 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoFL: Continuous Flow Fields for Language-Conditioned Navigation
Mar 03, 2026Language-conditioned navigation pipelines often rely on brittle modular components or costly action-sequence generation. To address these limitations, we present CoFL, an end-to-end policy that directly maps a bird's-eye view (BEV) observation and a language instruction to a continuous flow field for navigation. Instead of predicting discrete action tokens or sampling action chunks via iterative denoising, CoFL outputs instantaneous velocities that can be queried at arbitrary 2D projected locations. Trajectories are obtained by numerical integration of the predicted field, producing smooth motion that remains reactive under closed-loop execution. To enable large-scale training, we build a dataset of over 500k BEV image-instruction pairs, each procedurally annotated with a flow field and a trajectory derived from BEV semantic maps built on Matterport3D and ScanNet. By training on a mixed distribution, CoFL significantly outperforms modular Vision-Language Model (VLM)-based planners and generative policy baselines on strictly unseen scenes. Finally, we deploy CoFL zero-shot in real-world experiments with overhead BEV observations across multiple layouts, maintaining reliable closed-loop control and a high success rate.
Learning Agile and Robust Omnidirectional Aerial Motion on Overactuated Tiltable-Quadrotors
Feb 25, 2026Tilt-rotor aerial robots enable omnidirectional maneuvering through thrust vectoring, but introduce significant control challenges due to the strong coupling between joint and rotor dynamics. While model-based controllers can achieve high motion accuracy under nominal conditions, their robustness and responsiveness often degrade in the presence of disturbances and modeling uncertainties. This work investigates reinforcement learning for omnidirectional aerial motion control on over-actuated tiltable quadrotors that prioritizes robustness and agility. We present a learning-based control framework that enables efficient acquisition of coordinated rotor-joint behaviors for reaching target poses in the $SE(3)$ space. To achieve reliable sim-to-real transfer while preserving motion accuracy, we integrate system identification with minimal and physically consistent domain randomization. Compared with a state-of-the-art NMPC controller, the proposed method achieves comparable six-degree-of-freedom pose tracking accuracy, while demonstrating superior robustness and generalization across diverse tasks, enabling zero-shot deployment on real hardware.
Hierarchical Language Models for Semantic Navigation and Manipulation in an Aerial-Ground Robotic System
Jun 05, 2025Heterogeneous multi-robot systems show great potential in complex tasks requiring coordinated hybrid cooperation. However, traditional approaches relying on static models often struggle with task diversity and dynamic environments. This highlights the need for generalizable intelligence that can bridge high-level reasoning with low-level execution across heterogeneous agents. To address this, we propose a hierarchical framework integrating a prompted Large Language Model (LLM) and a GridMask-enhanced fine-tuned Vision Language Model (VLM). The LLM performs task decomposition and global semantic map construction, while the VLM extracts task-specified semantic labels and 2D spatial information from aerial images to support local planning. Within this framework, the aerial robot follows a globally optimized semantic path and continuously provides bird-view images, guiding the ground robot's local semantic navigation and manipulation, including target-absent scenarios where implicit alignment is maintained. Experiments on a real-world letter-cubes arrangement task demonstrate the framework's adaptability and robustness in dynamic environments. To the best of our knowledge, this is the first demonstration of an aerial-ground heterogeneous system integrating VLM-based perception with LLM-driven task reasoning and motion planning.
EEGDnet: Fusing Non-Local and Local Self-Similarity for 1-D EEG Signal Denoising with 2-D Transformer
Sep 09, 2021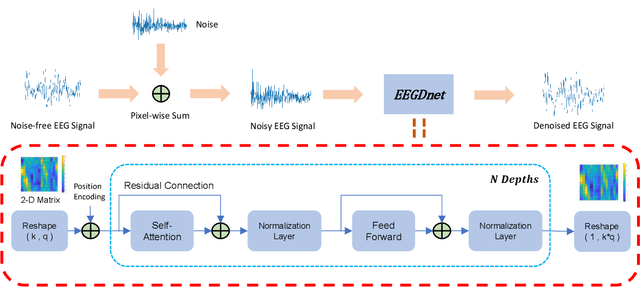

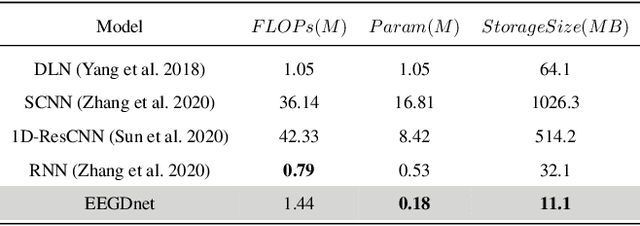
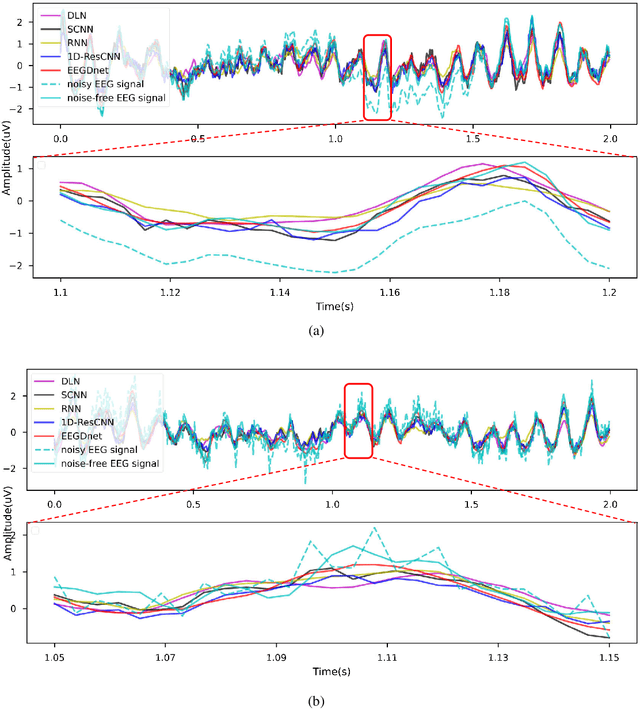
Electroencephalogram (EEG) has shown a useful approach to produce a brain-computer interface (BCI). One-dimensional (1-D) EEG signal is yet easily disturbed by certain artifacts (a.k.a. noise) due to the high temporal resolution. Thus, it is crucial to remove the noise in received EEG signal. Recently, deep learning-based EEG signal denoising approaches have achieved impressive performance compared with traditional ones. It is well known that the characteristics of self-similarity (including non-local and local ones) of data (e.g., natural images and time-domain signals) are widely leveraged for denoising. However, existing deep learning-based EEG signal denoising methods ignore either the non-local self-similarity (e.g., 1-D convolutional neural network) or local one (e.g., fully connected network and recurrent neural network). To address this issue, we propose a novel 1-D EEG signal denoising network with 2-D transformer, namely EEGDnet. Specifically, we comprehensively take into account the non-local and local self-similarity of EEG signal through the transformer module. By fusing non-local self-similarity in self-attention blocks and local self-similarity in feed forward blocks, the negative impact caused by noises and outliers can be reduced significantly. Extensive experiments show that, compared with other state-of-the-art models, EEGDnet achieves much better performance in terms of both quantitative and qualitative metrics.