 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALLSTEPS: Curriculum-driven Learning of Stepping Stone Skills
May 09, 2020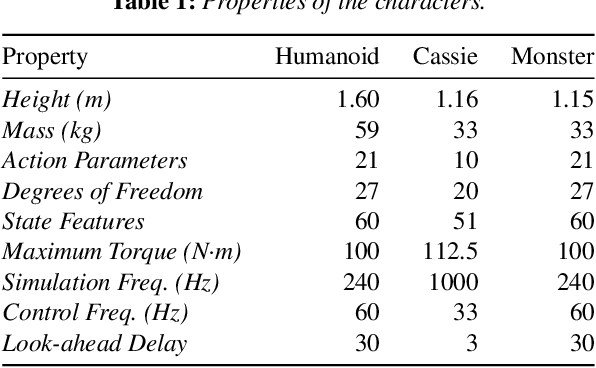
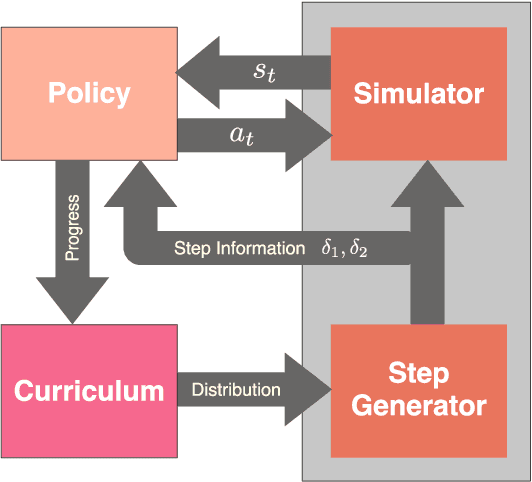

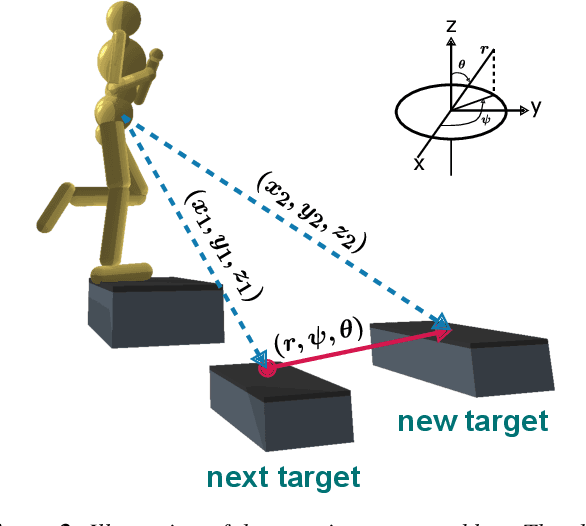
Humans are highly adept at walking in environments with foot placement constraints, including stepping-stone scenarios where the footstep locations are fully constrained. Finding good solutions to stepping-stone locomotion is a longstanding and fundamental challenge for animation and robotics. We present fully learned solutions to this difficult problem using reinforcement learning. We demonstrate the importance of a curriculum for efficient learning and evaluate four possible curriculum choices compared to a non-curriculum baseline. Results are presented for a simulated human character, a realistic bipedal robot simulation and a monster character, in each case producing robust, plausible motions for challenging stepping stone sequences and terrains.
Learning to Correspond Dynamical Systems
Dec 23, 2019
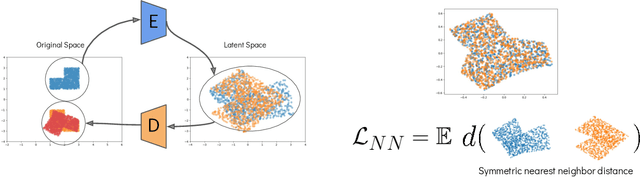
Many dynamical systems exhibit similar structure, as often captured by hand-designed simplified models that can be used for analysis and control. We develop a method for learning to correspond pairs of dynamical systems via a learned latent dynamical system. Given trajectory data from two dynamical systems, we learn a shared latent state space and a shared latent dynamics model, along with an encoder-decoder pair for each of the original systems. With the learned correspondences in place, we can use a simulation of one system to produce an imagined motion of its counterpart. We can also simulate in the learned latent dynamics and synthesize the motions of both corresponding systems, as a form of bisimulation. We demonstrate the approach using pairs of controlled bipedal walkers, as well as by pairing a walker with a controlled pendulum.
Iterative Reinforcement Learning Based Design of Dynamic Locomotion Skills for Cassie
Mar 22, 2019
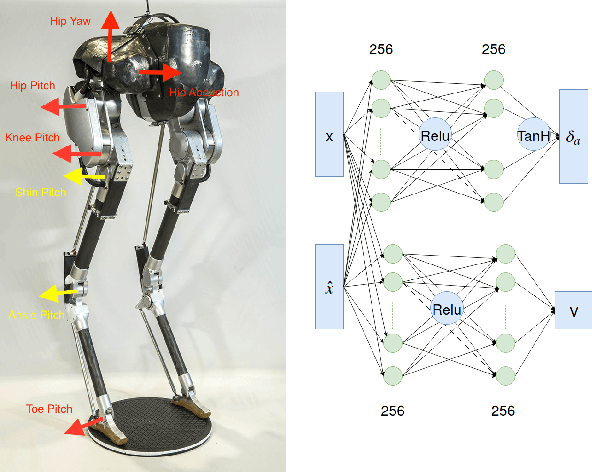
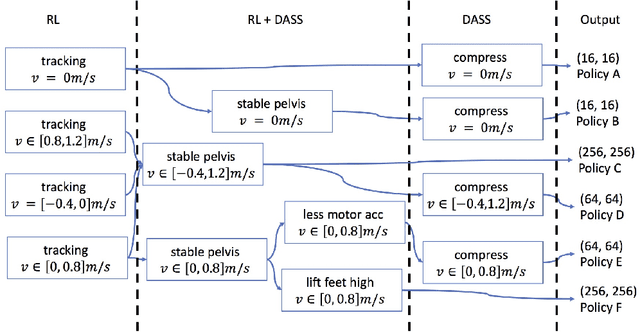
Deep reinforcement learning (DRL) is a promising approach for developing legged locomotion skills. However, the iterative design process that is inevitable in practice is poorly supported by the default methodology. It is difficult to predict the outcomes of changes made to the reward functions, policy architectures, and the set of tasks being trained on. In this paper, we propose a practical method that allows the reward function to be fully redefined on each successive design iteration while limiting the deviation from the previous iteration. We characterize policies via sets of Deterministic Action Stochastic State (DASS) tuples, which represent the deterministic policy state-action pairs as sampled from the states visited by the trained stochastic policy. New policies are trained using a policy gradient algorithm which then mixes RL-based policy gradients with gradient updates defined by the DASS tuples. The tuples also allow for robust policy distillation to new network architectures. We demonstrate the effectiveness of this iterative-design approach on the bipedal robot Cassie, achieving stable walking with different gait styles at various speeds. We demonstrate the successful transfer of policies learned in simulation to the physical robot without any dynamics randomization, and that variable-speed walking policies for the physical robot can be represented by a small dataset of 5-10k tuples.
Feedback Control For Cassie With Deep Reinforcement Learning
Jul 27, 2018
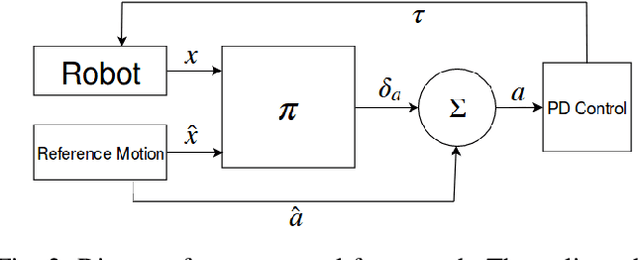
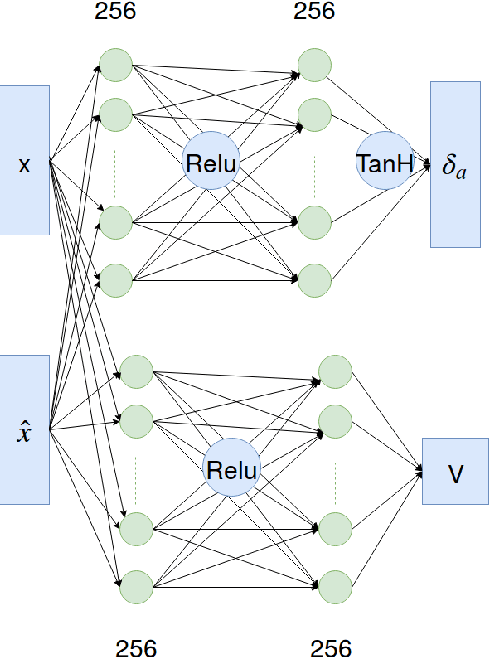
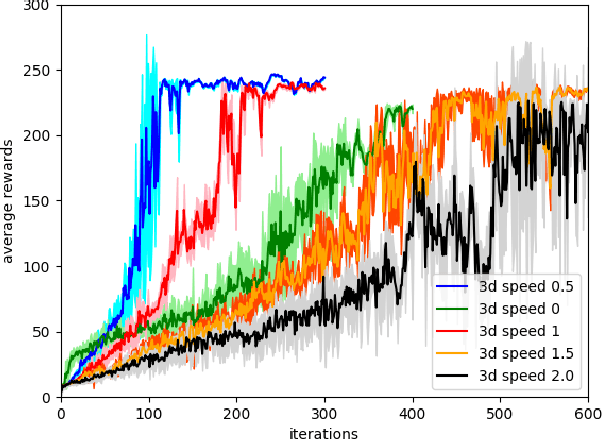
Bipedal locomotion skills are challenging to develop. Control strategies often use local linearization of the dynamics in conjunction with reduced-order abstractions to yield tractable solutions. In these model-based control strategies, the controller is often not fully aware of many details, including torque limits, joint limits, and other non-linearities that are necessarily excluded from the control computations for simplicity. Deep reinforcement learning (DRL) offers a promising model-free approach for controlling bipedal locomotion which can more fully exploit the dynamics. However, current results in the machine learning literature are often based on ad-hoc simulation models that are not based on corresponding hardware. Thus it remains unclear how well DRL will succeed on realizable bipedal robots. In this paper, we demonstrate the effectiveness of DRL using a realistic model of Cassie, a bipedal robot. By formulating a feedback control problem as finding the optimal policy for a Markov Decision Process, we are able to learn robust walking controllers that imitate a reference motion with DRL. Controllers for different walking speeds are learned by imitating simple time-scaled versions of the original reference motion. Controller robustness is demonstrated through several challenging tests, including sensory delay, walking blindly on irregular terrain and unexpected pushes at the pelvis. We also show we can interpolate between individual policies and that robustness can be improved with an interpolated policy.