 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing GPU Resilience and Impact on AI/HPC Systems
Mar 14, 2025In this study, we characterize GPU failures in Delta, the current large-scale AI system with over 600 petaflops of peak compute throughput. The system comprises GPU and non-GPU nodes with modern AI accelerators, such as NVIDIA A40, A100, and H100 GPUs. The study uses two and a half years of data on GPU errors. We evaluate the resilience of GPU hardware components to determine the vulnerability of different GPU components to failure and their impact on the GPU and node availability. We measure the key propagation paths in GPU hardware, GPU interconnect (NVLink), and GPU memory. Finally, we evaluate the impact of the observed GPU errors on user jobs. Our key findings are: (i) Contrary to common beliefs, GPU memory is over 30x more reliable than GPU hardware in terms of MTBE (mean time between errors). (ii) The newly introduced GSP (GPU System Processor) is the most vulnerable GPU hardware component. (iii) NVLink errors did not always lead to user job failure, and we attribute it to the underlying error detection and retry mechanisms employed. (iv) We show multiple examples of hardware errors originating from one of the key GPU hardware components, leading to application failure. (v) We project the impact of GPU node availability on larger scales with emulation and find that significant overprovisioning between 5-20% would be necessary to handle GPU failures. If GPU availability were improved to 99.9%, the overprovisioning would be reduced by 4x.
Efficient Interactive LLM Serving with Proxy Model-based Sequence Length Prediction
Apr 12, 2024Large language models (LLMs) have been driving a new wave of interactive AI applications across numerous domains. However, efficiently serving LLM inference requests is challenging due to their unpredictable execution times originating from the autoregressive nature of generative models. Existing LLM serving systems exploit first-come-first-serve (FCFS) scheduling, suffering from head-of-line blocking issues. To address the non-deterministic nature of LLMs and enable efficient interactive LLM serving, we present a speculative shortest-job-first (SSJF) scheduler that uses a light proxy model to predict LLM output sequence lengths. Our open-source SSJF implementation does not require changes to memory management or batching strategies. Evaluations on real-world datasets and production workload traces show that SSJF reduces average job completion times by 30.5-39.6% and increases throughput by 2.2-3.6x compared to FCFS schedulers, across no batching, dynamic batching, and continuous batching settings.
BayesPerf: Minimizing Performance Monitoring Errors Using Bayesian Statistics
Feb 22, 2021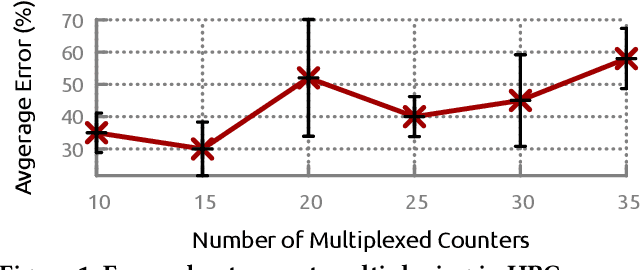
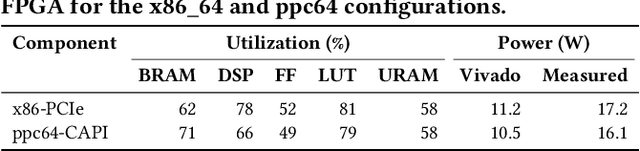
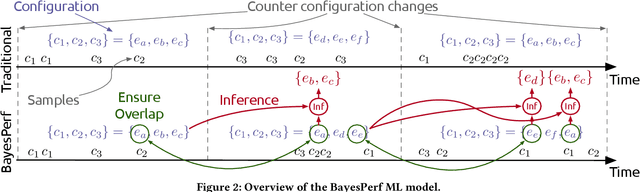
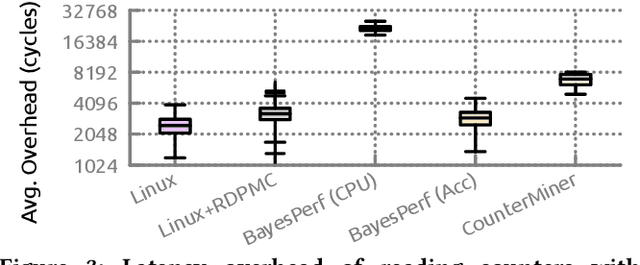
Hardware performance counters (HPCs) that measure low-level architectural and microarchitectural events provide dynamic contextual information about the state of the system. However, HPC measurements are error-prone due to non determinism (e.g., undercounting due to event multiplexing, or OS interrupt-handling behaviors). In this paper, we present BayesPerf, a system for quantifying uncertainty in HPC measurements by using a domain-driven Bayesian model that captures microarchitectural relationships between HPCs to jointly infer their values as probability distributions. We provide the design and implementation of an accelerator that allows for low-latency and low-power inference of the BayesPerf model for x86 and ppc64 CPUs. BayesPerf reduces the average error in HPC measurements from 40.1% to 7.6% when events are being multiplexed. The value of BayesPerf in real-time decision-making is illustrated with a simple example of scheduling of PCIe transfers.
Live Forensics for Distributed Storage Systems
Jul 24, 2019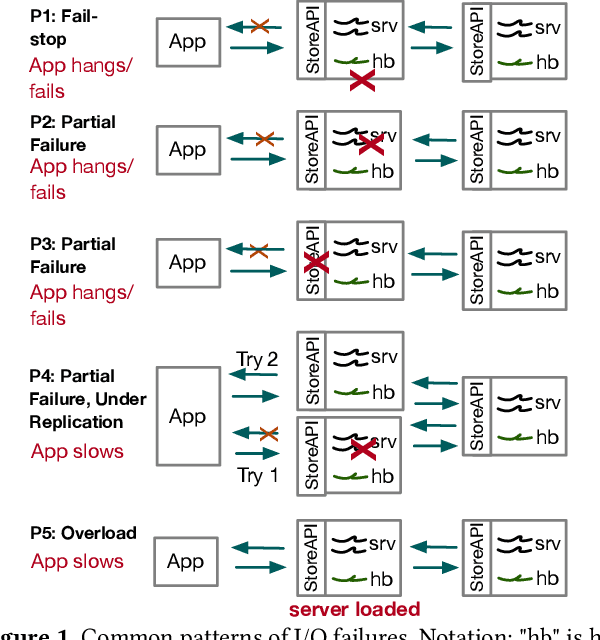
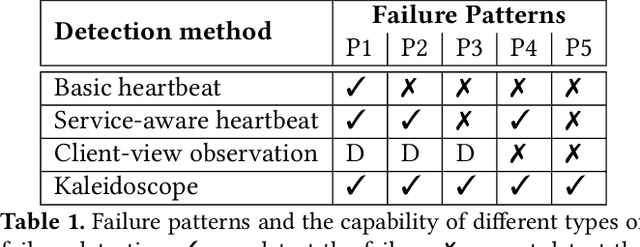

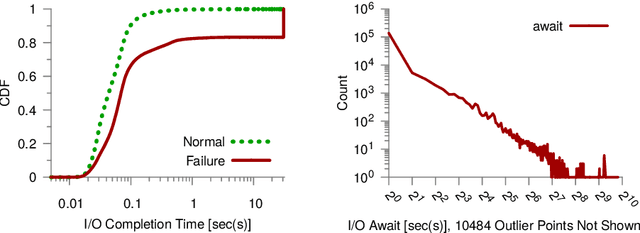
We present Kaleidoscope an innovative system that supports live forensics for application performance problems caused by either individual component failures or resource contention issues in large-scale distributed storage systems. The design of Kaleidoscope is driven by our study of I/O failures observed in a peta-scale storage system anonymized as PetaStore. Kaleidoscope is built on three key features: 1) using temporal and spatial differential observability for end-to-end performance monitoring of I/O requests, 2) modeling the health of storage components as a stochastic process using domain-guided functions that accounts for path redundancy and uncertainty in measurements, and, 3) observing differences in reliability and performance metrics between similar types of healthy and unhealthy components to attribute the most likely root causes. We deployed Kaleidoscope on PetaStore and our evaluation shows that Kaleidoscope can run live forensics at 5-minute intervals and pinpoint the root causes of 95.8% of real-world performance issues, with negligible monitoring overhead.
ML-based Fault Injection for Autonomous Vehicles: A Case for Bayesian Fault Injection
Jul 01, 2019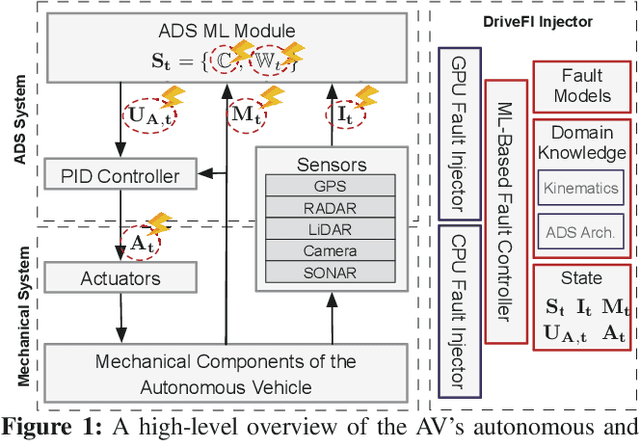
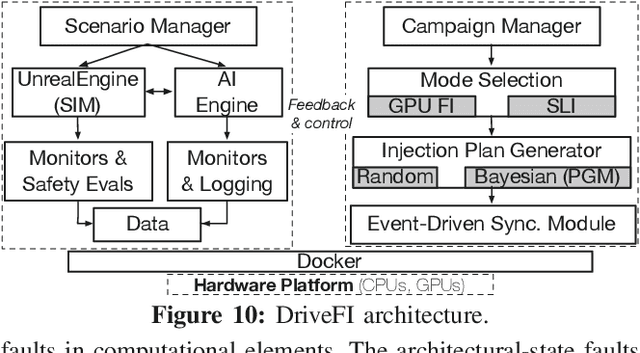
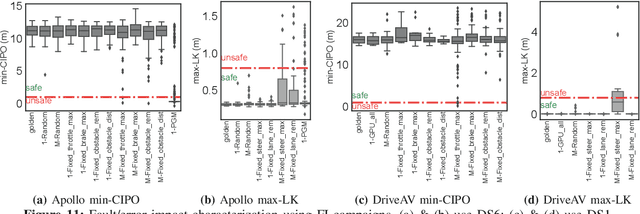
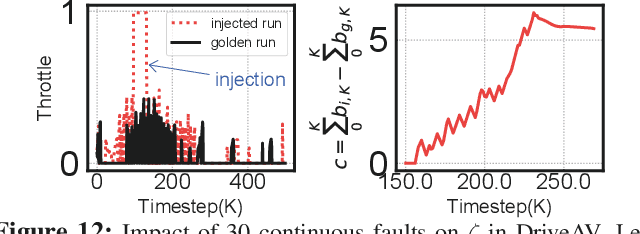
The safety and resilience of fully autonomous vehicles (AVs) are of significant concern, as exemplified by several headline-making accidents. While AV development today involves verification, validation, and testing, end-to-end assessment of AV systems under accidental faults in realistic driving scenarios has been largely unexplored. This paper presents DriveFI, a machine learning-based fault injection engine, which can mine situations and faults that maximally impact AV safety, as demonstrated on two industry-grade AV technology stacks (from NVIDIA and Baidu). For example, DriveFI found 561 safety-critical faults in less than 4 hours. In comparison, random injection experiments executed over several weeks could not find any safety-critical faults