 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuideWeb: A Benchmark for Automatic In-App Guide Generation on Real-World Web UIs
Feb 02, 2026Digital Adoption Platform (DAP) provide web-based overlays that deliver operation guidance and contextual hints to help users navigate complex websites. Although modern DAP tools enable non-experts to author such guidance, maintaining these guides remains labor-intensive because website layouts and functionalities evolve continuously, which requires repeated manual updates and re-annotation. In this work, we introduce \textbf{GuideWeb}, a new benchmark for automatic in-app guide generation on real-world web UIs. GuideWeb formulates the task as producing page-level guidance by selecting \textbf{guide target elements} grounded in the webpage and generating concise guide text aligned with user intent. We also propose a comprehensive evaluation suite that jointly measures the accuracy of guide target element selection and the quality of generated intents and guide texts. Experiments show that our proposed \textbf{GuideWeb Agent} achieves \textbf{30.79\%} accuracy in guide target element prediction, while obtaining BLEU scores of \textbf{44.94} for intent generation and \textbf{21.34} for guide-text generation. Existing baselines perform substantially worse, which highlights that automatic guide generation remains challenging and that further advances are necessary before such systems can be reliably deployed in real-world settings.
Visual Merit or Linguistic Crutch? A Close Look at DeepSeek-OCR
Jan 08, 2026DeepSeek-OCR utilizes an optical 2D mapping approach to achieve high-ratio vision-text compression, claiming to decode text tokens exceeding ten times the input visual tokens. While this suggests a promising solution for the LLM long-context bottleneck, we investigate a critical question: "Visual merit or linguistic crutch - which drives DeepSeek-OCR's performance?" By employing sentence-level and word-level semantic corruption, we isolate the model's intrinsic OCR capabilities from its language priors. Results demonstrate that without linguistic support, DeepSeek-OCR's performance plummets from approximately 90% to 20%. Comparative benchmarking against 13 baseline models reveals that traditional pipeline OCR methods exhibit significantly higher robustness to such semantic perturbations than end-to-end methods. Furthermore, we find that lower visual token counts correlate with increased reliance on priors, exacerbating hallucination risks. Context stress testing also reveals a total model collapse around 10,000 text tokens, suggesting that current optical compression techniques may paradoxically aggravate the long-context bottleneck. This study empirically defines DeepSeek-OCR's capability boundaries and offers essential insights for future optimizations of the vision-text compression paradigm. We release all data, results and scripts used in this study at https://github.com/dududuck00/DeepSeekOCR.
M-MRE: Extending the Mutual Reinforcement Effect to Multimodal Information Extraction
Apr 24, 2025Mutual Reinforcement Effect (MRE) is an emerging subfield at the intersection of information extraction and model interpretability. MRE aims to leverage the mutual understanding between tasks of different granularities, enhancing the performance of both coarse-grained and fine-grained tasks through joint modeling. While MRE has been explored and validated in the textual domain, its applicability to visual and multimodal domains remains unexplored. In this work, we extend MRE to the multimodal information extraction domain for the first time. Specifically, we introduce a new task: Multimodal Mutual Reinforcement Effect (M-MRE), and construct a corresponding dataset to support this task. To address the challenges posed by M-MRE, we further propose a Prompt Format Adapter (PFA) that is fully compatible with various Large Vision-Language Models (LVLMs). Experimental results demonstrate that MRE can also be observed in the M-MRE task, a multimodal text-image understanding scenario. This provides strong evidence that MRE facilitates mutual gains across three interrelated tasks, confirming its generalizability beyond the textual domain.
MMM: Multilingual Mutual Reinforcement Effect Mix Datasets & Test with Open-domain Information Extraction Large Language Models
Jul 15, 2024



The Mutual Reinforcement Effect (MRE) represents a promising avenue in information extraction and multitasking research. Nevertheless, its applicability has been constrained due to the exclusive availability of MRE mix datasets in Japanese, thereby limiting comprehensive exploration by the global research community. To address this limitation, we introduce a Multilingual MRE mix dataset (MMM) that encompasses 21 sub-datasets in English, Japanese, and Chinese. In this paper, we also propose a method for dataset translation assisted by Large Language Models (LLMs), which significantly reduces the manual annotation time required for dataset construction by leveraging LLMs to translate the original Japanese datasets. Additionally, we have enriched the dataset by incorporating open-domain Named Entity Recognition (NER) and sentence classification tasks. Utilizing this expanded dataset, we developed a unified input-output framework to train an Open-domain Information Extraction Large Language Model (OIELLM). The OIELLM model demonstrates the capability to effectively process novel MMM datasets, exhibiting significant improvements in performance.
Selective Pseudo-labeling and Class-wise Discriminative Fusion for Sound Event Detection
Mar 04, 2022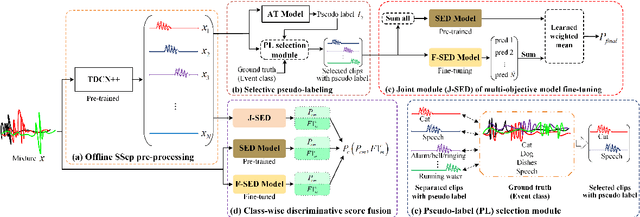
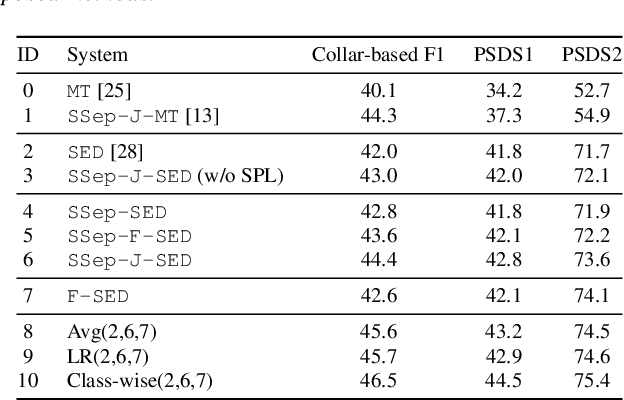
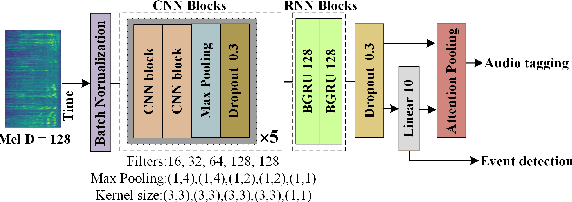
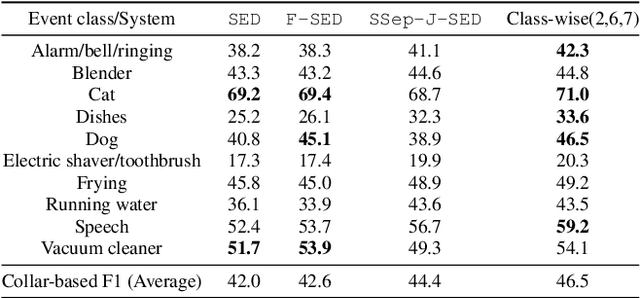
In recent years, exploring effective sound separation (SSep) techniques to improve overlapping sound event detection (SED) attracts more and more attention. Creating accurate separation signals to avoid the catastrophic error accumulation during SED model training is very important and challenging. In this study, we first propose a novel selective pseudo-labeling approach, termed SPL, to produce high confidence separated target events from blind sound separation outputs. These target events are then used to fine-tune the original SED model that pre-trained on the sound mixtures in a multi-objective learning style. Then, to further leverage the SSep outputs, a class-wise discriminative fusion is proposed to improve the final SED performances, by combining multiple frame-level event predictions of both sound mixtures and their separated signals. All experiments are performed on the public DCASE 2021 Task 4 dataset, and results show that our approaches significantly outperforms the official baseline, the collar-based F 1, PSDS1 and PSDS2 performances are improved from 44.3%, 37.3% and 54.9% to 46.5%, 44.5% and 75.4%, respectively.
Joint Weakly Supervised AT and AED Using Deep Feature Distillation and Adaptive Focal Loss
Mar 23, 2021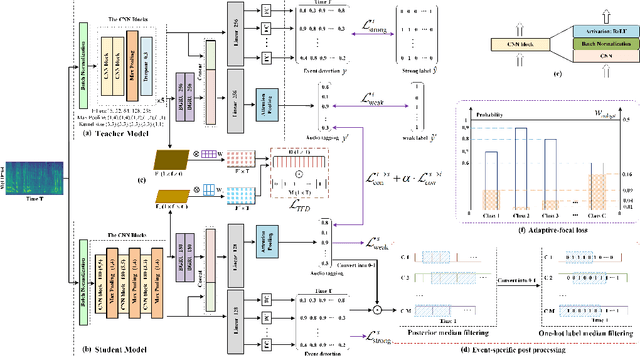
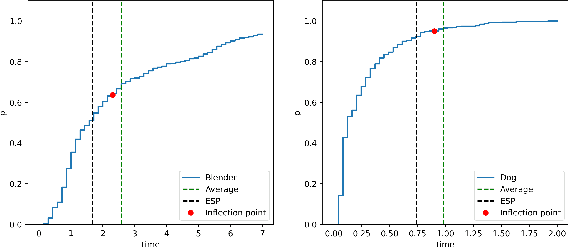
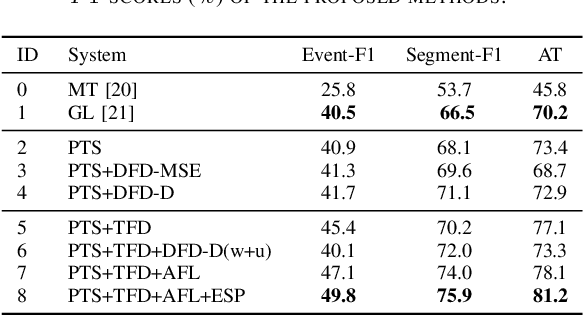
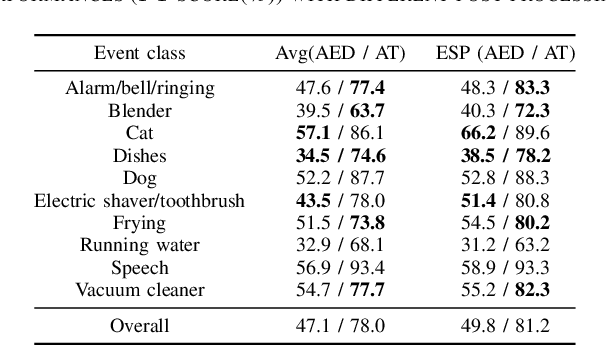
A good joint training framework is very helpful to improve the performances of weakly supervised audio tagging (AT) and acoustic event detection (AED) simultaneously. In this study, we propose three methods to improve the best teacher-student framework of DCASE2019 Task 4 for both AT and AED tasks. A frame-level target-events based deep feature distillation is first proposed, it aims to leverage the potential of limited strong-labeled data in weakly supervised framework to learn better intermediate feature maps. Then we propose an adaptive focal loss and two-stage training strategy to enable an effective and more accurate model training, in which the contribution of difficult-to-classify and easy-to-classify acoustic events to the total cost function can be automatically adjusted. Furthermore, an event-specific post processing is designed to improve the prediction of target event time-stamps. Our experiments are performed on the public DCASE2019 Task4 dataset, and results show that our approach achieves competitive performances in both AT (49.8% F1-score) and AED (81.2% F1-score) tasks.