 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRCTs & Human Uplift Studies: Methodological Challenges and Practical Solutions for Frontier AI Evaluation
Mar 11, 2026Human uplift studies - or studies that measure AI effects on human performance relative to a status quo, typically using randomized controlled trial (RCT) methodology - are increasingly used to inform deployment, governance, and safety decisions for frontier AI systems. While the methods underlying these studies are well-established, their interaction with the distinctive properties of frontier AI systems remains underexamined, particularly when results are used to inform high-stakes decisions. We present findings from interviews with 16 expert practitioners with experience conducting human uplift studies in domains including biosecurity, cybersecurity, education, and labor. Across interviews, experts described a recurring tension between standard causal inference assumptions and the object of study itself. Rapidly evolving AI systems, shifting baselines, heterogeneous and changing user proficiency, and porous real-world settings strain assumptions underlying internal, external, and construct validity, complicating the interpretation and appropriate use of uplift evidence. We synthesize these challenges across key stages of the human uplift research lifecycle and map them to practitioner-reported solutions, clarifying both the limits and the appropriate uses of evidence from human uplift studies in high-stakes decision-making.
Detecting East Asian Prejudice on Social Media
May 08, 2020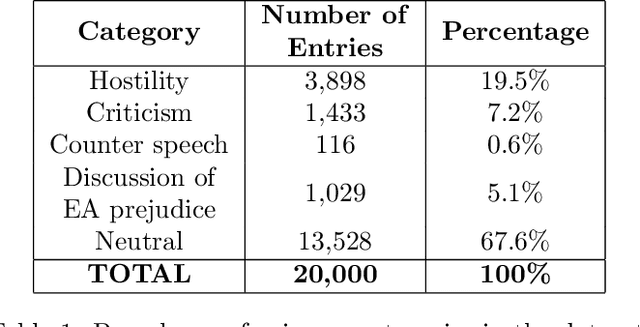
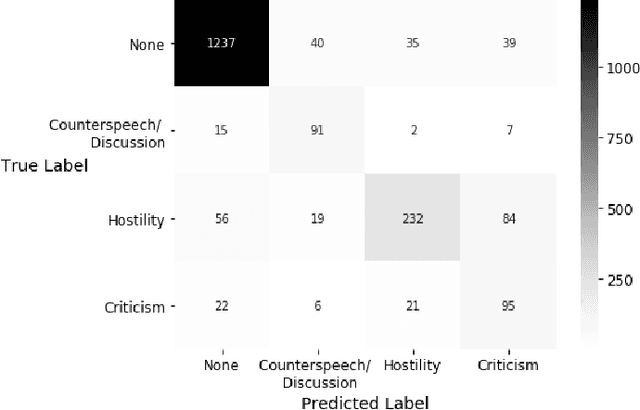
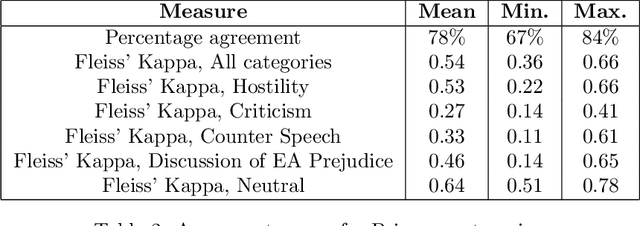
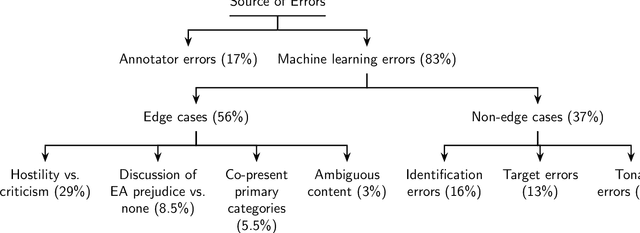
The outbreak of COVID-19 has transformed societies across the world as governments tackle the health, economic and social costs of the pandemic. It has also raised concerns about the spread of hateful language and prejudice online, especially hostility directed against East Asia. In this paper we report on the creation of a classifier that detects and categorizes social media posts from Twitter into four classes: Hostility against East Asia, Criticism of East Asia, Meta-discussions of East Asian prejudice and a neutral class. The classifier achieves an F1 score of 0.83 across all four classes. We provide our final model (coded in Python), as well as a new 20,000 tweet training dataset used to make the classifier, two analyses of hashtags associated with East Asian prejudice and the annotation codebook. The classifier can be implemented by other researchers, assisting with both online content moderation processes and further research into the dynamics, prevalence and impact of East Asian prejudice online during this global pandemic.