 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Fourth Challenge on Image Super-Resolution ($\times$4) at NTIRE 2026: Benchmark Results and Method Overview
Apr 16, 2026This paper presents the NTIRE 2026 image super-resolution ($\times$4) challenge, one of the associated competitions of the NTIRE 2026 Workshop at CVPR 2026. The challenge aims to reconstruct high-resolution (HR) images from low-resolution (LR) inputs generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective super-resolution solutions and analyze recent advances in the field. To reflect the evolving objectives of image super-resolution, the challenge includes two tracks: (1) a restoration track, which emphasizes pixel-wise fidelity and ranks submissions based on PSNR; and (2) a perceptual track, which focuses on visual realism and evaluates results using a perceptual score. A total of 194 participants registered for the challenge, with 31 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, main results, and methods of participating teams. The challenge provides a unified benchmark and offers insights into current progress and future directions in image super-resolution.
CGGAN: A Context Guided Generative Adversarial Network For Single Image Dehazing
May 28, 2020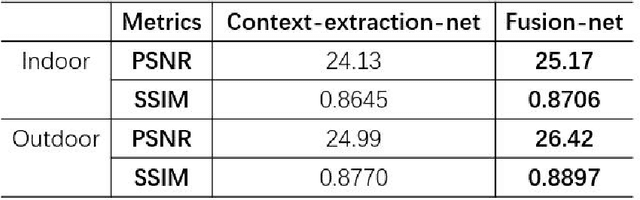
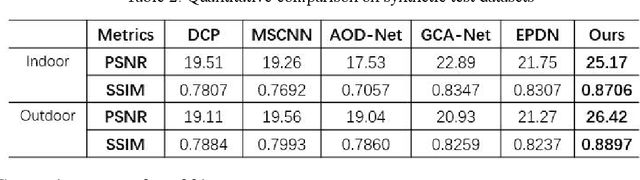
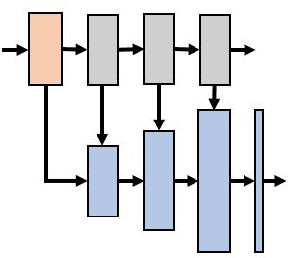
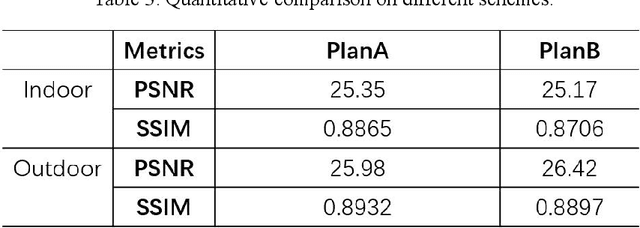
Image haze removal is highly desired for the application of computer vision. This paper proposes a novel Context Guided Generative Adversarial Network (CGGAN) for single image dehazing. Of which, an novel new encoder-decoder is employed as the generator. And it consists of a feature-extraction-net, a context-extractionnet, and a fusion-net in sequence. The feature extraction-net acts as a encoder, and is used for extracting haze features. The context-extraction net is a multi-scale parallel pyramid decoder, and is used for extracting the deep features of the encoder and generating coarse dehazing image. The fusion-net is a decoder, and is used for obtaining the final haze-free image. To obtain more better results, multi-scale information obtained during the decoding process of the context extraction decoder is used for guiding the fusion decoder. By introducing an extra coarse decoder to the original encoder-decoder, the CGGAN can make better use of the deep feature information extracted by the encoder. To ensure our CGGAN work effectively for different haze scenarios, different loss functions are employed for the two decoders. Experiments results show the advantage and the effectiveness of our proposed CGGAN, evidential improvements over existing state-of-the-art methods are obtained.