 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrive-KD: Multi-Teacher Distillation for VLMs in Autonomous Driving
Jan 29, 2026Autonomous driving is an important and safety-critical task, and recent advances in LLMs/VLMs have opened new possibilities for reasoning and planning in this domain. However, large models demand substantial GPU memory and exhibit high inference latency, while conventional supervised fine-tuning (SFT) often struggles to bridge the capability gaps of small models. To address these limitations, we propose Drive-KD, a framework that decomposes autonomous driving into a "perception-reasoning-planning" triad and transfers these capabilities via knowledge distillation. We identify layer-specific attention as the distillation signal to construct capability-specific single-teacher models that outperform baselines. Moreover, we unify these single-teacher settings into a multi-teacher distillation framework and introduce asymmetric gradient projection to mitigate cross-capability gradient conflicts. Extensive evaluations validate the generalization of our method across diverse model families and scales. Experiments show that our distilled InternVL3-1B model, with ~42 times less GPU memory and ~11.4 times higher throughput, achieves better overall performance than the pretrained 78B model from the same family on DriveBench, and surpasses GPT-5.1 on the planning dimension, providing insights toward efficient autonomous driving VLMs.
AutoDriDM: An Explainable Benchmark for Decision-Making of Vision-Language Models in Autonomous Driving
Jan 21, 2026Autonomous driving is a highly challenging domain that requires reliable perception and safe decision-making in complex scenarios. Recent vision-language models (VLMs) demonstrate reasoning and generalization abilities, opening new possibilities for autonomous driving; however, existing benchmarks and metrics overemphasize perceptual competence and fail to adequately assess decision-making processes. In this work, we present AutoDriDM, a decision-centric, progressive benchmark with 6,650 questions across three dimensions - Object, Scene, and Decision. We evaluate mainstream VLMs to delineate the perception-to-decision capability boundary in autonomous driving, and our correlation analysis reveals weak alignment between perception and decision-making performance. We further conduct explainability analyses of models' reasoning processes, identifying key failure modes such as logical reasoning errors, and introduce an analyzer model to automate large-scale annotation. AutoDriDM bridges the gap between perception-centered and decision-centered evaluation, providing guidance toward safer and more reliable VLMs for real-world autonomous driving.
RaTE: a Reproducible automatic Taxonomy Evaluation by Filling the Gap
Jul 19, 2023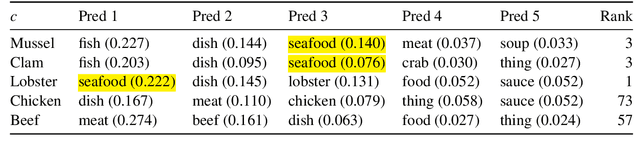
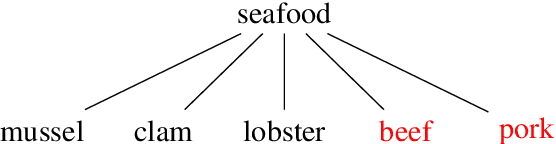
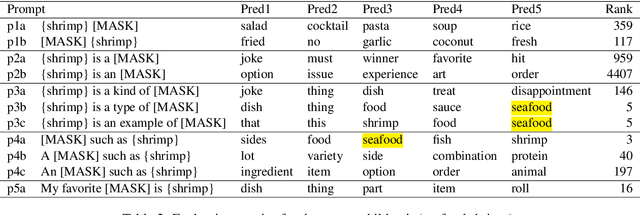

Taxonomies are an essential knowledge representation, yet most studies on automatic taxonomy construction (ATC) resort to manual evaluation to score proposed algorithms. We argue that automatic taxonomy evaluation (ATE) is just as important as taxonomy construction. We propose RaTE, an automatic label-free taxonomy scoring procedure, which relies on a large pre-trained language model. We apply our evaluation procedure to three state-of-the-art ATC algorithms with which we built seven taxonomies from the Yelp domain, and show that 1) RaTE correlates well with human judgments and 2) artificially degrading a taxonomy leads to decreasing RaTE score.