 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge[CLS] is Not Enough: Multi-Label Recognition via Patch-Level Inference and Adaptive Aggregation
May 25, 2026Vision-Language Models such as CLIP exhibit strong zero-shot recognition capability by aligning images with textual concepts, yet they often underperform on multi-label recognition where multiple objects co-exist. A key bottleneck is that the [CLS] token, as a single global visual representation, is insufficient to faithfully encode diverse targets with varying scales, contexts, and co-occurrence patterns. To address this limitation, we present a new multi-label image recognition framework, termed PIAA, which formulates prediction as Patch-level Inference followed by Adaptive Aggregation. Specifically, we first enhance patch-wise predictions from two complementary perspectives: (i) mitigating semantic entanglement in the visual encoder to obtain more discriminative patch representations, and (ii) learning an unsupervised visual classifier to narrow the vision-language modality gap. We then introduce an adaptive aggregation module that consolidates patch-level scores into the final multi-label prediction. Notably, the entire pipeline is fully training-free, requiring no gradient updates or parameter fine-tuning. Experiments show that our method achieves strong improvements with minimal extra computation, exceeding a 6% mAP gain on the challenging NUS-WIDE benchmark over representative baselines. Code is available at https://github.com/akang-wang/PIAA.
ConInfer: Context-Aware Inference for Training-Free Open-Vocabulary Remote Sensing Segmentation
Mar 31, 2026Training-free open-vocabulary remote sensing segmentation (OVRSS), empowered by vision-language models, has emerged as a promising paradigm for achieving category-agnostic semantic understanding in remote sensing imagery. Existing approaches mainly focus on enhancing feature representations or mitigating modality discrepancies to improve patch-level prediction accuracy. However, such independent prediction schemes are fundamentally misaligned with the intrinsic characteristics of remote sensing data. In real-world applications, remote sensing scenes are typically large-scale and exhibit strong spatial as well as semantic correlations, making isolated patch-wise predictions insufficient for accurate segmentation. To address this limitation, we propose ConInfer, a context-aware inference framework for OVRSS that performs joint prediction across multiple spatial units while explicitly modeling their inter-unit semantic dependencies. By incorporating global contextual cues, our method significantly enhances segmentation consistency, robustness, and generalization in complex remote sensing environments. Extensive experiments on multiple benchmark datasets demonstrate that our approach consistently surpasses state-of-the-art per-pixel VLM-based baselines such as SegEarth-OV, achieving average improvements of 2.80% and 6.13% on open-vocabulary semantic segmentation and object extraction tasks, respectively. The implementation code is available at: https://github.com/Dog-Yang/ConInfer
OTFusion: Bridging Vision-only and Vision-Language Models via Optimal Transport for Transductive Zero-Shot Learning
Jun 16, 2025Transductive zero-shot learning (ZSL) aims to classify unseen categories by leveraging both semantic class descriptions and the distribution of unlabeled test data. While Vision-Language Models (VLMs) such as CLIP excel at aligning visual inputs with textual semantics, they often rely too heavily on class-level priors and fail to capture fine-grained visual cues. In contrast, Vision-only Foundation Models (VFMs) like DINOv2 provide rich perceptual features but lack semantic alignment. To exploit the complementary strengths of these models, we propose OTFusion, a simple yet effective training-free framework that bridges VLMs and VFMs via Optimal Transport. Specifically, OTFusion aims to learn a shared probabilistic representation that aligns visual and semantic information by minimizing the transport cost between their respective distributions. This unified distribution enables coherent class predictions that are both semantically meaningful and visually grounded. Extensive experiments on 11 benchmark datasets demonstrate that OTFusion consistently outperforms the original CLIP model, achieving an average accuracy improvement of nearly $10\%$, all without any fine-tuning or additional annotations. The code will be publicly released after the paper is accepted.
An Iteratively Re-weighted Method for Problems with Sparsity-Inducing Norms
Jul 02, 2019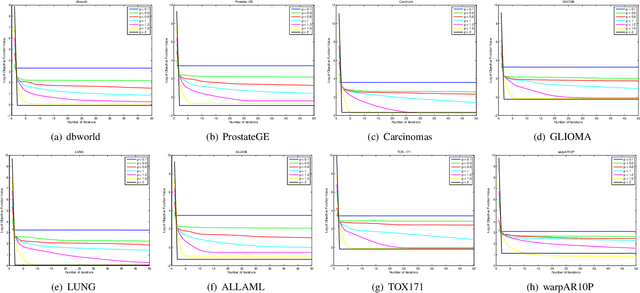
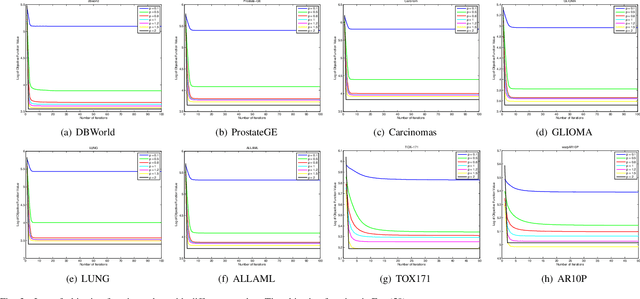
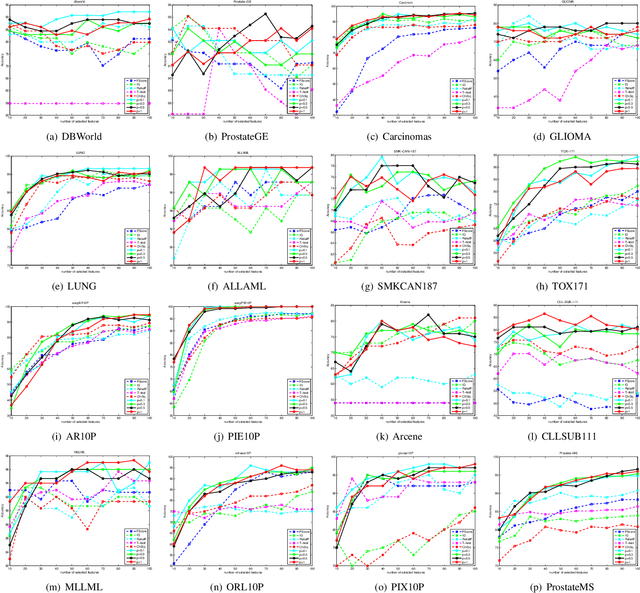
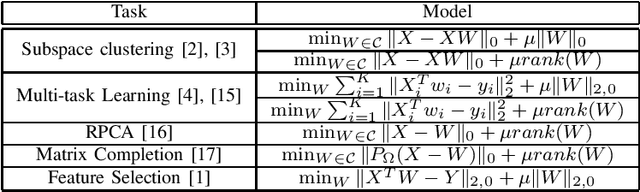
This work aims at solving the problems with intractable sparsity-inducing norms that are often encountered in various machine learning tasks, such as multi-task learning, subspace clustering, feature selection, robust principal component analysis, and so on. Specifically, an Iteratively Re-Weighted method (IRW) with solid convergence guarantee is provided. We investigate its convergence speed via numerous experiments on real data. Furthermore, in order to validate the practicality of IRW, we use it to solve a concrete robust feature selection model with complicated objective function. The experimental results show that the model coupled with proposed optimization method outperforms alternative methods significantly.
A Comprehensive Survey for Low Rank Regularization
Sep 14, 2018
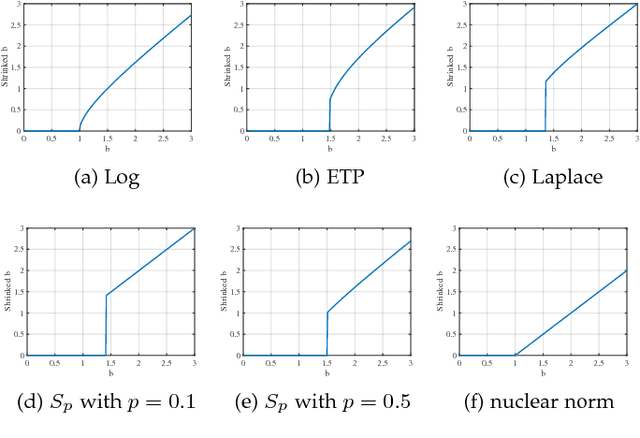
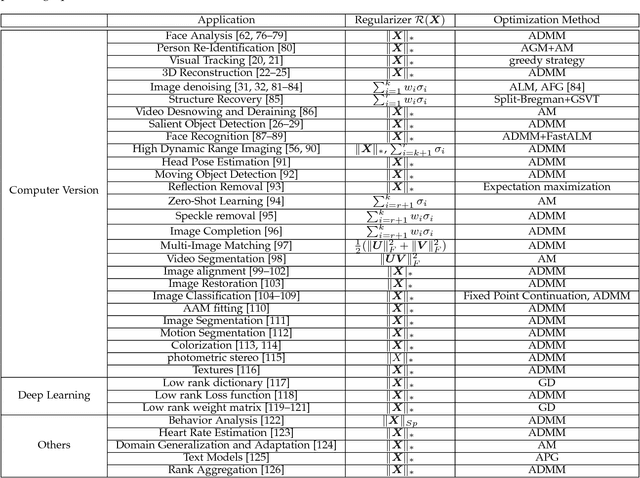

Low rank regularization, in essence, involves introducing a low rank or approximately low rank assumption for matrix we aim to learn, which has achieved great success in many fields including machine learning, data mining and computer version. Over the last decade, much progress has been made in theories and practical applications. Nevertheless, the intersection between them is very slight. In order to construct a bridge between practical applications and theoretical research, in this paper we provide a comprehensive survey for low rank regularization. We first review several traditional machine learning models using low rank regularization, and then show their (or their variants) applications in solving practical issues, such as non-rigid structure from motion and image denoising. Subsequently, we summarize the regularizers and optimization methods that achieve great success in traditional machine learning tasks but are rarely seen in solving practical issues. Finally, we provide a discussion and comparison for some representative regularizers including convex and non-convex relaxations. Extensive experimental results demonstrate that non-convex regularizers can provide a large advantage over the nuclear norm, the regularizer widely used in solving practical issues.