 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Curious Price of Distributional Robustness in Reinforcement Learning with a Generative Model
May 26, 2023This paper investigates model robustness in reinforcement learning (RL) to reduce the sim-to-real gap in practice. We adopt the framework of distributionally robust Markov decision processes (RMDPs), aimed at learning a policy that optimizes the worst-case performance when the deployed environment falls within a prescribed uncertainty set around the nominal MDP. Despite recent efforts, the sample complexity of RMDPs remained mostly unsettled regardless of the uncertainty set in use. It was unclear if distributional robustness bears any statistical consequences when benchmarked against standard RL. Assuming access to a generative model that draws samples based on the nominal MDP, we characterize the sample complexity of RMDPs when the uncertainty set is specified via either the total variation (TV) distance or $\chi^2$ divergence. The algorithm studied here is a model-based method called {\em distributionally robust value iteration}, which is shown to be near-optimal for the full range of uncertainty levels. Somewhat surprisingly, our results uncover that RMDPs are not necessarily easier or harder to learn than standard MDPs. The statistical consequence incurred by the robustness requirement depends heavily on the size and shape of the uncertainty set: in the case w.r.t.~the TV distance, the minimax sample complexity of RMDPs is always smaller than that of standard MDPs; in the case w.r.t.~the $\chi^2$ divergence, the sample complexity of RMDPs can often far exceed the standard MDP counterpart.
Approximate message passing from random initialization with applications to $\mathbb{Z}_{2}$ synchronization
Feb 07, 2023
This paper is concerned with the problem of reconstructing an unknown rank-one matrix with prior structural information from noisy observations. While computing the Bayes-optimal estimator seems intractable in general due to its nonconvex nature, Approximate Message Passing (AMP) emerges as an efficient first-order method to approximate the Bayes-optimal estimator. However, the theoretical underpinnings of AMP remain largely unavailable when it starts from random initialization, a scheme of critical practical utility. Focusing on a prototypical model called $\mathbb{Z}_{2}$ synchronization, we characterize the finite-sample dynamics of AMP from random initialization, uncovering its rapid global convergence. Our theory provides the first non-asymptotic characterization of AMP in this model without requiring either an informative initialization (e.g., spectral initialization) or sample splitting.
Minimax-Optimal Multi-Agent RL in Zero-Sum Markov Games With a Generative Model
Aug 22, 2022This paper is concerned with two-player zero-sum Markov games -- arguably the most basic setting in multi-agent reinforcement learning -- with the goal of learning a Nash equilibrium (NE) sample-optimally. All prior results suffer from at least one of the two obstacles: the curse of multiple agents and the barrier of long horizon, regardless of the sampling protocol in use. We take a step towards settling this problem, assuming access to a flexible sampling mechanism: the generative model. Focusing on non-stationary finite-horizon Markov games, we develop a learning algorithm $\mathsf{Nash}\text{-}\mathsf{Q}\text{-}\mathsf{FTRL}$ and an adaptive sampling scheme that leverage the optimism principle in adversarial learning (particularly the Follow-the-Regularized-Leader (FTRL) method), with a delicate design of bonus terms that ensure certain decomposability under the FTRL dynamics. Our algorithm learns an $\varepsilon$-approximate Markov NE policy using $$ \widetilde{O}\bigg( \frac{H^4 S(A+B)}{\varepsilon^2} \bigg) $$ samples, where $S$ is the number of states, $H$ is the horizon, and $A$ (resp.~$B$) denotes the number of actions for the max-player (resp.~min-player). This is nearly un-improvable in a minimax sense. Along the way, we derive a refined regret bound for FTRL that makes explicit the role of variance-type quantities, which might be of independent interest.
A Non-Asymptotic Framework for Approximate Message Passing in Spiked Models
Aug 05, 2022Approximate message passing (AMP) emerges as an effective iterative paradigm for solving high-dimensional statistical problems. However, prior AMP theory -- which focused mostly on high-dimensional asymptotics -- fell short of predicting the AMP dynamics when the number of iterations surpasses $o\big(\frac{\log n}{\log\log n}\big)$ (with $n$ the problem dimension). To address this inadequacy, this paper develops a non-asymptotic framework for understanding AMP in spiked matrix estimation. Built upon new decomposition of AMP updates and controllable residual terms, we lay out an analysis recipe to characterize the finite-sample behavior of AMP in the presence of an independent initialization, which is further generalized to allow for spectral initialization. As two concrete consequences of the proposed analysis recipe: (i) when solving $\mathbb{Z}_2$ synchronization, we predict the behavior of spectrally initialized AMP for up to $O\big(\frac{n}{\mathrm{poly}\log n}\big)$ iterations, showing that the algorithm succeeds without the need of a subsequent refinement stage (as conjectured recently by \citet{celentano2021local}); (ii) we characterize the non-asymptotic behavior of AMP in sparse PCA (in the spiked Wigner model) for a broad range of signal-to-noise ratio.
Mitigating multiple descents: A model-agnostic framework for risk monotonization
May 25, 2022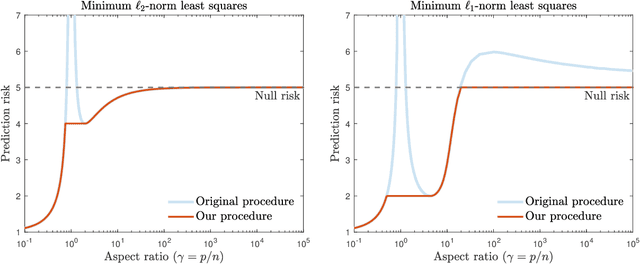
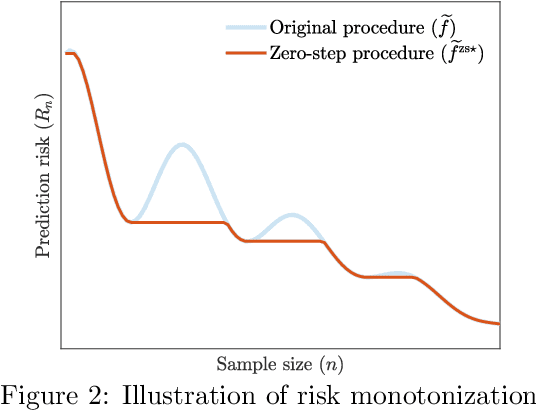
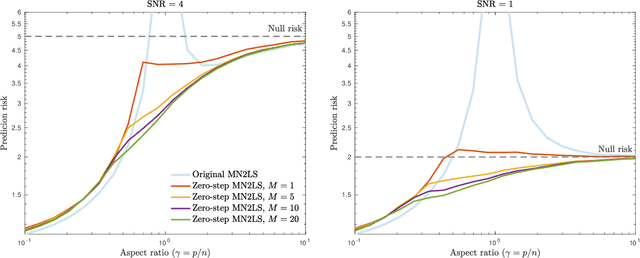
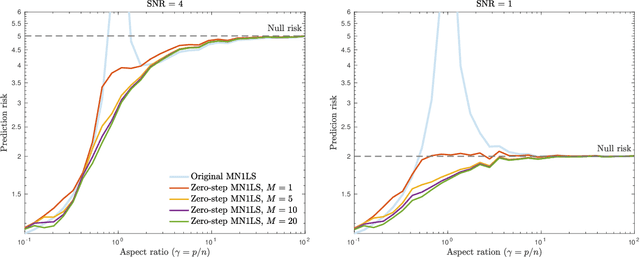
Recent empirical and theoretical analyses of several commonly used prediction procedures reveal a peculiar risk behavior in high dimensions, referred to as double/multiple descent, in which the asymptotic risk is a non-monotonic function of the limiting aspect ratio of the number of features or parameters to the sample size. To mitigate this undesirable behavior, we develop a general framework for risk monotonization based on cross-validation that takes as input a generic prediction procedure and returns a modified procedure whose out-of-sample prediction risk is, asymptotically, monotonic in the limiting aspect ratio. As part of our framework, we propose two data-driven methodologies, namely zero- and one-step, that are akin to bagging and boosting, respectively, and show that, under very mild assumptions, they provably achieve monotonic asymptotic risk behavior. Our results are applicable to a broad variety of prediction procedures and loss functions, and do not require a well-specified (parametric) model. We exemplify our framework with concrete analyses of the minimum $\ell_2$, $\ell_1$-norm least squares prediction procedures. As one of the ingredients in our analysis, we also derive novel additive and multiplicative forms of oracle risk inequalities for split cross-validation that are of independent interest.
Settling the Sample Complexity of Model-Based Offline Reinforcement Learning
Apr 11, 2022
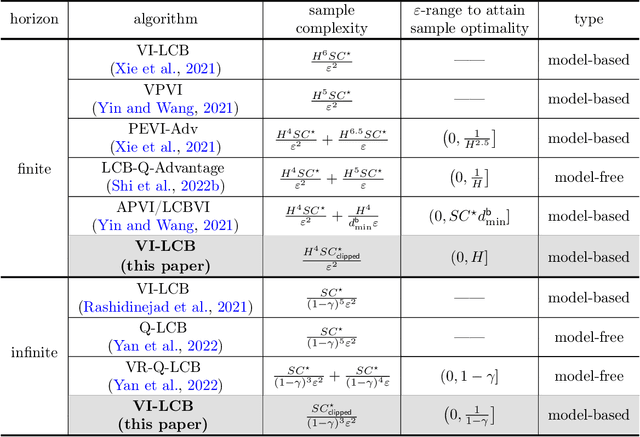
This paper is concerned with offline reinforcement learning (RL), which learns using pre-collected data without further exploration. Effective offline RL would be able to accommodate distribution shift and limited data coverage. However, prior algorithms or analyses either suffer from suboptimal sample complexities or incur high burn-in cost to reach sample optimality, thus posing an impediment to efficient offline RL in sample-starved applications. We demonstrate that the model-based (or "plug-in") approach achieves minimax-optimal sample complexity without burn-in cost for tabular Markov decision processes (MDPs). Concretely, consider a finite-horizon (resp. $\gamma$-discounted infinite-horizon) MDP with $S$ states and horizon $H$ (resp. effective horizon $\frac{1}{1-\gamma}$), and suppose the distribution shift of data is reflected by some single-policy clipped concentrability coefficient $C^{\star}_{\text{clipped}}$. We prove that model-based offline RL yields $\varepsilon$-accuracy with a sample complexity of \[ \begin{cases} \frac{H^{4}SC_{\text{clipped}}^{\star}}{\varepsilon^{2}} & (\text{finite-horizon MDPs}) \frac{SC_{\text{clipped}}^{\star}}{(1-\gamma)^{3}\varepsilon^{2}} & (\text{infinite-horizon MDPs}) \end{cases} \] up to log factor, which is minimax optimal for the entire $\varepsilon$-range. Our algorithms are "pessimistic" variants of value iteration with Bernstein-style penalties, and do not require sophisticated variance reduction.
Pessimistic Q-Learning for Offline Reinforcement Learning: Towards Optimal Sample Complexity
Feb 28, 2022

Offline or batch reinforcement learning seeks to learn a near-optimal policy using history data without active exploration of the environment. To counter the insufficient coverage and sample scarcity of many offline datasets, the principle of pessimism has been recently introduced to mitigate high bias of the estimated values. While pessimistic variants of model-based algorithms (e.g., value iteration with lower confidence bounds) have been theoretically investigated, their model-free counterparts -- which do not require explicit model estimation -- have not been adequately studied, especially in terms of sample efficiency. To address this inadequacy, we study a pessimistic variant of Q-learning in the context of finite-horizon Markov decision processes, and characterize its sample complexity under the single-policy concentrability assumption which does not require the full coverage of the state-action space. In addition, a variance-reduced pessimistic Q-learning algorithm is proposed to achieve near-optimal sample complexity. Altogether, this work highlights the efficiency of model-free algorithms in offline RL when used in conjunction with pessimism and variance reduction.
Minimum $\ell_{1}$-norm interpolators: Precise asymptotics and multiple descent
Oct 18, 2021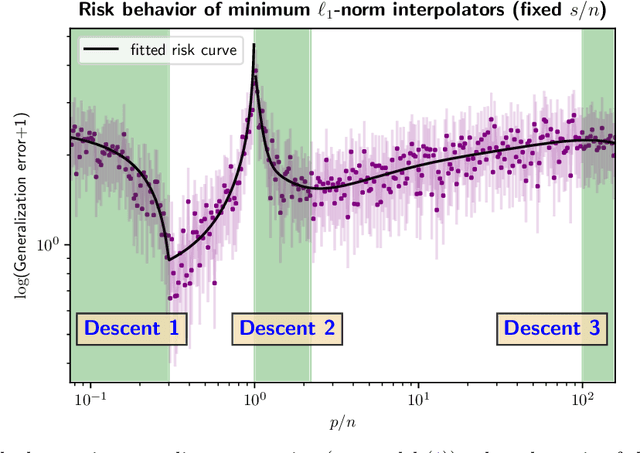
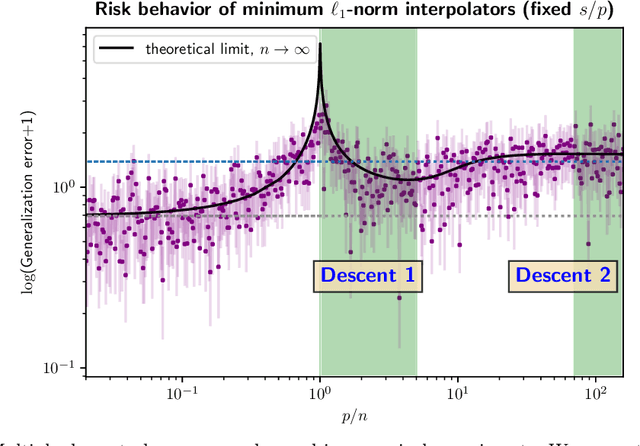
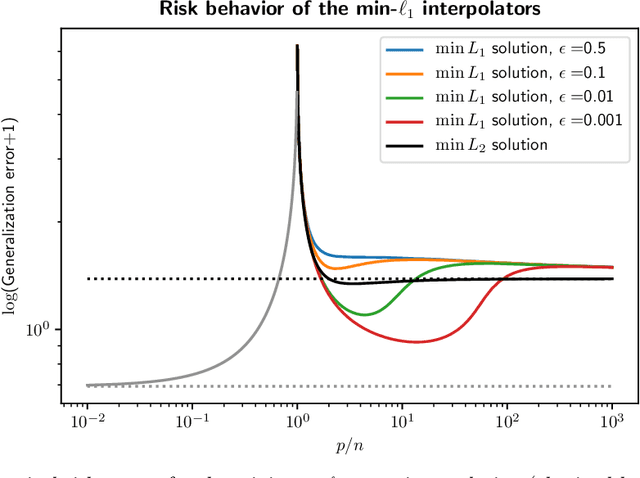
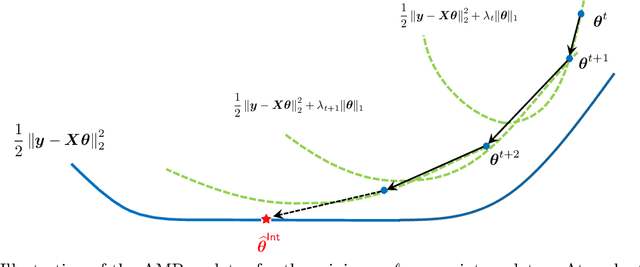
An evolving line of machine learning works observe empirical evidence that suggests interpolating estimators -- the ones that achieve zero training error -- may not necessarily be harmful. This paper pursues theoretical understanding for an important type of interpolators: the minimum $\ell_{1}$-norm interpolator, which is motivated by the observation that several learning algorithms favor low $\ell_1$-norm solutions in the over-parameterized regime. Concretely, we consider the noisy sparse regression model under Gaussian design, focusing on linear sparsity and high-dimensional asymptotics (so that both the number of features and the sparsity level scale proportionally with the sample size). We observe, and provide rigorous theoretical justification for, a curious multi-descent phenomenon; that is, the generalization risk of the minimum $\ell_1$-norm interpolator undergoes multiple (and possibly more than two) phases of descent and ascent as one increases the model capacity. This phenomenon stems from the special structure of the minimum $\ell_1$-norm interpolator as well as the delicate interplay between the over-parameterized ratio and the sparsity, thus unveiling a fundamental distinction in geometry from the minimum $\ell_2$-norm interpolator. Our finding is built upon an exact characterization of the risk behavior, which is governed by a system of two non-linear equations with two unknowns.
Fast Policy Extragradient Methods for Competitive Games with Entropy Regularization
May 31, 2021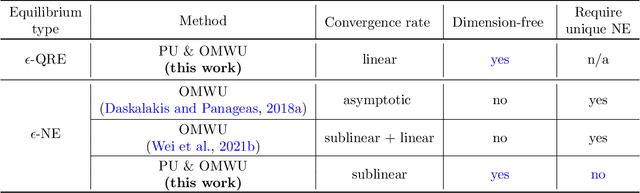
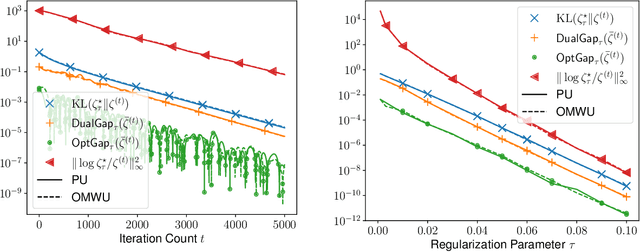
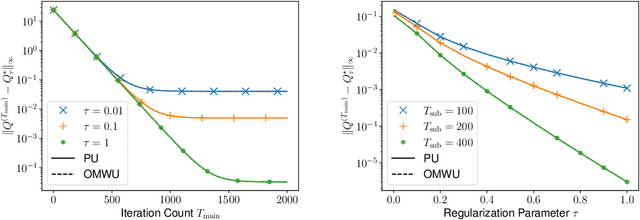
This paper investigates the problem of computing the equilibrium of competitive games, which is often modeled as a constrained saddle-point optimization problem with probability simplex constraints. Despite recent efforts in understanding the last-iterate convergence of extragradient methods in the unconstrained setting, the theoretical underpinnings of these methods in the constrained settings, especially those using multiplicative updates, remain highly inadequate, even when the objective function is bilinear. Motivated by the algorithmic role of entropy regularization in single-agent reinforcement learning and game theory, we develop provably efficient extragradient methods to find the quantal response equilibrium (QRE) -- which are solutions to zero-sum two-player matrix games with entropy regularization -- at a linear rate. The proposed algorithms can be implemented in a decentralized manner, where each player executes symmetric and multiplicative updates iteratively using its own payoff without observing the opponent's actions directly. In addition, by controlling the knob of entropy regularization, the proposed algorithms can locate an approximate Nash equilibrium of the unregularized matrix game at a sublinear rate without assuming the Nash equilibrium to be unique. Our methods also lead to efficient policy extragradient algorithms for solving entropy-regularized zero-sum Markov games at a linear rate. All of our convergence rates are nearly dimension-free, which are independent of the size of the state and action spaces up to logarithm factors, highlighting the positive role of entropy regularization for accelerating convergence.
Sample-Efficient Reinforcement Learning Is Feasible for Linearly Realizable MDPs with Limited Revisiting
May 17, 2021
Low-complexity models such as linear function representation play a pivotal role in enabling sample-efficient reinforcement learning (RL). The current paper pertains to a scenario with value-based linear representation, which postulates the linear realizability of the optimal Q-function (also called the "linear $Q^{\star}$ problem"). While linear realizability alone does not allow for sample-efficient solutions in general, the presence of a large sub-optimality gap is a potential game changer, depending on the sampling mechanism in use. Informally, sample efficiency is achievable with a large sub-optimality gap when a generative model is available but is unfortunately infeasible when we turn to standard online RL settings. In this paper, we make progress towards understanding this linear $Q^{\star}$ problem by investigating a new sampling protocol, which draws samples in an online/exploratory fashion but allows one to backtrack and revisit previous states in a controlled and infrequent manner. This protocol is more flexible than the standard online RL setting, while being practically relevant and far more restrictive than the generative model. We develop an algorithm tailored to this setting, achieving a sample complexity that scales polynomially with the feature dimension, the horizon, and the inverse sub-optimality gap, but not the size of the state/action space. Our findings underscore the fundamental interplay between sampling protocols and low-complexity structural representation in RL.