliminate costly off-chip processing and storage. This work uses compression and exploits both structured and unstructured sparsity to reduce on-chip memory size by 4.1$\times$. Parallelism is used under tight area constraints to increase throughput by 43%. The chip is fabricated in 65nm CMOS, and can process 752$\times$480 stereo images from EuRoC dataset in real-time at 20 frames per second (fps) consuming only an average power of 2mW. At its peak performance, Navion can process stereo images at up to 171 fps and inertial measurements at up to 52 kHz, while consuming an average of 24mW. The chip is configurable to maximize accuracy, throughput and energy-efficiency trade-offs and to adapt to different environments. To the best of our knowledge, this is the first fully integrated VIO system in an ASIC.
Hardware for Machine Learning: Challenges and Opportunities
Oct 17, 2017
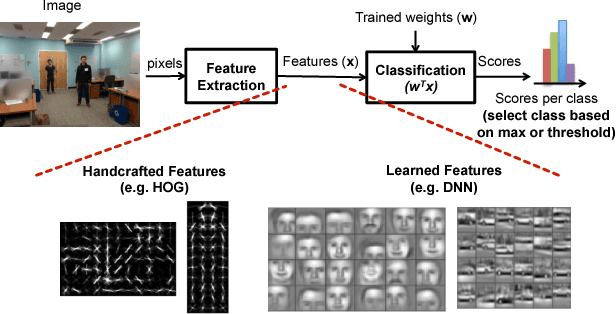
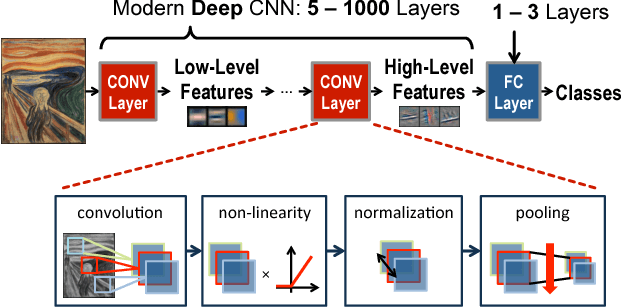
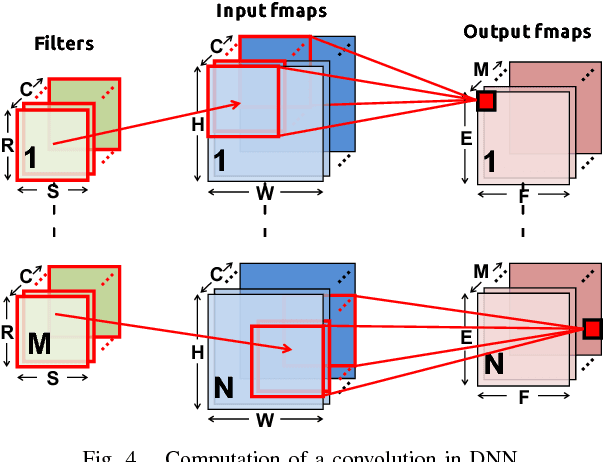
Machine learning plays a critical role in extracting meaningful information out of the zetabytes of sensor data collected every day. For some applications, the goal is to analyze and understand the data to identify trends (e.g., surveillance, portable/wearable electronics); in other applications, the goal is to take immediate action based the data (e.g., robotics/drones, self-driving cars, smart Internet of Things). For many of these applications, local embedded processing near the sensor is preferred over the cloud due to privacy or latency concerns, or limitations in the communication bandwidth. However, at the sensor there are often stringent constraints on energy consumption and cost in addition to throughput and accuracy requirements. Furthermore, flexibility is often required such that the processing can be adapted for different applications or environments (e.g., update the weights and model in the classifier). In many applications, machine learning often involves transforming the input data into a higher dimensional space, which, along with programmable weights, increases data movement and consequently energy consumption. In this paper, we will discuss how these challenges can be addressed at various levels of hardware design ranging from architecture, hardware-friendly algorithms, mixed-signal circuits, and advanced technologies (including memories and sensors).
FAST: A Framework to Accelerate Super-Resolution Processing on Compressed Videos
Aug 04, 2017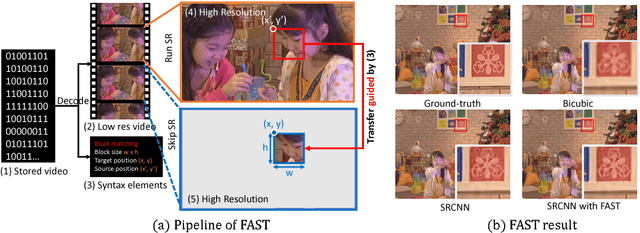
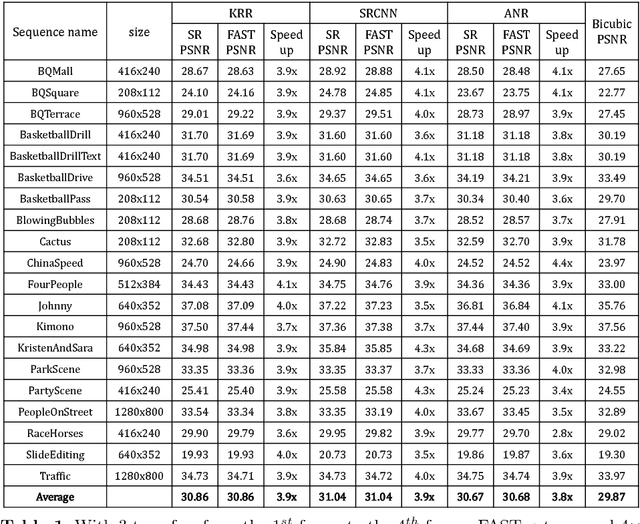
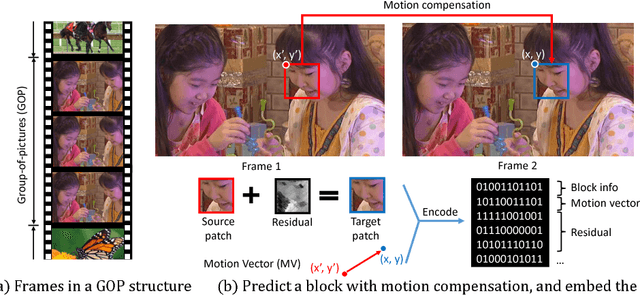
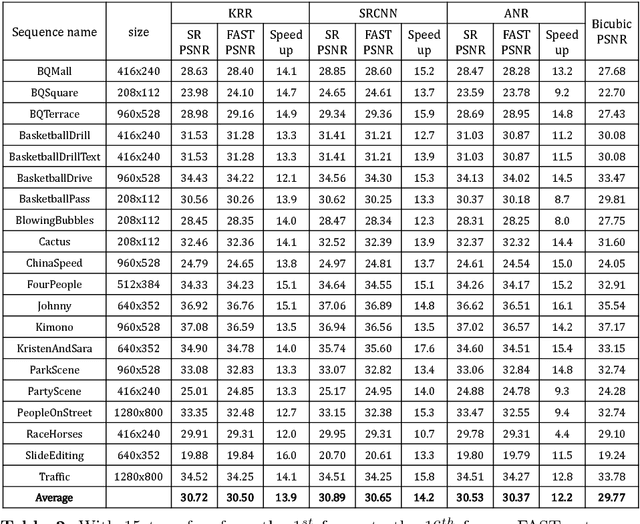
State-of-the-art super-resolution (SR) algorithms require significant computational resources to achieve real-time throughput (e.g., 60Mpixels/s for HD video). This paper introduces FAST (Free Adaptive Super-resolution via Transfer), a framework to accelerate any SR algorithm applied to compressed videos. FAST exploits the temporal correlation between adjacent frames such that SR is only applied to a subset of frames; SR pixels are then transferred to the other frames. The transferring process has negligible computation cost as it uses information already embedded in the compressed video (e.g., motion vectors and residual). Adaptive processing is used to retain accuracy when the temporal correlation is not present (e.g., occlusions). FAST accelerates state-of-the-art SR algorithms by up to 15x with a visual quality loss of 0.2dB. FAST is an important step towards real-time SR algorithms for ultra-HD displays and energy constrained devices (e.g., phones and tablets).
A 58.6mW Real-Time Programmable Object Detector with Multi-Scale Multi-Object Support Using Deformable Parts Model on 1920x1080 Video at 30fps
Jul 27, 2016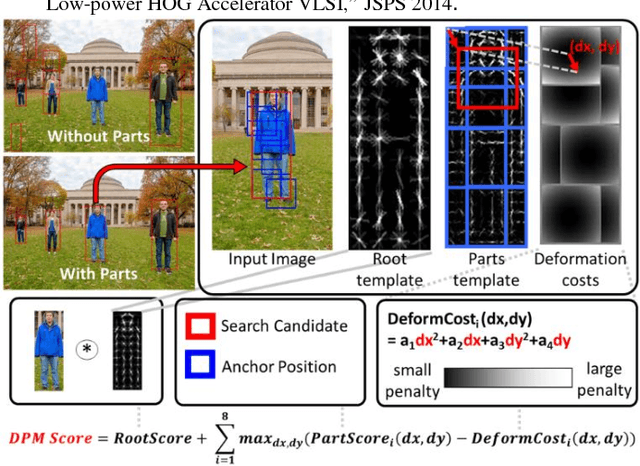
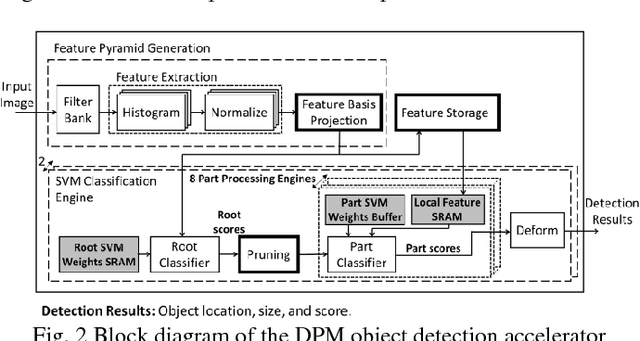
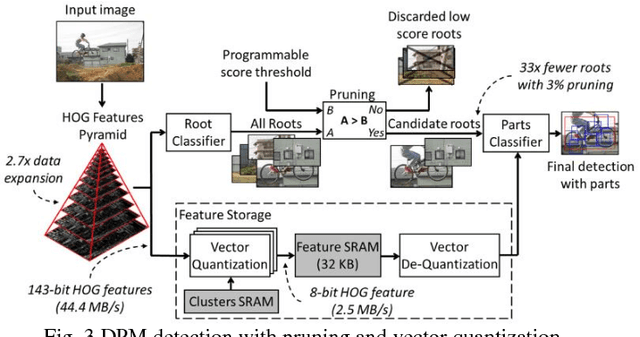
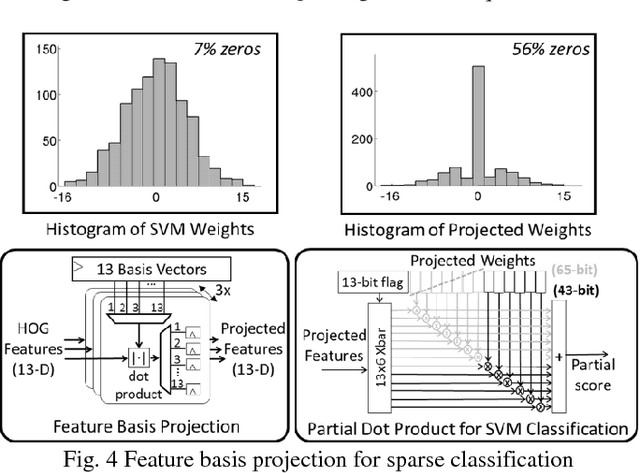
This paper presents a programmable, energy-efficient and real-time object detection accelerator using deformable parts models (DPM), with 2x higher accuracy than traditional rigid body models. With 8 deformable parts detection, three methods are used to address the high computational complexity: classification pruning for 33x fewer parts classification, vector quantization for 15x memory size reduction, and feature basis projection for 2x reduction of the cost of each classification. The chip is implemented in 65nm CMOS technology, and can process HD (1920x1080) images at 30fps without any off-chip storage while consuming only 58.6mW (0.94nJ/pixel, 1168 GOPS/W). The chip has two classification engines to simultaneously detect two different classes of objects. With a tested high throughput of 60fps, the classification engines can be time multiplexed to detect even more than two object classes. It is energy scalable by changing the pruning factor or disabling the parts classification.
Sparkle Vision: Seeing the World through Random Specular Microfacets
Dec 26, 2014

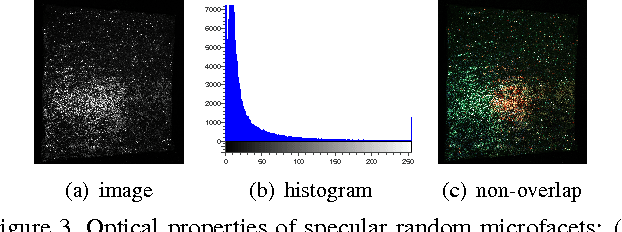
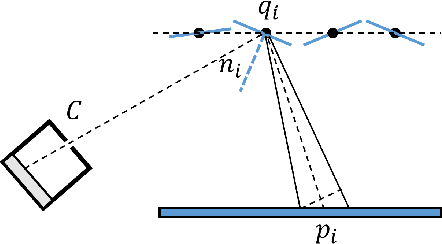
In this paper, we study the problem of reproducing the world lighting from a single image of an object covered with random specular microfacets on the surface. We show that such reflectors can be interpreted as a randomized mapping from the lighting to the image. Such specular objects have very different optical properties from both diffuse surfaces and smooth specular objects like metals, so we design special imaging system to robustly and effectively photograph them. We present simple yet reliable algorithms to calibrate the proposed system and do the inference. We conduct experiments to verify the correctness of our model assumptions and prove the effectiveness of our pipeline.
TILT: Transform Invariant Low-rank Textures
Dec 15, 2010
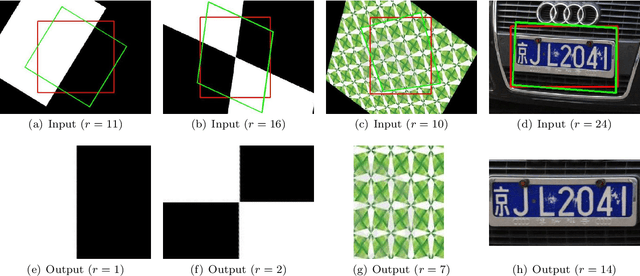

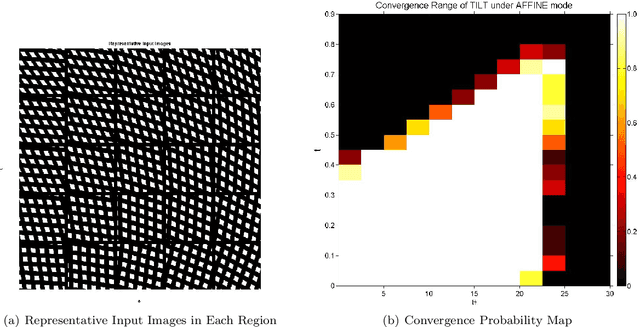
In this paper, we show how to efficiently and effectively extract a class of "low-rank textures" in a 3D scene from 2D images despite significant corruptions and warping. The low-rank textures capture geometrically meaningful structures in an image, which encompass conventional local features such as edges and corners as well as all kinds of regular, symmetric patterns ubiquitous in urban environments and man-made objects. Our approach to finding these low-rank textures leverages the recent breakthroughs in convex optimization that enable robust recovery of a high-dimensional low-rank matrix despite gross sparse errors. In the case of planar regions with significant affine or projective deformation, our method can accurately recover both the intrinsic low-rank texture and the precise domain transformation, and hence the 3D geometry and appearance of the planar regions. Extensive experimental results demonstrate that this new technique works effectively for many regular and near-regular patterns or objects that are approximately low-rank, such as symmetrical patterns, building facades, printed texts, and human faces.