 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Adapter-Bot: All-In-One Controllable Conversational Model
Aug 28, 2020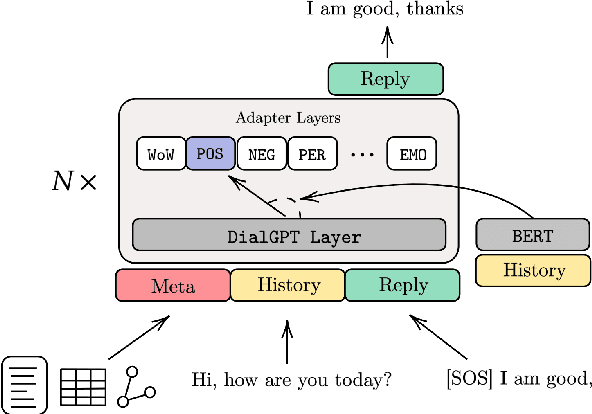

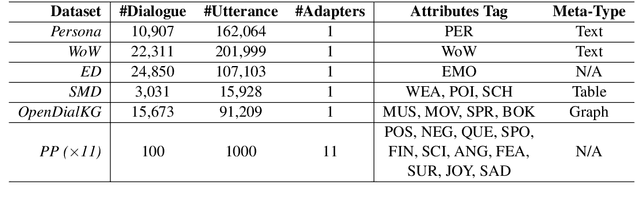
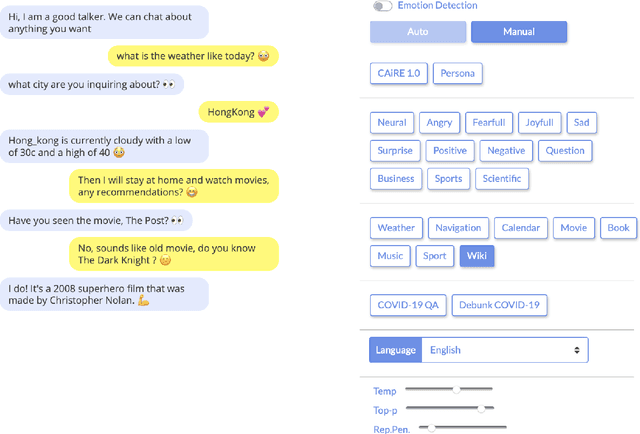
Considerable progress has been made towards conversational models that generate coherent and fluent responses by training large language models on large dialogue datasets. These models have little or no control of the generated responses and miss two important features: continuous dialogue skills integration and seamlessly leveraging diverse knowledge sources. In this paper, we propose the Adapter-Bot, a dialogue model that uses a fixed backbone conversational model such as DialGPT (Zhang et al., 2019) and triggers on-demand dialogue skills (e.g., emphatic response, weather information, movie recommendation) via different adapters (Houlsby et al., 2019). Each adapter can be trained independently, thus allowing a continual integration of skills without retraining the entire model. Depending on the skills, the model is able to process multiple knowledge types, such as text, tables, and graphs, in a seamless manner. The dialogue skills can be triggered automatically via a dialogue manager, or manually, thus allowing high-level control of the generated responses. At the current stage, we have implemented 12 response styles (e.g., positive, negative etc.), 8 goal-oriented skills (e.g. weather information, movie recommendation, etc.), and personalized and emphatic responses. We evaluate our model using automatic evaluation by comparing it with existing state-of-the-art conversational models, and we have released an interactive system at adapter.bot.ust.hk.
EmoGraph: Capturing Emotion Correlations using Graph Networks
Aug 21, 2020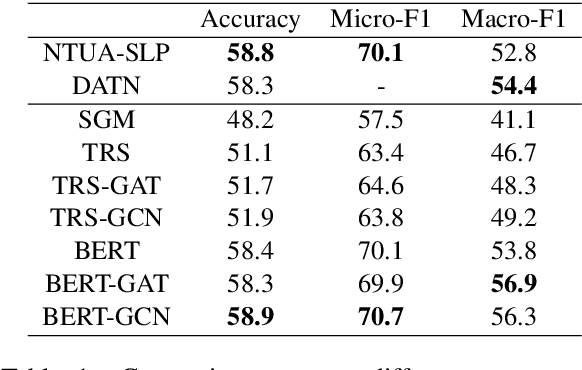
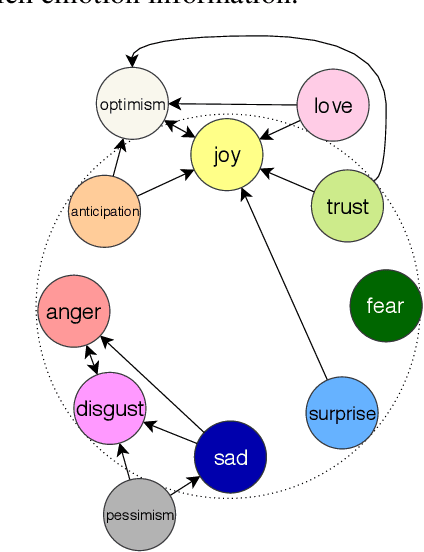
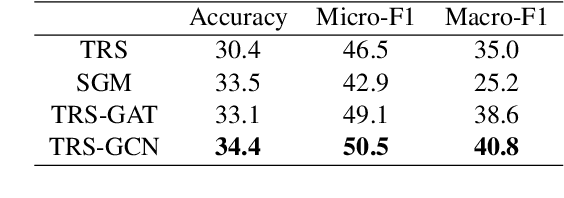
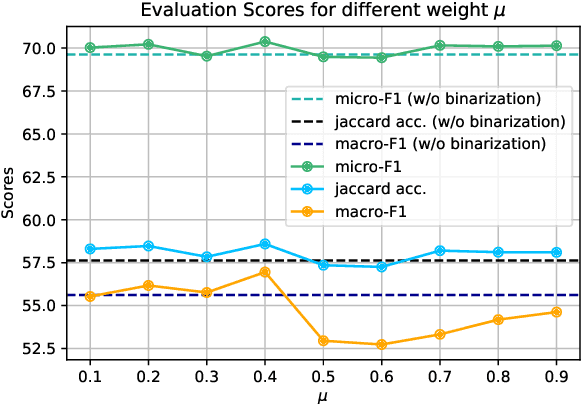
Most emotion recognition methods tackle the emotion understanding task by considering individual emotion independently while ignoring their fuzziness nature and the interconnections among them. In this paper, we explore how emotion correlations can be captured and help different classification tasks. We propose EmoGraph that captures the dependencies among different emotions through graph networks. These graphs are constructed by leveraging the co-occurrence statistics among different emotion categories. Empirical results on two multi-label classification datasets demonstrate that EmoGraph outperforms strong baselines, especially for macro-F1. An additional experiment illustrates the captured emotion correlations can also benefit a single-label classification task.
Language Models as Few-Shot Learner for Task-Oriented Dialogue Systems
Aug 20, 2020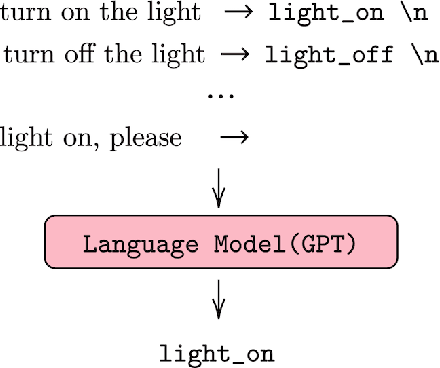
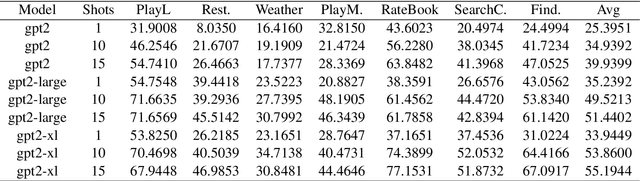
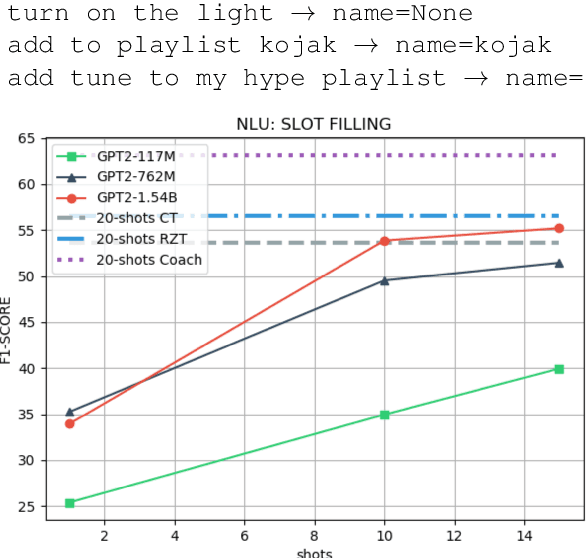
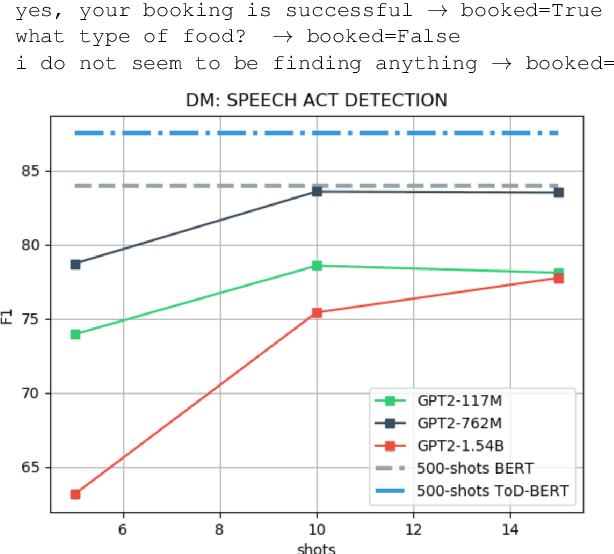
Task-oriented dialogue systems use four connected modules, namely, Natural Language Understanding (NLU), a Dialogue State Tracking (DST), Dialogue Policy (DP) and Natural Language Generation (NLG). A research challenge is to learn each module with the least amount of samples (i.e., few-shots) given the high cost related to the data collection. The most common and effective technique to solve this problem is transfer learning, where large language models, either pre-trained on text or task-specific data, are fine-tuned on the few samples. These methods require fine-tuning steps and a set of parameters for each task. Differently, language models, such as GPT-2 (Radford et al., 2019) and GPT-3 (Brown et al., 2020), allow few-shot learning by priming the model with few examples. In this paper, we evaluate the priming few-shot ability of language models in the NLU, DST, DP and NLG tasks. Importantly, we highlight the current limitations of this approach, and we discuss the possible implication for future work.
Meta-Transfer Learning for Code-Switched Speech Recognition
Apr 29, 2020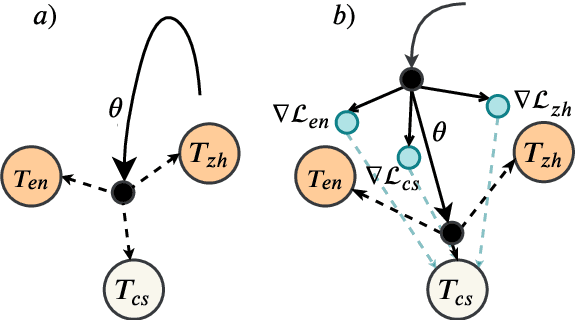
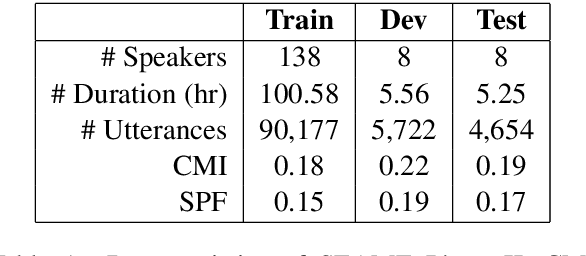
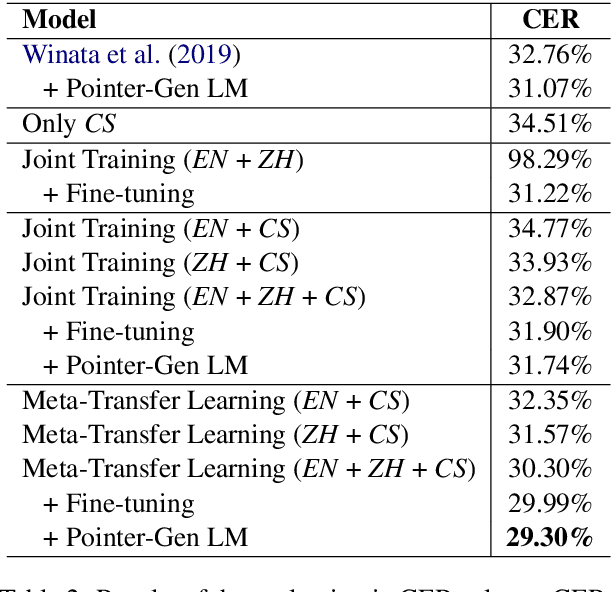
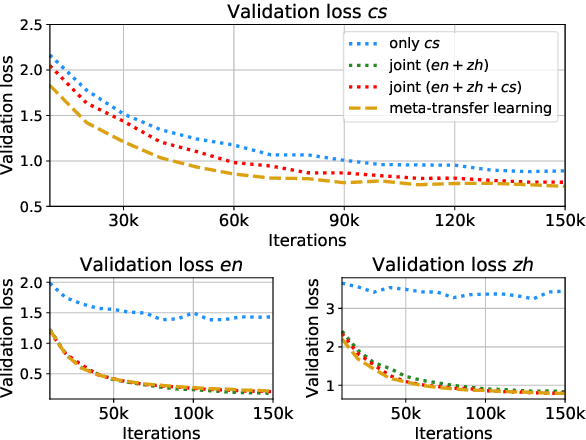
An increasing number of people in the world today speak a mixed-language as a result of being multilingual. However, building a speech recognition system for code-switching remains difficult due to the availability of limited resources and the expense and significant effort required to collect mixed-language data. We therefore propose a new learning method, meta-transfer learning, to transfer learn on a code-switched speech recognition system in a low-resource setting by judiciously extracting information from high-resource monolingual datasets. Our model learns to recognize individual languages, and transfer them so as to better recognize mixed-language speech by conditioning the optimization on the code-switching data. Based on experimental results, our model outperforms existing baselines on speech recognition and language modeling tasks, and is faster to converge.
XPersona: Evaluating Multilingual Personalized Chatbot
Apr 08, 2020
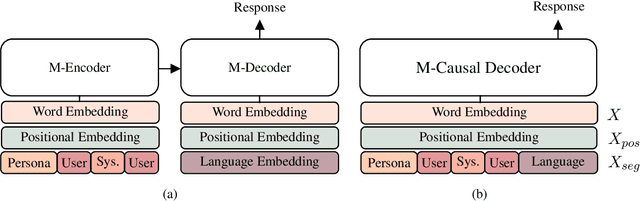
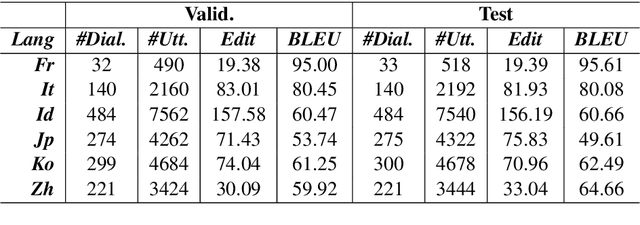
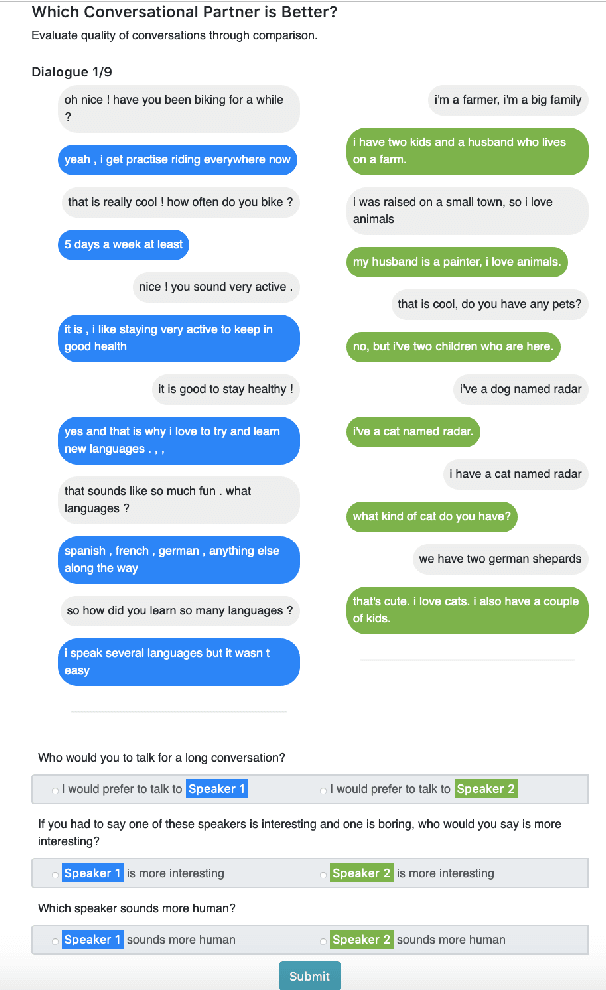
Personalized dialogue systems are an essential step toward better human-machine interaction. Existing personalized dialogue agents rely on properly designed conversational datasets, which are mostly monolingual (e.g., English), which greatly limits the usage of conversational agents in other languages. In this paper, we propose a multi-lingual extension of Persona-Chat, namely XPersona. Our dataset includes persona conversations in six different languages other than English for building and evaluating multilingual personalized agents. We experiment with both multilingual and cross-lingual trained baselines, and evaluate them against monolingual and translation-pipeline models using both automatic and human evaluation. Experimental results show that the multilingual trained models outperform the translation-pipeline and that they are on par with the monolingual models, with the advantage of having a single model across multiple languages. On the other hand, the state-of-the-art cross-lingual trained models achieve inferior performance to the other models, showing that cross-lingual conversation modeling is a challenging task. We hope that our dataset and baselines will accelerate research in multilingual dialogue systems.
Exploring Versatile Generative Language Model Via Parameter-Efficient Transfer Learning
Apr 08, 2020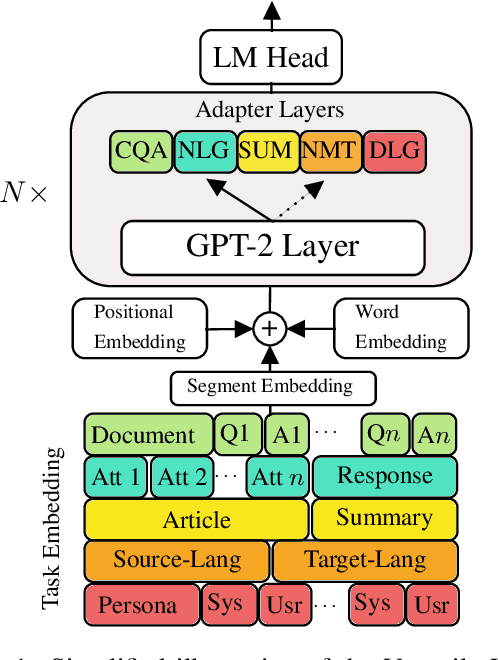
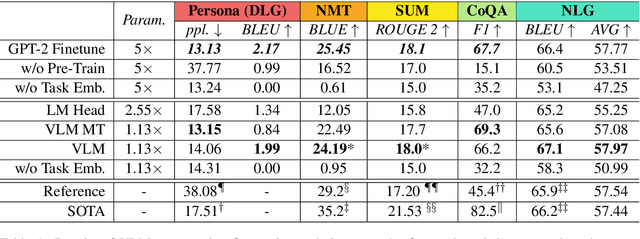
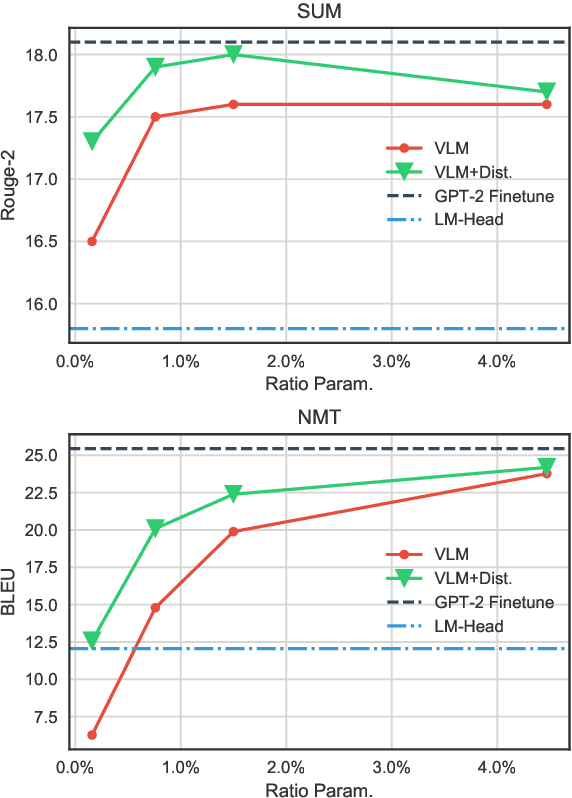
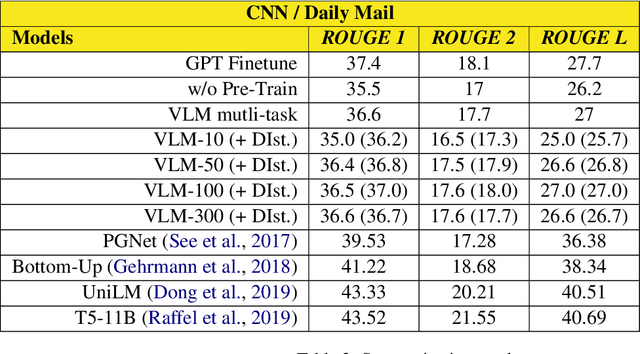
Fine-tuning pre-trained generative language models to down-stream language generation tasks has shown promising results. However, this comes with the cost of having a single, large model for each task, which is not ideal in low-memory/power scenarios (e.g., mobile). In this paper, we propose an effective way to fine-tune multiple down-stream generation tasks simultaneously using a single, large pre-trained model. The experiments on five diverse language generation tasks show that by just using an additional 2-3% parameters for each task, our model can maintain or even improve the performance of fine-tuning the whole model.
Variational Transformers for Diverse Response Generation
Mar 28, 2020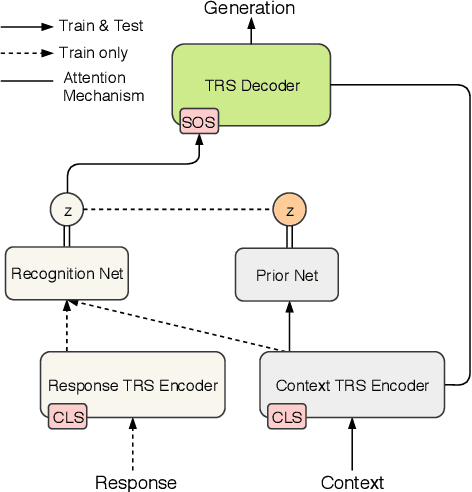
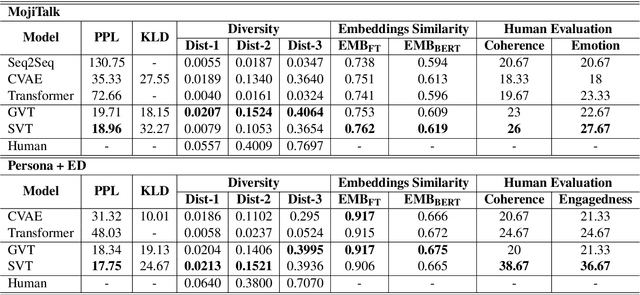
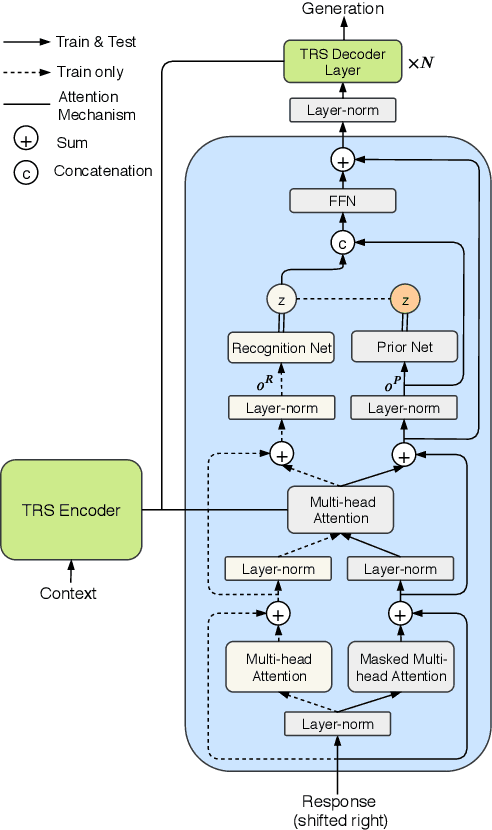
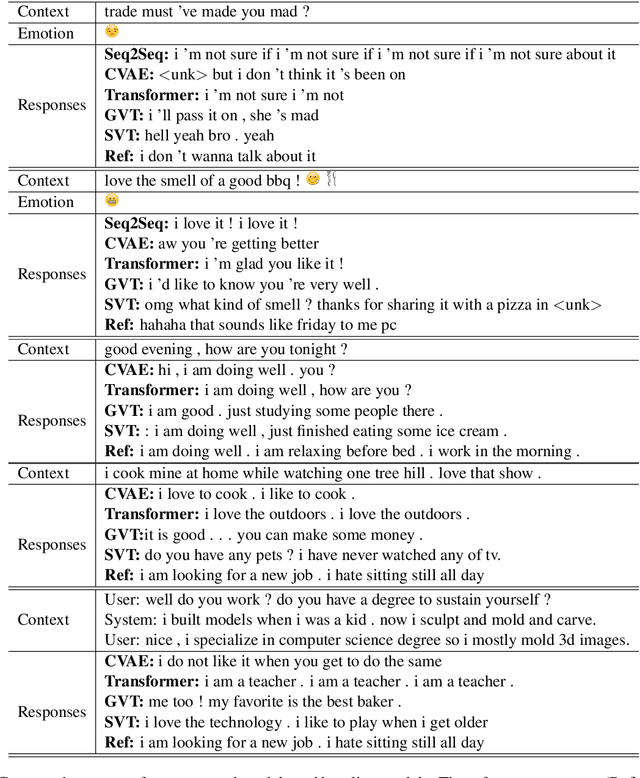
Despite the great promise of Transformers in many sequence modeling tasks (e.g., machine translation), their deterministic nature hinders them from generalizing to high entropy tasks such as dialogue response generation. Previous work proposes to capture the variability of dialogue responses with a recurrent neural network (RNN)-based conditional variational autoencoder (CVAE). However, the autoregressive computation of the RNN limits the training efficiency. Therefore, we propose the Variational Transformer (VT), a variational self-attentive feed-forward sequence model. The VT combines the parallelizability and global receptive field of the Transformer with the variational nature of the CVAE by incorporating stochastic latent variables into Transformers. We explore two types of the VT: 1) modeling the discourse-level diversity with a global latent variable; and 2) augmenting the Transformer decoder with a sequence of fine-grained latent variables. Then, the proposed models are evaluated on three conversational datasets with both automatic metric and human evaluation. The experimental results show that our models improve standard Transformers and other baselines in terms of diversity, semantic relevance, and human judgment.
Attention over Parameters for Dialogue Systems
Jan 07, 2020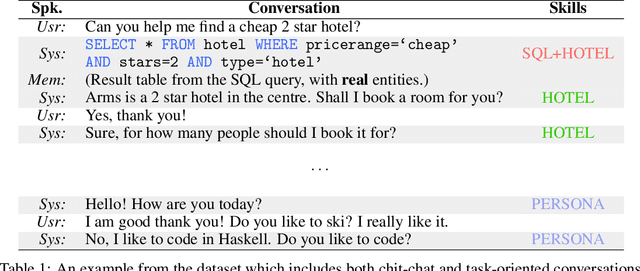
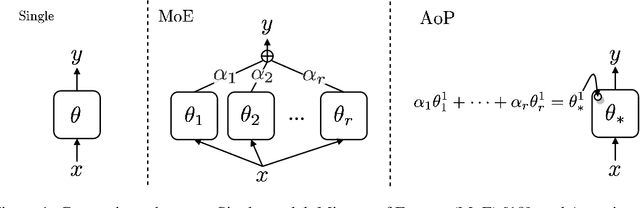
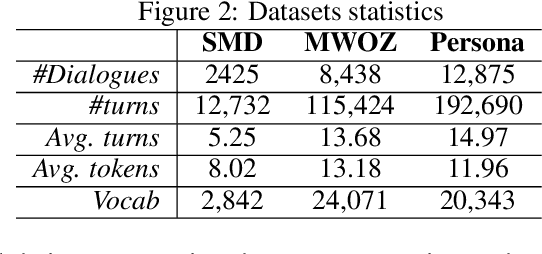
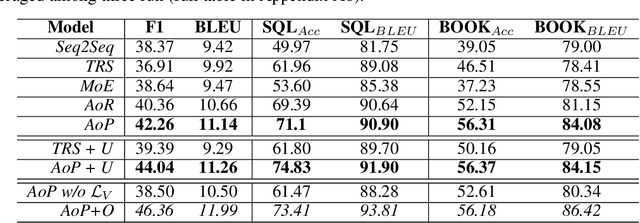
Dialogue systems require a great deal of different but complementary expertise to assist, inform, and entertain humans. For example, different domains (e.g., restaurant reservation, train ticket booking) of goal-oriented dialogue systems can be viewed as different skills, and so does ordinary chatting abilities of chit-chat dialogue systems. In this paper, we propose to learn a dialogue system that independently parameterizes different dialogue skills, and learns to select and combine each of them through Attention over Parameters (AoP). The experimental results show that this approach achieves competitive performance on a combined dataset of MultiWOZ, In-Car Assistant, and Persona-Chat. Finally, we demonstrate that each dialogue skill is effectively learned and can be combined with other skills to produce selective responses.
Attention-Informed Mixed-Language Training for Zero-shot Cross-lingual Task-oriented Dialogue Systems
Nov 21, 2019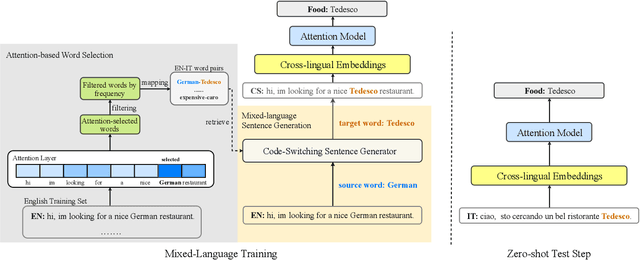
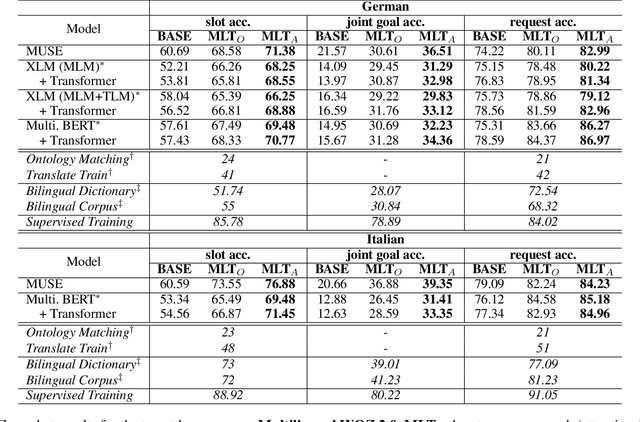
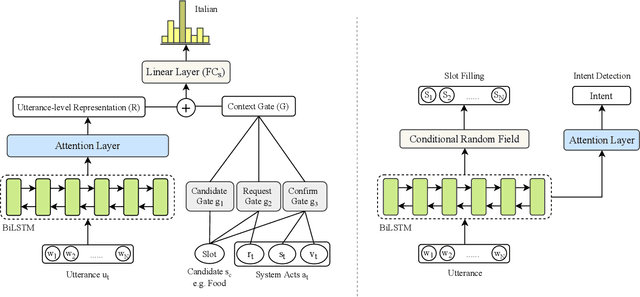
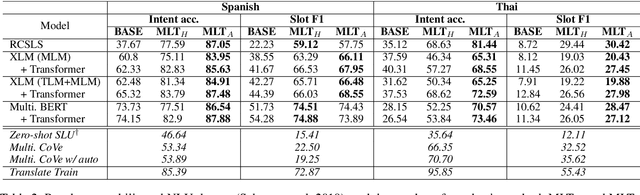
Recently, data-driven task-oriented dialogue systems have achieved promising performance in English. However, developing dialogue systems that support low-resource languages remains a long-standing challenge due to the absence of high-quality data. In order to circumvent the expensive and time-consuming data collection, we introduce Attention-Informed Mixed-Language Training (MLT), a novel zero-shot adaptation method for cross-lingual task-oriented dialogue systems. It leverages very few task-related parallel word pairs to generate code-switching sentences for learning the inter-lingual semantics across languages. Instead of manually selecting the word pairs, we propose to extract source words based on the scores computed by the attention layer of a trained English task-related model and then generate word pairs using existing bilingual dictionaries. Furthermore, intensive experiments with different cross-lingual embeddings demonstrate the effectiveness of our approach. Finally, with very few word pairs, our model achieves significant zero-shot adaptation performance improvements in both cross-lingual dialogue state tracking and natural language understanding (i.e., intent detection and slot filling) tasks compared to the current state-of-the-art approaches, which utilize a much larger amount of bilingual data.
Lightweight and Efficient End-to-End Speech Recognition Using Low-Rank Transformer
Oct 30, 2019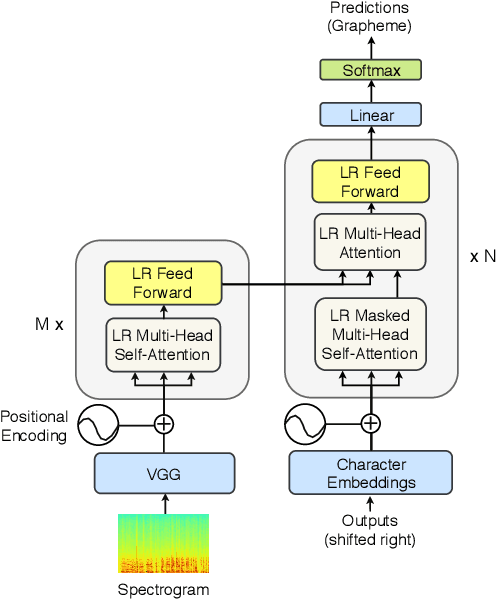
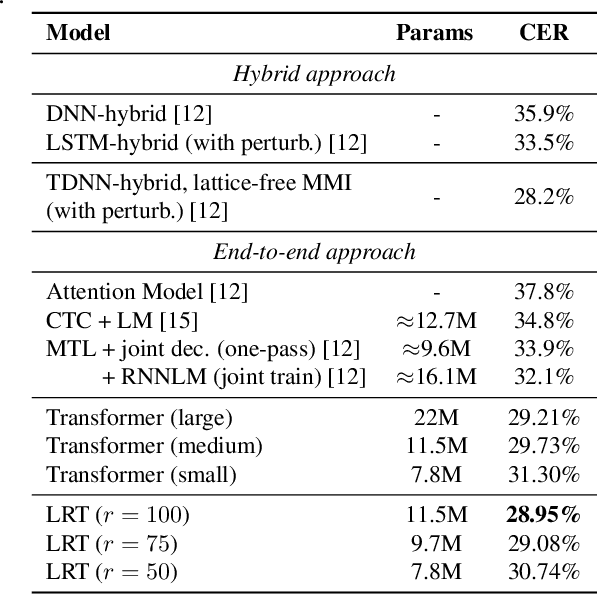
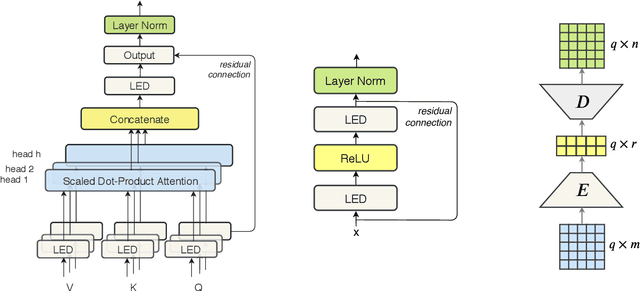
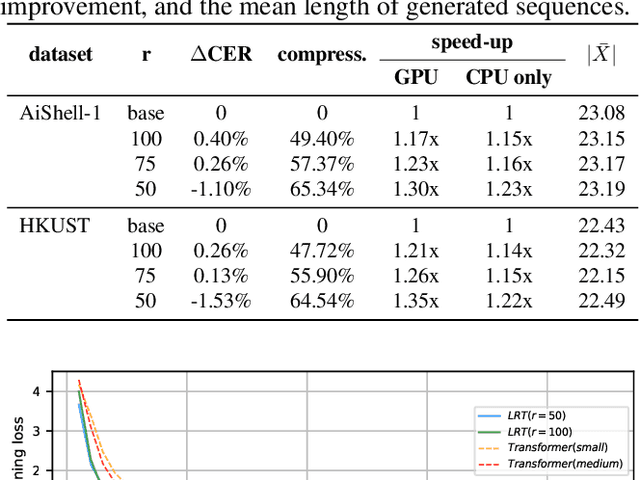
High performing deep neural networks come at the cost of computational complexity that limits its practicality for deployment on portable devices. We propose Low-Rank Transformer (LRT), a memory-efficient and fast neural architecture that significantly reduces the parameters and boosts the speed in training and inference for end-to-end speech recognition. Our approach reduces the number of parameters of the network by more than 50% parameters and speed-up the inference time by around 1.26x compared to the baseline transformer model. The experiments show that LRT models generalize better and yield lower error rates on both validation and test sets compared to the uncompressed transformer model. LRT models outperform existing works on several datasets in an end-to-end setting without using any external language model and acoustic data.