 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Structured State Space for Multispectral-fused Small Target Detection
May 21, 2025Target detection in high-resolution remote sensing imagery faces challenges due to the low recognition accuracy of small targets and high computational costs. The computational complexity of the Transformer architecture increases quadratically with image resolution, while Convolutional Neural Networks (CNN) architectures are forced to stack deeper convolutional layers to expand their receptive fields, leading to an explosive growth in computational demands. To address these computational constraints, we leverage Mamba's linear complexity for efficiency. However, Mamba's performance declines for small targets, primarily because small targets occupy a limited area in the image and have limited semantic information. Accurate identification of these small targets necessitates not only Mamba's global attention capabilities but also the precise capture of fine local details. To this end, we enhance Mamba by developing the Enhanced Small Target Detection (ESTD) module and the Convolutional Attention Residual Gate (CARG) module. The ESTD module bolsters local attention to capture fine-grained details, while the CARG module, built upon Mamba, emphasizes spatial and channel-wise information, collectively improving the model's ability to capture distinctive representations of small targets. Additionally, to highlight the semantic representation of small targets, we design a Mask Enhanced Pixel-level Fusion (MEPF) module for multispectral fusion, which enhances target features by effectively fusing visible and infrared multimodal information.
Scale-Aware Network with Regional and Semantic Attentions for Crowd Counting under Cluttered Background
Jan 07, 2021
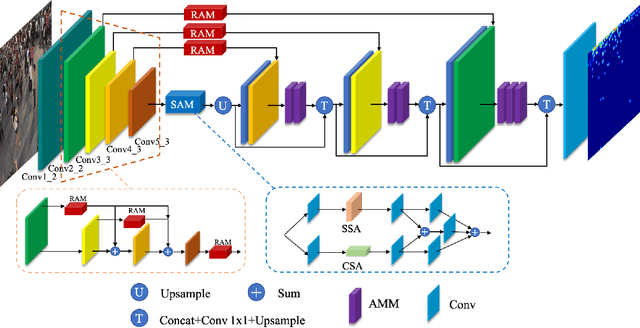
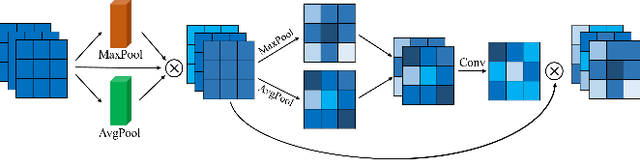
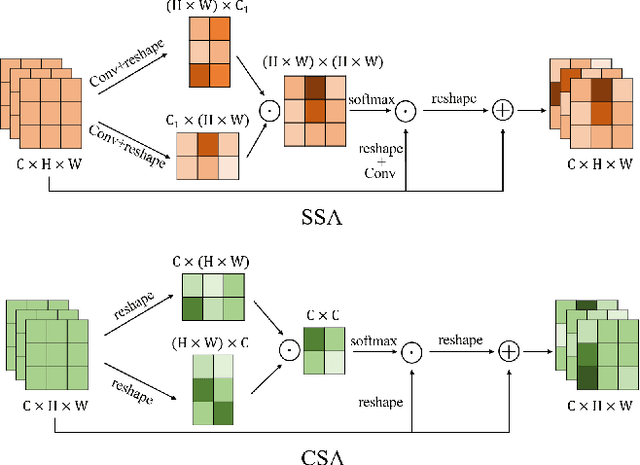
Crowd counting is an important task that shown great application value in public safety-related fields, which has attracted increasing attention in recent years. In the current research, the accuracy of counting numbers and crowd density estimation are the main concerns. Although the emergence of deep learning has greatly promoted the development of this field, crowd counting under cluttered background is still a serious challenge. In order to solve this problem, we propose a ScaleAware Crowd Counting Network (SACCN) with regional and semantic attentions. The proposed SACCN distinguishes crowd and background by applying regional and semantic self-attention mechanisms on the shallow layers and deep layers, respectively. Moreover, the asymmetric multi-scale module (AMM) is proposed to deal with the problem of scale diversity, and regional attention based dense connections and skip connections are designed to alleviate the variations on crowd scales. Extensive experimental results on multiple public benchmarks demonstrate that our proposed SACCN achieves satisfied superior performances and outperform most state-of-the-art methods. All codes and pretrained models will be released soon.