 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperDFlash: MHC-Aligned Block Speculative Decoding with Gated Residual Reduction
Jun 25, 2026We present HyperDFlash, a block-parallel speculative decoding framework tailored to the novel multi-hyper-connection (MHC) architecture proposed by DeepSeek-V4. Despite the strong initial-token drafting performance of the native Multi-Token Prediction (MTP) module in DeepSeek-V4, its draft accuracy degrades sharply at later positions, as error accumulation from unverified intermediate tokens harms acceptance rates. Although the original DFlash method supports efficient one-pass block drafting, it cannot be seamlessly adapted to the MHC paradigm, since the multi-path residual stream of DeepSeek-V4 induces feature misalignment with conventional drafting designs. To resolve this mismatch, we propose two model-aligned optimizations for MHC residual streams. First, we adopt pre-collapse residual states as the exclusive conditioning signal, preserving multi-path structural information and aligning the drafter with the native prediction pathway of the target model. Second, we replace the heavy generic linear compressor with a lightweight gated residual reducer, whose parameters are inherited from the built-in hyper-connection head. This design yields input-aware path aggregation with three orders of magnitude fewer parameters while maintaining architectural alignment. We further enhance training via a targeted KL distillation loss applied to the LM-head, which regularizes predictions against the full target probability distribution and improves draft quality at early training stages. Experiments across math reasoning, code synthesis, and conversational benchmarks show that HyperDFlash consistently outperforms both the native MTP baseline and vanilla DFlash adaptation. It achieves substantial gains in average accepted draft length and decoding speedup, validating the effectiveness of MHC alignment, gated reduction, and targeted distillation for high-performance speculative decoding.
Augmented Space Linear Model
Feb 02, 2018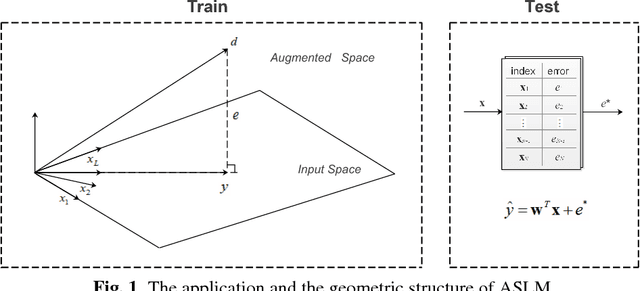
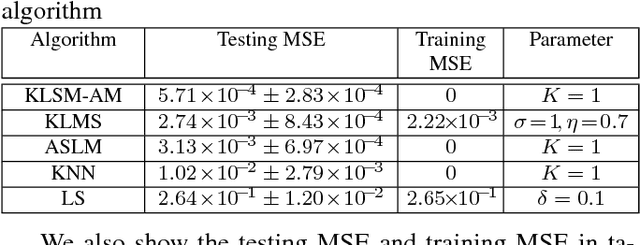
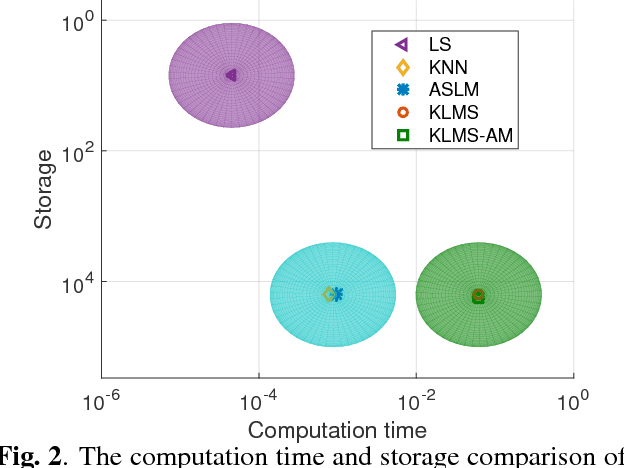
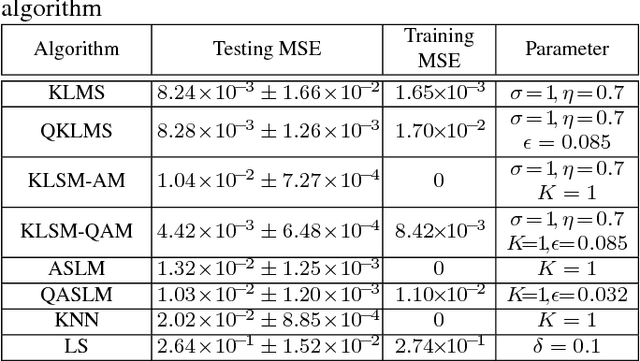
The linear model uses the space defined by the input to project the target or desired signal and find the optimal set of model parameters. When the problem is nonlinear, the adaption requires nonlinear models for good performance, but it becomes slower and more cumbersome. In this paper, we propose a linear model called Augmented Space Linear Model (ASLM), which uses the full joint space of input and desired signal as the projection space and approaches the performance of nonlinear models. This new algorithm takes advantage of the linear solution, and corrects the estimate for the current testing phase input with the error assigned to the input space neighborhood in the training phase. This algorithm can solve the nonlinear problem with the computational efficiency of linear methods, which can be regarded as a trade off between accuracy and computational complexity. Making full use of the training data, the proposed augmented space model may provide a new way to improve many modeling tasks.