 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToken Pruning using a Lightweight Background Aware Vision Transformer
Oct 12, 2024



High runtime memory and high latency puts significant constraint on Vision Transformer training and inference, especially on edge devices. Token pruning reduces the number of input tokens to the ViT based on importance criteria of each token. We present a Background Aware Vision Transformer (BAViT) model, a pre-processing block to object detection models like DETR/YOLOS aimed to reduce runtime memory and increase throughput by using a novel approach to identify background tokens in the image. The background tokens can be pruned completely or partially before feeding to a ViT based object detector. We use the semantic information provided by segmentation map and/or bounding box annotation to train a few layers of ViT to classify tokens to either foreground or background. Using 2 layers and 10 layers of BAViT, background and foreground tokens can be separated with 75% and 88% accuracy on VOC dataset and 71% and 80% accuracy on COCO dataset respectively. We show a 2 layer BAViT-small model as pre-processor to YOLOS can increase the throughput by 30% - 40% with a mAP drop of 3% without any sparse fine-tuning and 2% with sparse fine-tuning. Our approach is specifically targeted for Edge AI use cases.
ActNAS : Generating Efficient YOLO Models using Activation NAS
Oct 11, 2024Activation functions introduce non-linearity into Neural Networks, enabling them to learn complex patterns. Different activation functions vary in speed and accuracy, ranging from faster but less accurate options like ReLU to slower but more accurate functions like SiLU or SELU. Typically, same activation function is used throughout an entire model architecture. In this paper, we conduct a comprehensive study on the effects of using mixed activation functions in YOLO-based models, evaluating their impact on latency, memory usage, and accuracy across CPU, NPU, and GPU edge devices. We also propose a novel approach that leverages Neural Architecture Search (NAS) to design YOLO models with optimized mixed activation functions.The best model generated through this method demonstrates a slight improvement in mean Average Precision (mAP) compared to baseline model (SiLU), while it is 22.28% faster and consumes 64.15% less memory on the reference NPU device.
MCUBench: A Benchmark of Tiny Object Detectors on MCUs
Sep 27, 2024We introduce MCUBench, a benchmark featuring over 100 YOLO-based object detection models evaluated on the VOC dataset across seven different MCUs. This benchmark provides detailed data on average precision, latency, RAM, and Flash usage for various input resolutions and YOLO-based one-stage detectors. By conducting a controlled comparison with a fixed training pipeline, we collect comprehensive performance metrics. Our Pareto-optimal analysis shows that integrating modern detection heads and training techniques allows various YOLO architectures, including legacy models like YOLOv3, to achieve a highly efficient tradeoff between mean Average Precision (mAP) and latency. MCUBench serves as a valuable tool for benchmarking the MCU performance of contemporary object detectors and aids in model selection based on specific constraints.
QGen: On the Ability to Generalize in Quantization Aware Training
Apr 19, 2024



Quantization lowers memory usage, computational requirements, and latency by utilizing fewer bits to represent model weights and activations. In this work, we investigate the generalization properties of quantized neural networks, a characteristic that has received little attention despite its implications on model performance. In particular, first, we develop a theoretical model for quantization in neural networks and demonstrate how quantization functions as a form of regularization. Second, motivated by recent work connecting the sharpness of the loss landscape and generalization, we derive an approximate bound for the generalization of quantized models conditioned on the amount of quantization noise. We then validate our hypothesis by experimenting with over 2000 models trained on CIFAR-10, CIFAR-100, and ImageNet datasets on convolutional and transformer-based models.
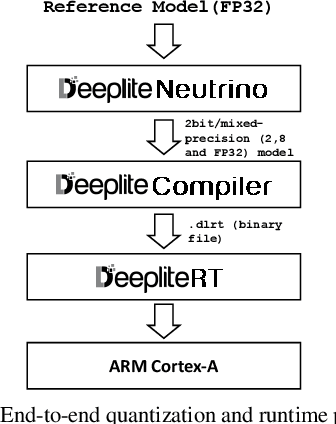
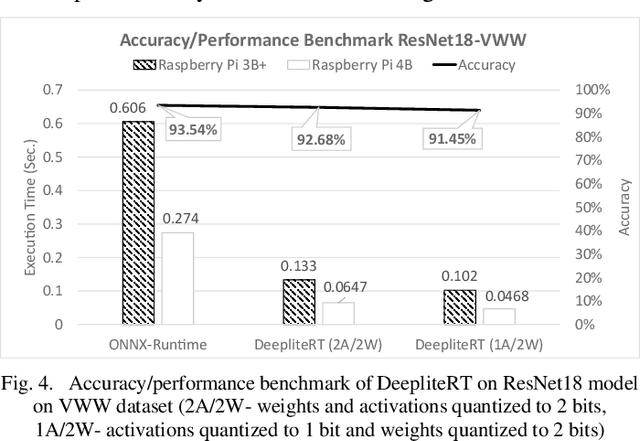
DeepliteRT: Computer Vision at the Edge
Sep 19, 2023



The proliferation of edge devices has unlocked unprecedented opportunities for deep learning model deployment in computer vision applications. However, these complex models require considerable power, memory and compute resources that are typically not available on edge platforms. Ultra low-bit quantization presents an attractive solution to this problem by scaling down the model weights and activations from 32-bit to less than 8-bit. We implement highly optimized ultra low-bit convolution operators for ARM-based targets that outperform existing methods by up to 4.34x. Our operator is implemented within Deeplite Runtime (DeepliteRT), an end-to-end solution for the compilation, tuning, and inference of ultra low-bit models on ARM devices. Compiler passes in DeepliteRT automatically convert a fake-quantized model in full precision to a compact ultra low-bit representation, easing the process of quantized model deployment on commodity hardware. We analyze the performance of DeepliteRT on classification and detection models against optimized 32-bit floating-point, 8-bit integer, and 2-bit baselines, achieving significant speedups of up to 2.20x, 2.33x and 2.17x, respectively.
DeepGEMM: Accelerated Ultra Low-Precision Inference on CPU Architectures using Lookup Tables
Apr 18, 2023



A lot of recent progress has been made in ultra low-bit quantization, promising significant improvements in latency, memory footprint and energy consumption on edge devices. Quantization methods such as Learned Step Size Quantization can achieve model accuracy that is comparable to full-precision floating-point baselines even with sub-byte quantization. However, it is extremely challenging to deploy these ultra low-bit quantized models on mainstream CPU devices because commodity SIMD (Single Instruction, Multiple Data) hardware typically supports no less than 8-bit precision. To overcome this limitation, we propose DeepGEMM, a lookup table based approach for the execution of ultra low-precision convolutional neural networks on SIMD hardware. The proposed method precomputes all possible products of weights and activations, stores them in a lookup table, and efficiently accesses them at inference time to avoid costly multiply-accumulate operations. Our 2-bit implementation outperforms corresponding 8-bit integer kernels in the QNNPACK framework by up to 1.74x on x86 platforms.
Accelerating Deep Learning Model Inference on Arm CPUs with Ultra-Low Bit Quantization and Runtime
Jul 18, 2022
Deep Learning has been one of the most disruptive technological advancements in recent times. The high performance of deep learning models comes at the expense of high computational, storage and power requirements. Sensing the immediate need for accelerating and compressing these models to improve on-device performance, we introduce Deeplite Neutrino for production-ready optimization of the models and Deeplite Runtime for deployment of ultra-low bit quantized models on Arm-based platforms. We implement low-level quantization kernels for Armv7 and Armv8 architectures enabling deployment on the vast array of 32-bit and 64-bit Arm-based devices. With efficient implementations using vectorization, parallelization, and tiling, we realize speedups of up to 2x and 2.2x compared to TensorFlow Lite with XNNPACK backend on classification and detection models, respectively. We also achieve significant speedups of up to 5x and 3.2x compared to ONNX Runtime for classification and detection models, respectively.
QReg: On Regularization Effects of Quantization
Jun 27, 2022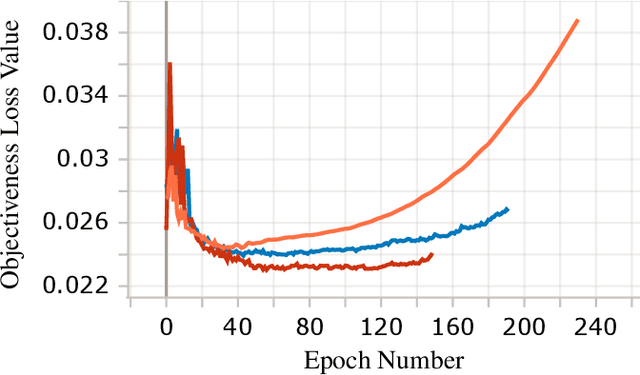
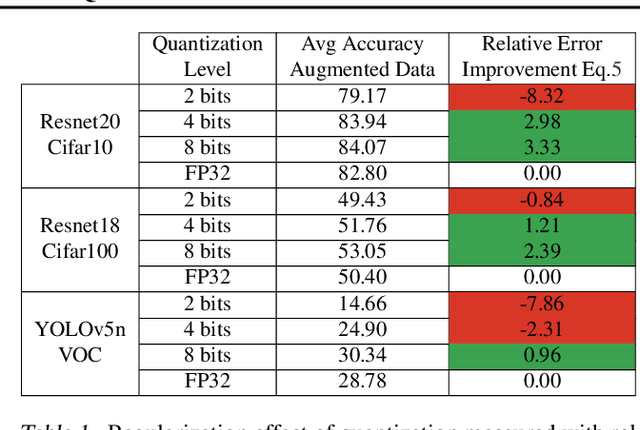
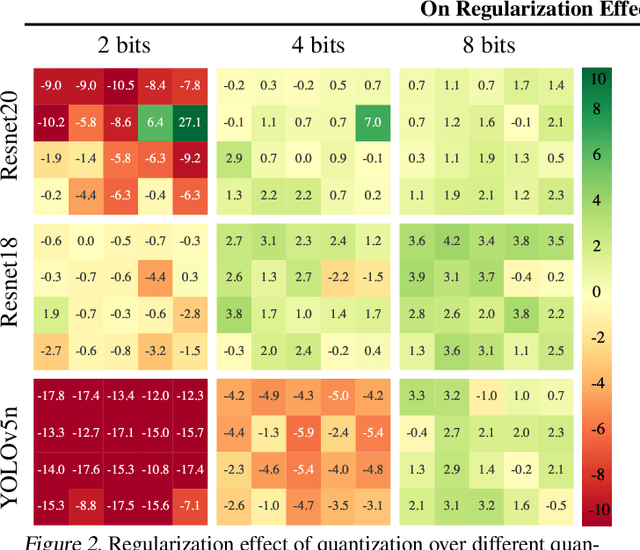
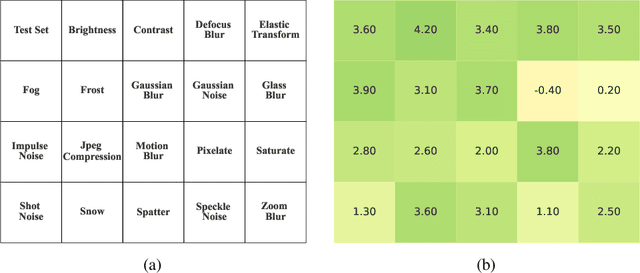
In this paper we study the effects of quantization in DNN training. We hypothesize that weight quantization is a form of regularization and the amount of regularization is correlated with the quantization level (precision). We confirm our hypothesis by providing analytical study and empirical results. By modeling weight quantization as a form of additive noise to weights, we explore how this noise propagates through the network at training time. We then show that the magnitude of this noise is correlated with the level of quantization. To confirm our analytical study, we performed an extensive list of experiments summarized in this paper in which we show that the regularization effects of quantization can be seen in various vision tasks and models, over various datasets. Based on our study, we propose that 8-bit quantization provides a reliable form of regularization in different vision tasks and models.
On Causal Inference for Data-free Structured Pruning
Dec 19, 2021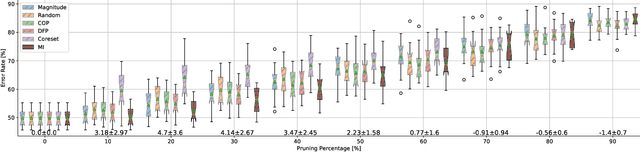
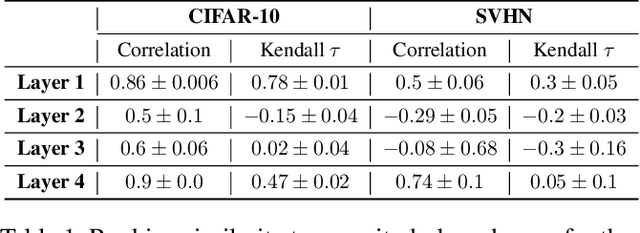
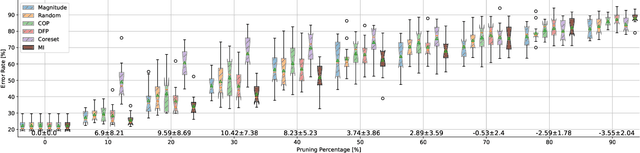

Neural networks (NNs) are making a large impact both on research and industry. Nevertheless, as NNs' accuracy increases, it is followed by an expansion in their size, required number of compute operations and energy consumption. Increase in resource consumption results in NNs' reduced adoption rate and real-world deployment impracticality. Therefore, NNs need to be compressed to make them available to a wider audience and at the same time decrease their runtime costs. In this work, we approach this challenge from a causal inference perspective, and we propose a scoring mechanism to facilitate structured pruning of NNs. The approach is based on measuring mutual information under a maximum entropy perturbation, sequentially propagated through the NN. We demonstrate the method's performance on two datasets and various NNs' sizes, and we show that our approach achieves competitive performance under challenging conditions.
Deeplite Neutrino: An End-to-End Framework for Constrained Deep Learning Model Optimization
Jan 13, 2021
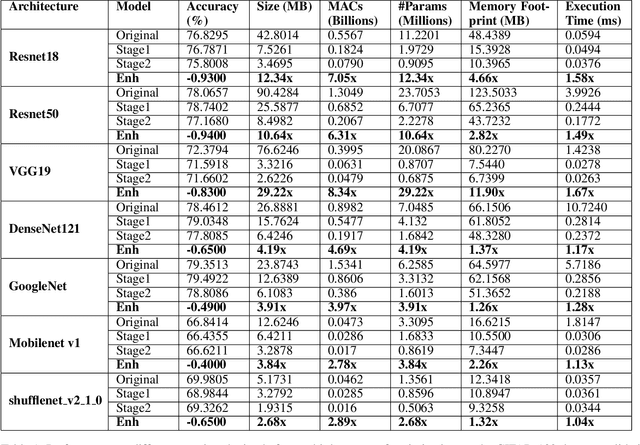
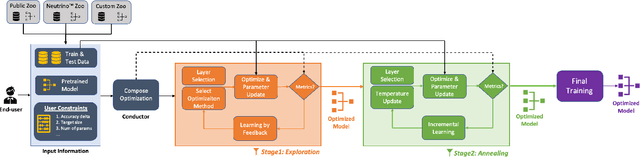
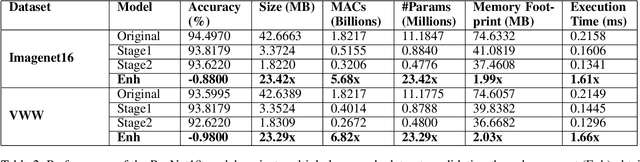
Designing deep learning-based solutions is becoming a race for training deeper models with a greater number of layers. While a large-size deeper model could provide competitive accuracy, it creates a lot of logistical challenges and unreasonable resource requirements during development and deployment. This has been one of the key reasons for deep learning models not being excessively used in various production environments, especially in edge devices. There is an immediate requirement for optimizing and compressing these deep learning models, to enable on-device intelligence. In this research, we introduce a black-box framework, Deeplite Neutrino for production-ready optimization of deep learning models. The framework provides an easy mechanism for the end-users to provide constraints such as a tolerable drop in accuracy or target size of the optimized models, to guide the whole optimization process. The framework is easy to include in an existing production pipeline and is available as a Python Package, supporting PyTorch and Tensorflow libraries. The optimization performance of the framework is shown across multiple benchmark datasets and popular deep learning models. Further, the framework is currently used in production and the results and testimonials from several clients are summarized.