 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining-free Object Counting with Prompts
Jun 30, 2023



This paper tackles the problem of object counting in images. Existing approaches rely on extensive training data with point annotations for each object, making data collection labor-intensive and time-consuming. To overcome this, we propose a training-free object counter that treats the counting task as a segmentation problem. Our approach leverages the Segment Anything Model (SAM), known for its high-quality masks and zero-shot segmentation capability. However, the vanilla mask generation method of SAM lacks class-specific information in the masks, resulting in inferior counting accuracy. To overcome this limitation, we introduce a prior-guided mask generation method that incorporates three types of priors into the segmentation process, enhancing efficiency and accuracy. Additionally, we tackle the issue of counting objects specified through free-form text by proposing a two-stage approach that combines reference object selection and prior-guided mask generation. Extensive experiments on standard datasets demonstrate the competitive performance of our training-free counter compared to learning-based approaches. This paper presents a promising solution for counting objects in various scenarios without the need for extensive data collection and model training. Code is available at https://github.com/shizenglin/training-free-object-counter.
Focus for Free in Density-Based Counting
Jun 08, 2023



This work considers supervised learning to count from images and their corresponding point annotations. Where density-based counting methods typically use the point annotations only to create Gaussian-density maps, which act as the supervision signal, the starting point of this work is that point annotations have counting potential beyond density map generation. We introduce two methods that repurpose the available point annotations to enhance counting performance. The first is a counting-specific augmentation that leverages point annotations to simulate occluded objects in both input and density images to enhance the network's robustness to occlusions. The second method, foreground distillation, generates foreground masks from the point annotations, from which we train an auxiliary network on images with blacked-out backgrounds. By doing so, it learns to extract foreground counting knowledge without interference from the background. These methods can be seamlessly integrated with existing counting advances and are adaptable to different loss functions. We demonstrate complementary effects of the approaches, allowing us to achieve robust counting results even in challenging scenarios such as background clutter, occlusion, and varying crowd densities. Our proposed approach achieves strong counting results on multiple datasets, including ShanghaiTech Part\_A and Part\_B, UCF\_QNRF, JHU-Crowd++, and NWPU-Crowd.
On the Robustness, Generalization, and Forgetting of Shape-Texture Debiased Continual Learning
Nov 26, 2022Tremendous progress has been made in continual learning to maintain good performance on old tasks when learning new tasks by tackling the catastrophic forgetting problem of neural networks. This paper advances continual learning by further considering its out-of-distribution robustness, in response to the vulnerability of continually trained models to distribution shifts (e.g., due to data corruptions and domain shifts) in inference. To this end, we propose shape-texture debiased continual learning. The key idea is to learn generalizable and robust representations for each task with shape-texture debiased training. In order to transform standard continual learning to shape-texture debiased continual learning, we propose shape-texture debiased data generation and online shape-texture debiased self-distillation. Experiments on six datasets demonstrate the benefits of our approach in improving generalization and robustness, as well as reducing forgetting. Our analysis on the flatness of the loss landscape explains the advantages. Moreover, our approach can be easily combined with new advanced architectures such as vision transformer, and applied to more challenging scenarios such as exemplar-free continual learning.
Reason from Context with Self-supervised Learning
Nov 23, 2022



A tiny object in the sky cannot be an elephant. Context reasoning is critical in visual recognition, where current inputs need to be interpreted in the light of previous experience and knowledge. To date, research into contextual reasoning in visual recognition has largely proceeded with supervised learning methods. The question of whether contextual knowledge can be captured with self-supervised learning regimes remains under-explored. Here, we established a methodology for context-aware self-supervised learning. We proposed a novel Self-supervised Learning Method for Context Reasoning (SeCo), where the only inputs to SeCo are unlabeled images with multiple objects present in natural scenes. Similar to the distinction between fovea and periphery in human vision, SeCo processes self-proposed target object regions and their contexts separately, and then employs a learnable external memory for retrieving and updating context-relevant target information. To evaluate the contextual associations learned by the computational models, we introduced two evaluation protocols, lift-the-flap and object priming, addressing the problems of "what" and "where" in context reasoning. In both tasks, SeCo outperformed all state-of-the-art (SOTA) self-supervised learning methods by a significant margin. Our network analysis revealed that the external memory in SeCo learns to store prior contextual knowledge, facilitating target identity inference in lift-the-flap task. Moreover, we conducted psychophysics experiments and introduced a Human benchmark in Object Priming dataset (HOP). Our quantitative and qualitative results demonstrate that SeCo approximates human-level performance and exhibits human-like behavior. All our source code and data are publicly available here.
Social Fabric: Tubelet Compositions for Video Relation Detection
Aug 18, 2021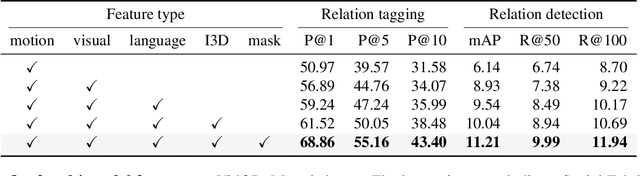


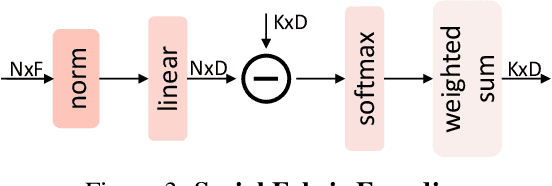
This paper strives to classify and detect the relationship between object tubelets appearing within a video as a <subject-predicate-object> triplet. Where existing works treat object proposals or tubelets as single entities and model their relations a posteriori, we propose to classify and detect predicates for pairs of object tubelets a priori. We also propose Social Fabric: an encoding that represents a pair of object tubelets as a composition of interaction primitives. These primitives are learned over all relations, resulting in a compact representation able to localize and classify relations from the pool of co-occurring object tubelets across all timespans in a video. The encoding enables our two-stage network. In the first stage, we train Social Fabric to suggest proposals that are likely interacting. We use the Social Fabric in the second stage to simultaneously fine-tune and predict predicate labels for the tubelets. Experiments demonstrate the benefit of early video relation modeling, our encoding and the two-stage architecture, leading to a new state-of-the-art on two benchmarks. We also show how the encoding enables query-by-primitive-example to search for spatio-temporal video relations. Code: https://github.com/shanshuo/Social-Fabric.
Frequency-Supervised MR-to-CT Image Synthesis
Jul 19, 2021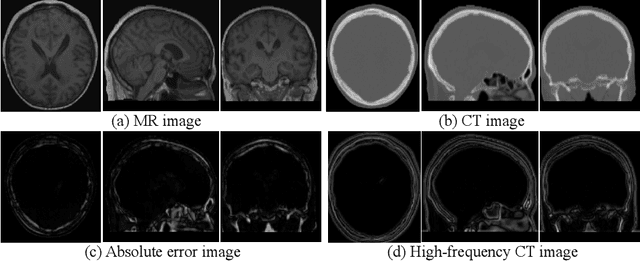

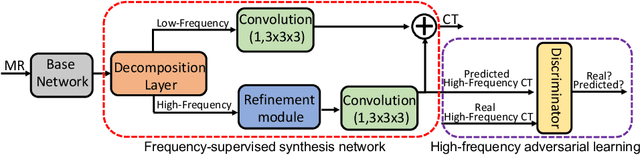

This paper strives to generate a synthetic computed tomography (CT) image from a magnetic resonance (MR) image. The synthetic CT image is valuable for radiotherapy planning when only an MR image is available. Recent approaches have made large strides in solving this challenging synthesis problem with convolutional neural networks that learn a mapping from MR inputs to CT outputs. In this paper, we find that all existing approaches share a common limitation: reconstruction breaks down in and around the high-frequency parts of CT images. To address this common limitation, we introduce frequency-supervised deep networks to explicitly enhance high-frequency MR-to-CT image reconstruction. We propose a frequency decomposition layer that learns to decompose predicted CT outputs into low- and high-frequency components, and we introduce a refinement module to improve high-frequency reconstruction through high-frequency adversarial learning. Experimental results on a new dataset with 45 pairs of 3D MR-CT brain images show the effectiveness and potential of the proposed approach. Code is available at \url{https://github.com/shizenglin/Frequency-Supervised-MR-to-CT-Image-Synthesis}.
On Measuring and Controlling the Spectral Bias of the Deep Image Prior
Jul 02, 2021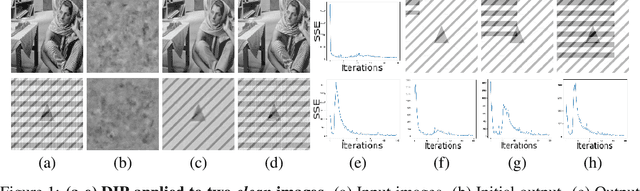

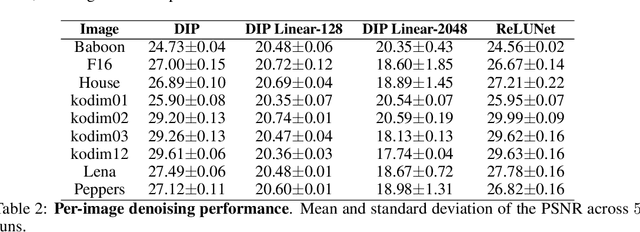
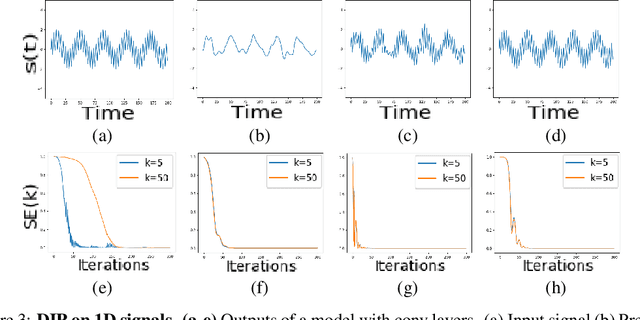
The deep image prior has demonstrated the remarkable ability that untrained networks can address inverse imaging problems, such as denoising, inpainting and super-resolution, by optimizing on just a single degraded image. Despite its promise, it suffers from two limitations. First, it remains unclear how one can control the prior beyond the choice of the network architecture. Second, it requires an oracle to determine when to stop the optimization as the performance degrades after reaching a peak. In this paper, we study the deep image prior from a spectral bias perspective to address these problems. By introducing a frequency-band correspondence measure, we observe that deep image priors for inverse imaging exhibit a spectral bias during optimization, where low-frequency image signals are learned faster and better than high-frequency noise signals. This pinpoints why degraded images can be denoised or inpainted when the optimization is stopped at the right time. Based on our observations, we propose to control the spectral bias in the deep image prior to prevent performance degradation and to speed up optimization convergence. We do so in the two core layer types of inverse imaging networks: the convolution layer and the upsampling layer. We present a Lipschitz-controlled approach for the convolution and a Gaussian-controlled approach for the upsampling layer. We further introduce a stopping criterion to avoid superfluous computation. The experiments on denoising, inpainting and super-resolution show that our method no longer suffers from performance degradation during optimization, relieving us from the need for an oracle criterion to stop early. We further outline a stopping criterion to avoid superfluous computation. Finally, we show that our approach obtains favorable restoration results compared to current approaches, across all tasks.
Unsharp Mask Guided Filtering
Jun 02, 2021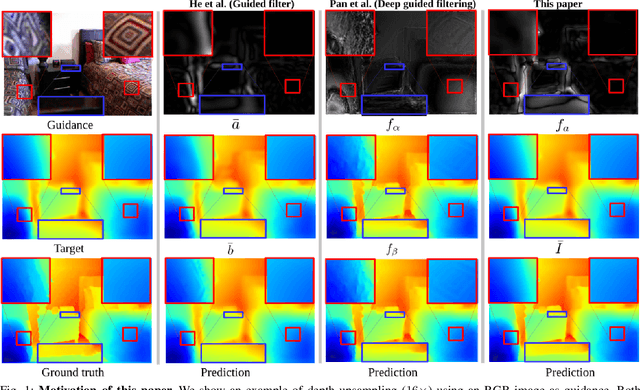
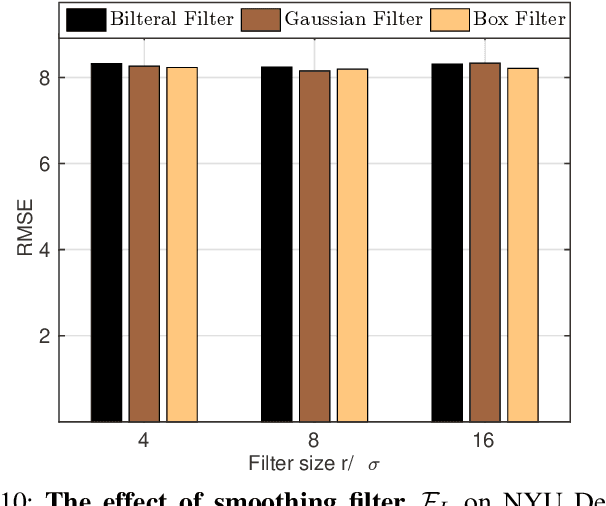
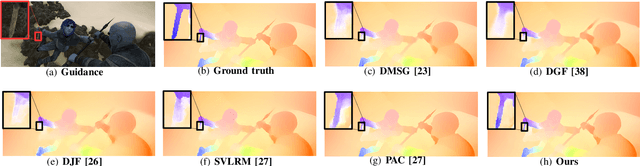
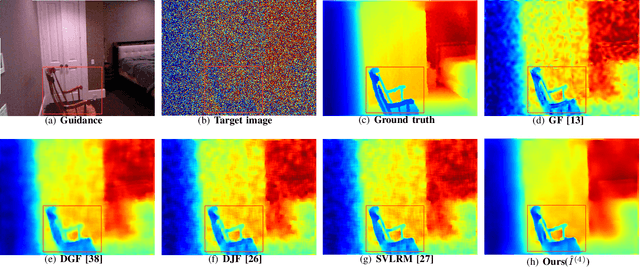
The goal of this paper is guided image filtering, which emphasizes the importance of structure transfer during filtering by means of an additional guidance image. Where classical guided filters transfer structures using hand-designed functions, recent guided filters have been considerably advanced through parametric learning of deep networks. The state-of-the-art leverages deep networks to estimate the two core coefficients of the guided filter. In this work, we posit that simultaneously estimating both coefficients is suboptimal, resulting in halo artifacts and structure inconsistencies. Inspired by unsharp masking, a classical technique for edge enhancement that requires only a single coefficient, we propose a new and simplified formulation of the guided filter. Our formulation enjoys a filtering prior from a low-pass filter and enables explicit structure transfer by estimating a single coefficient. Based on our proposed formulation, we introduce a successive guided filtering network, which provides multiple filtering results from a single network, allowing for a trade-off between accuracy and efficiency. Extensive ablations, comparisons and analysis show the effectiveness and efficiency of our formulation and network, resulting in state-of-the-art results across filtering tasks like upsampling, denoising, and cross-modality filtering. Code is available at \url{https://github.com/shizenglin/Unsharp-Mask-Guided-Filtering}.
Ordered or Orderless: A Revisit for Video based Person Re-Identification
Dec 24, 2019
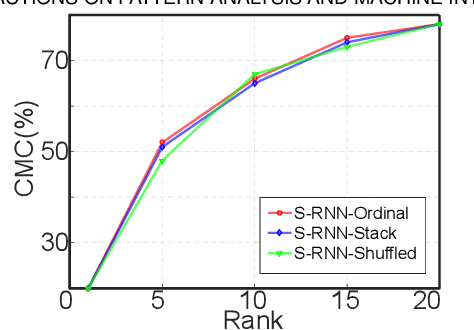
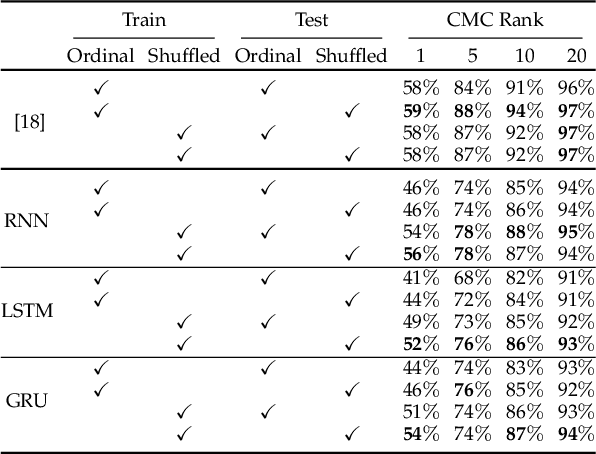
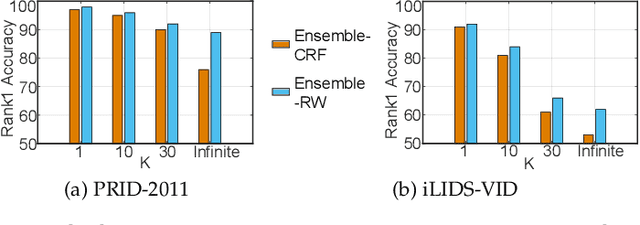
Is recurrent network really necessary for learning a good visual representation for video based person re-identification (VPRe-id)? In this paper, we first show that the common practice of employing recurrent neural networks (RNNs) to aggregate temporal spatial features may not be optimal. Specifically, with a diagnostic analysis, we show that the recurrent structure may not be effective to learn temporal dependencies than what we expected and implicitly yields an orderless representation. Based on this observation, we then present a simple yet surprisingly powerful approach for VPRe-id, where we treat VPRe-id as an efficient orderless ensemble of image based person re-identification problem. More specifically, we divide videos into individual images and re-identify person with ensemble of image based rankers. Under the i.i.d. assumption, we provide an error bound that sheds light upon how could we improve VPRe-id. Our work also presents a promising way to bridge the gap between video and image based person re-identification. Comprehensive experimental evaluations demonstrate that the proposed solution achieves state-of-the-art performances on multiple widely used datasets (iLIDS-VID, PRID 2011, and MARS).
Robust Regression via Deep Negative Correlation Learning
Aug 24, 2019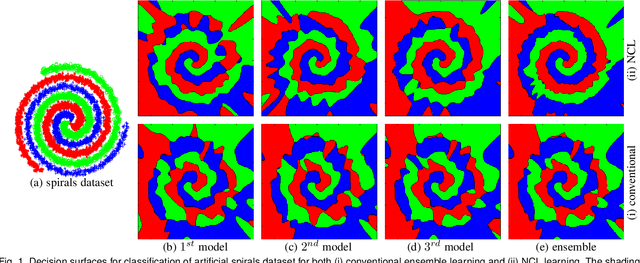
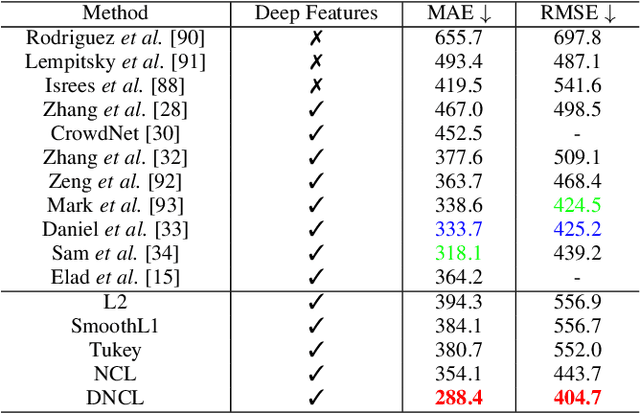
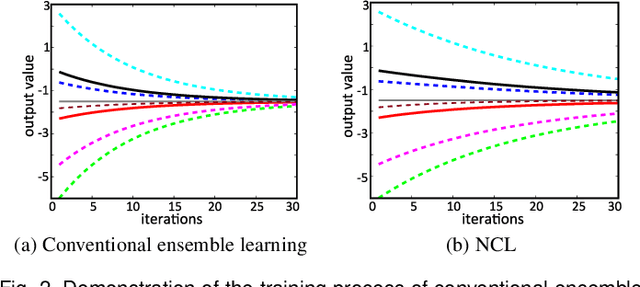
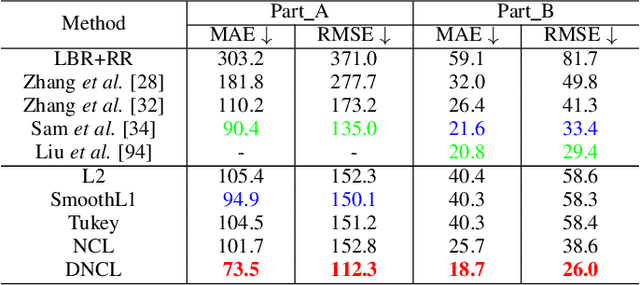
Nonlinear regression has been extensively employed in many computer vision problems (e.g., crowd counting, age estimation, affective computing). Under the umbrella of deep learning, two common solutions exist i) transforming nonlinear regression to a robust loss function which is jointly optimizable with the deep convolutional network, and ii) utilizing ensemble of deep networks. Although some improved performance is achieved, the former may be lacking due to the intrinsic limitation of choosing a single hypothesis and the latter usually suffers from much larger computational complexity. To cope with those issues, we propose to regress via an efficient "divide and conquer" manner. The core of our approach is the generalization of negative correlation learning that has been shown, both theoretically and empirically, to work well for non-deep regression problems. Without extra parameters, the proposed method controls the bias-variance-covariance trade-off systematically and usually yields a deep regression ensemble where each base model is both "accurate" and "diversified". Moreover, we show that each sub-problem in the proposed method has less Rademacher Complexity and thus is easier to optimize. Extensive experiments on several diverse and challenging tasks including crowd counting, personality analysis, age estimation, and image super-resolution demonstrate the superiority over challenging baselines as well as the versatility of the proposed method.