 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Image Fusion via Intervention-Stable Feature Learning
Mar 24, 2026Multi-modal image fusion integrates complementary information from different modalities into a unified representation. Current methods predominantly optimize statistical correlations between modalities, often capturing dataset-induced spurious associations that degrade under distribution shifts. In this paper, we propose an intervention-based framework inspired by causal principles to identify robust cross-modal dependencies. Drawing insights from Pearl's causal hierarchy, we design three principled intervention strategies to probe different aspects of modal relationships: i) complementary masking with spatially disjoint perturbations tests whether modalities can genuinely compensate for each other's missing information, ii) random masking of identical regions identifies feature subsets that remain informative under partial observability, and iii) modality dropout evaluates the irreplaceable contribution of each modality. Based on these interventions, we introduce a Causal Feature Integrator (CFI) that learns to identify and prioritize intervention-stable features maintaining importance across different perturbation patterns through adaptive invariance gating, thereby capturing robust modal dependencies rather than spurious correlations. Extensive experiments demonstrate that our method achieves SOTA performance on both public benchmarks and downstream high-level vision tasks.
Human Pose Transfer with Disentangled Feature Consistency
Aug 06, 2021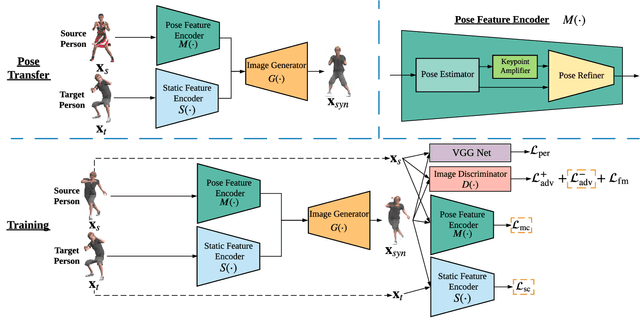



Deep generative models have made great progress in synthesizing images with arbitrary human poses and transferring poses of one person to others. However, most existing approaches explicitly leverage the pose information extracted from the source images as a conditional input for the generative networks. Meanwhile, they usually focus on the visual fidelity of the synthesized images but neglect the inherent consistency, which further confines their performance of pose transfer. To alleviate the current limitations and improve the quality of the synthesized images, we propose a pose transfer network with Disentangled Feature Consistency (DFC-Net) to facilitate human pose transfer. Given a pair of images containing the source and target person, DFC-Net extracts pose and static information from the source and target respectively, then synthesizes an image of the target person with the desired pose from the source. Moreover, DFC-Net leverages disentangled feature consistency losses in the adversarial training to strengthen the transfer coherence and integrates the keypoint amplifier to enhance the pose feature extraction. Additionally, an unpaired support dataset Mixamo-Sup providing more extra pose information has been further utilized during the training to improve the generality and robustness of DFC-Net. Extensive experimental results on Mixamo-Pose and EDN-10k have demonstrated DFC-Net achieves state-of-the-art performance on pose transfer.