 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeListen to What You Want: Neural Network-based Universal Sound Selector
Jun 10, 2020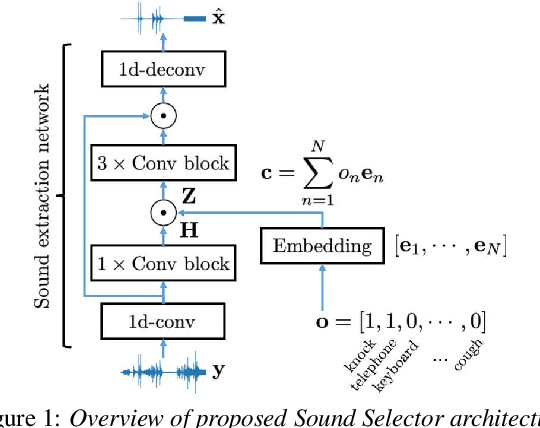
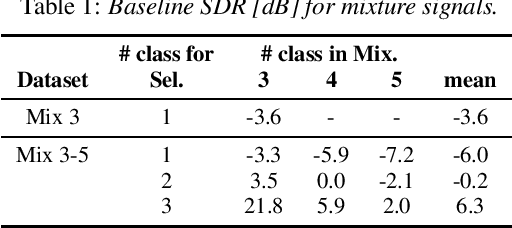
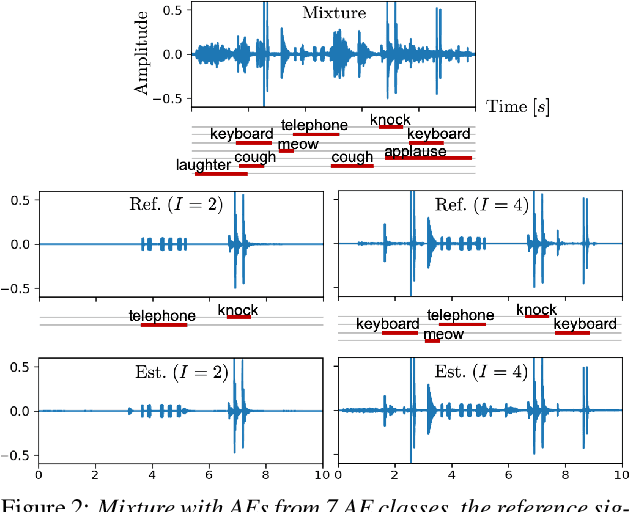
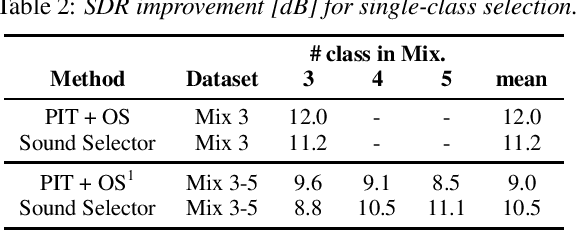
Being able to control the acoustic events (AEs) to which we want to listen would allow the development of more controllable hearable devices. This paper addresses the AE sound selection (or removal) problems, that we define as the extraction (or suppression) of all the sounds that belong to one or multiple desired AE classes. Although this problem could be addressed with a combination of source separation followed by AE classification, this is a sub-optimal way of solving the problem. Moreover, source separation usually requires knowing the maximum number of sources, which may not be practical when dealing with AEs. In this paper, we propose instead a universal sound selection neural network that enables to directly select AE sounds from a mixture given user-specified target AE classes. The proposed framework can be explicitly optimized to simultaneously select sounds from multiple desired AE classes, independently of the number of sources in the mixture. We experimentally show that the proposed method achieves promising AE sound selection performance and could be generalized to mixtures with a number of sources that are unseen during training.
Stable Training of DNN for Speech Enhancement based on Perceptually-Motivated Black-Box Cost Function
Feb 14, 2020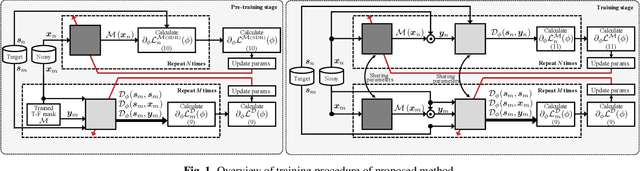
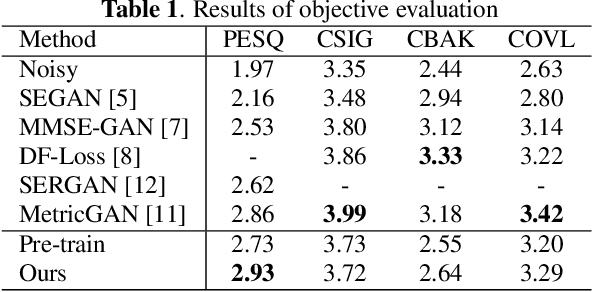
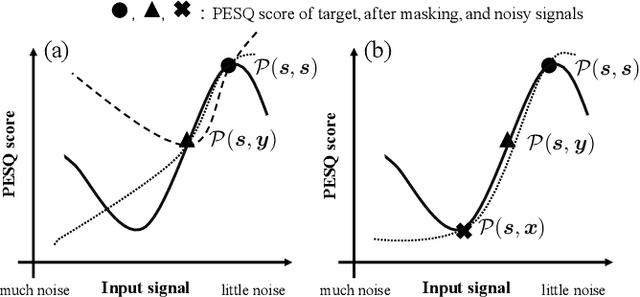
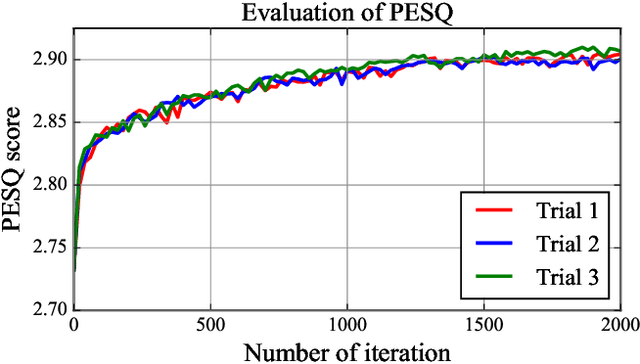
Improving subjective sound quality of enhanced signals is one of the most important missions in speech enhancement. For evaluating the subjective quality, several methods related to perceptually-motivated objective sound quality assessment (OSQA) have been proposed such as PESQ (perceptual evaluation of speech quality). However, direct use of such measures for training deep neural network (DNN) is not allowed in most cases because popular OSQAs are non-differentiable with respect to DNN parameters. Therefore, the previous study has proposed to approximate the score of OSQAs by an auxiliary DNN so that its gradient can be used for training the primary DNN. One problem with this approach is instability of the training caused by the approximation error of the score. To overcome this problem, we propose to use stabilization techniques borrowed from reinforcement learning. The experiments, aimed to increase the score of PESQ as an example, show that the proposed method (i) can stably train a DNN to increase PESQ, (ii) achieved the state-of-the-art PESQ score on a public dataset, and (iii) resulted in better sound quality than conventional methods based on subjective evaluation.
Speech Enhancement using Self-Adaptation and Multi-Head Self-Attention
Feb 14, 2020
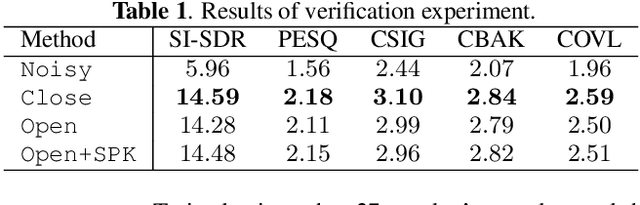
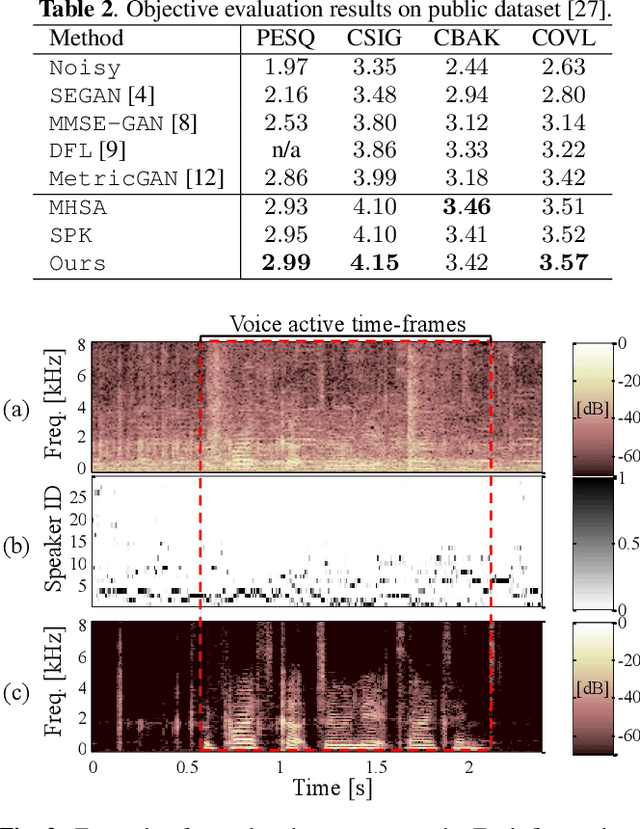
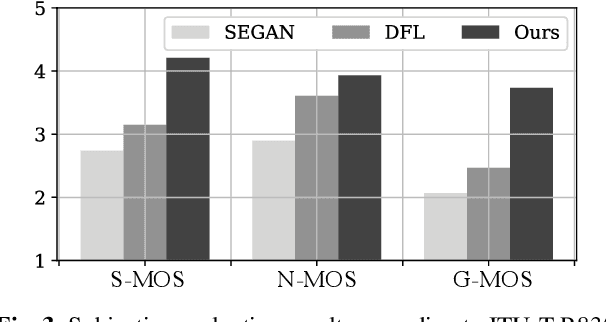
This paper investigates a self-adaptation method for speech enhancement using auxiliary speaker-aware features; we extract a speaker representation used for adaptation directly from the test utterance. Conventional studies of deep neural network (DNN)--based speech enhancement mainly focus on building a speaker independent model. Meanwhile, in speech applications including speech recognition and synthesis, it is known that model adaptation to the target speaker improves the accuracy. Our research question is whether a DNN for speech enhancement can be adopted to unknown speakers without any auxiliary guidance signal in test-phase. To achieve this, we adopt multi-task learning of speech enhancement and speaker identification, and use the output of the final hidden layer of speaker identification branch as an auxiliary feature. In addition, we use multi-head self-attention for capturing long-term dependencies in the speech and noise. Experimental results on a public dataset show that our strategy achieves the state-of-the-art performance and also outperform conventional methods in terms of subjective quality.
DOA Estimation by DNN-based Denoising and Dereverberation from Sound Intensity Vector
Oct 10, 2019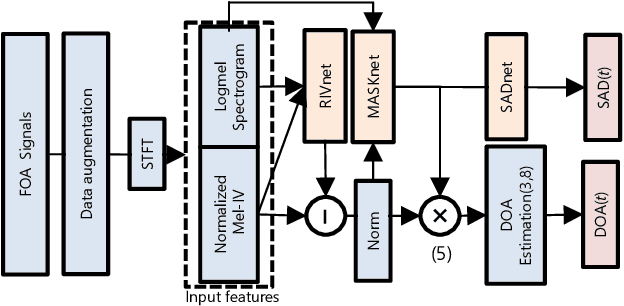

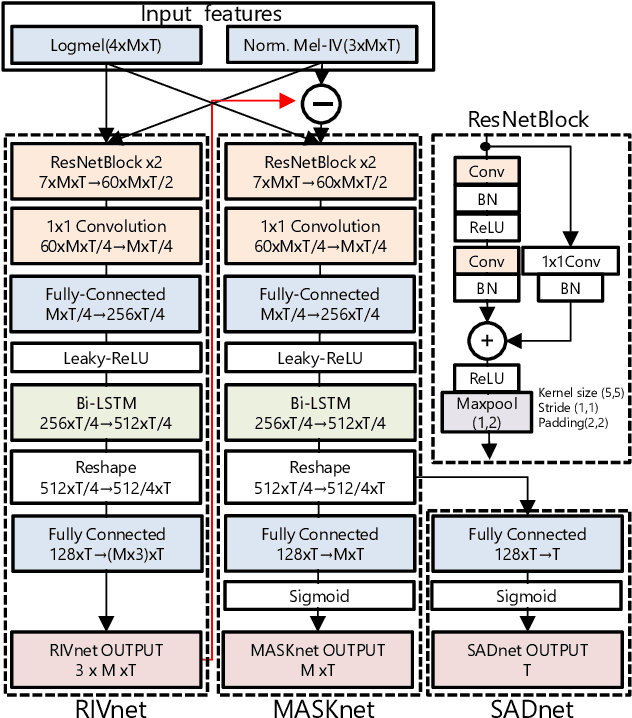
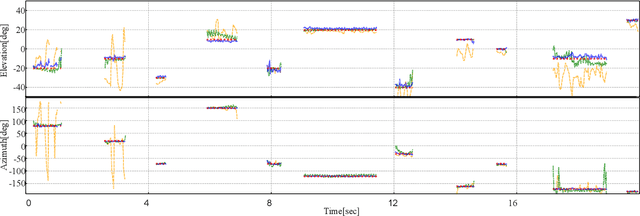
We propose a direction of arrival (DOA) estimation method that combines sound-intensity vector (IV)-based DOA estimation and DNN-based denoising and dereverberation. Since the accuracy of IV-based DOA estimation degrades due to environmental noise and reverberation, two DNNs are used to remove such effects from the observed IVs. DOA is then estimated from the refined IVs based on the physics of wave propagation. Experiments on an open dataset showed that the average DOA error of the proposed method was 0.528 degrees, and it outperformed a conventional IV-based and DNN-based DOA estimation method.
First Order Ambisonics Domain Spatial Augmentation for DNN-based Direction of Arrival Estimation
Oct 10, 2019
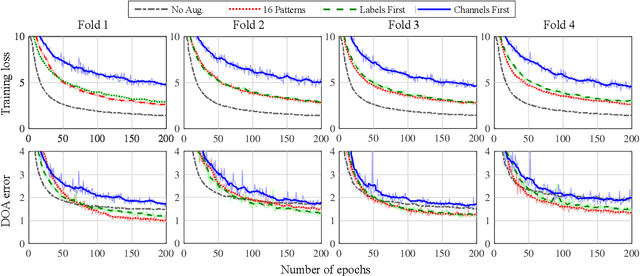
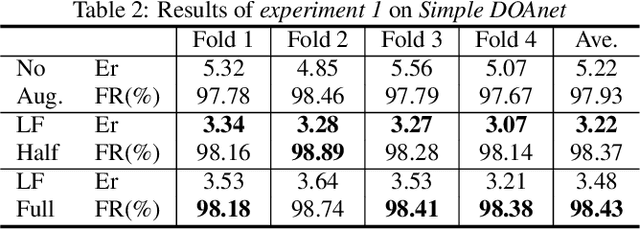
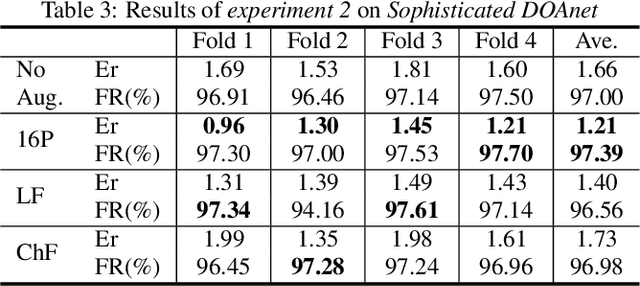
In this paper, we propose a novel data augmentation method for training neural networks for Direction of Arrival (DOA) estimation. This method focuses on expanding the representation of the DOA subspace of a dataset. Given some input data, it applies a transformation to it in order to change its DOA information and simulate new potentially unseen one. Such transformation, in general, is a combination of a rotation and a reflection. It is possible to apply such transformation due to a well-known property of First Order Ambisonics (FOA). The same transformation is applied also to the labels, in order to maintain consistency between input data and target labels. Three methods with different level of generality are proposed for applying this augmentation principle. Experiments are conducted on two different DOA networks. Results of both experiments demonstrate the effectiveness of the novel augmentation strategy by improving the DOA error by around 40%.
ToyADMOS: A Dataset of Miniature-Machine Operating Sounds for Anomalous Sound Detection
Aug 09, 2019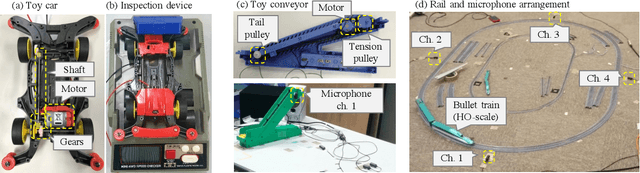
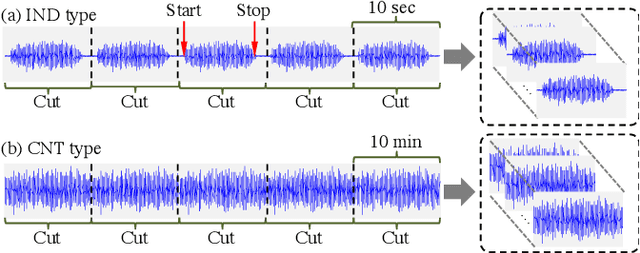
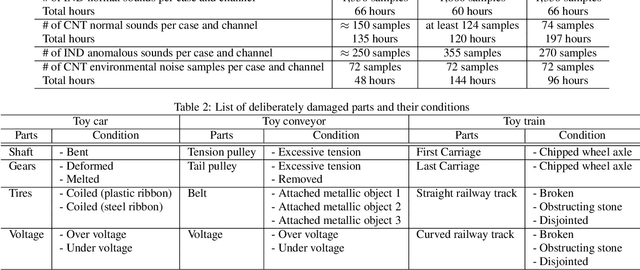
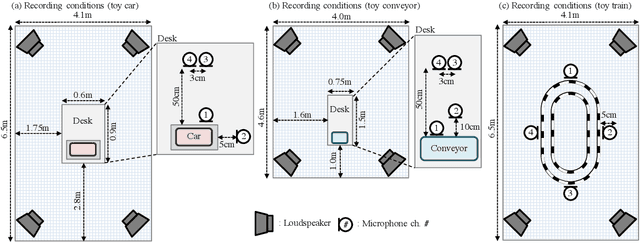
This paper introduces a new dataset called "ToyADMOS" designed for anomaly detection in machine operating sounds (ADMOS). To the best our knowledge, no large-scale datasets are available for ADMOS, although large-scale datasets have contributed to recent advancements in acoustic signal processing. This is because anomalous sound data are difficult to collect. To build a large-scale dataset for ADMOS, we collected anomalous operating sounds of miniature machines (toys) by deliberately damaging them. The released dataset consists of three sub-datasets for machine-condition inspection, fault diagnosis of machines with geometrically fixed tasks, and fault diagnosis of machines with moving tasks. Each sub-dataset includes over 180 hours of normal machine-operating sounds and over 4,000 samples of anomalous sounds collected with four microphones at a 48-kHz sampling rate. The dataset is freely available for download at https://github.com/YumaKoizumi/ToyADMOS-dataset
Batch Uniformization for Minimizing Maximum Anomaly Score of DNN-based Anomaly Detection in Sounds
Jul 19, 2019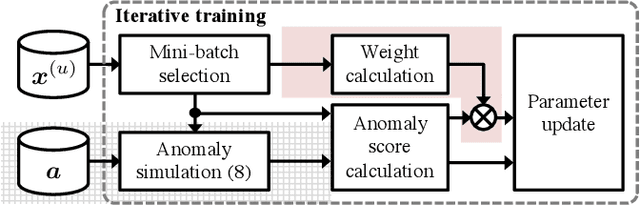

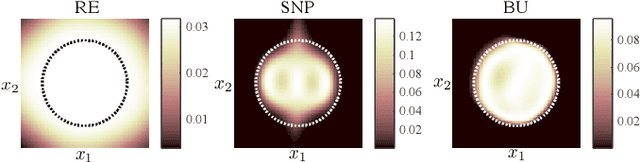
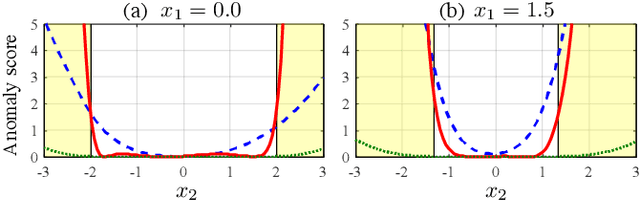
Use of an autoencoder (AE) as a normal model is a state-of-the-art technique for unsupervised-anomaly detection in sounds (ADS). The AE is trained to minimize the sample mean of the anomaly score of normal sounds in a mini-batch. One problem with this approach is that the anomaly score of rare-normal sounds becomes higher than that of frequent-normal sounds, because the sample mean is strongly affected by frequent-normal samples, resulting in preferentially decreasing the anomaly score of frequent-normal samples. To decrease anomaly scores for both frequent- and rare-normal sounds, we propose batch uniformization, a training method for unsupervised-ADS for minimizing a weighted average of the anomaly score on each sample in a mini-batch. We used the reciprocal of the probabilistic density of each sample as the weight, more intuitively, a large weight is given for rare-normal sounds. Such a weight works to give a constant anomaly score for both frequent- and rare-normal sounds. Since the probabilistic density is unknown, we estimate it by using the kernel density estimation on each training mini-batch. Verification- and objective-experiments show that the proposed batch uniformization improves the performance of unsupervised-ADS.
Deep Griffin-Lim Iteration
Mar 10, 2019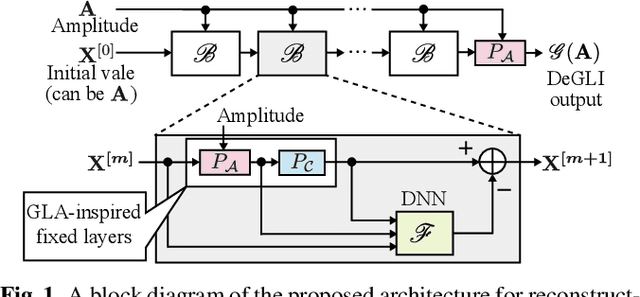

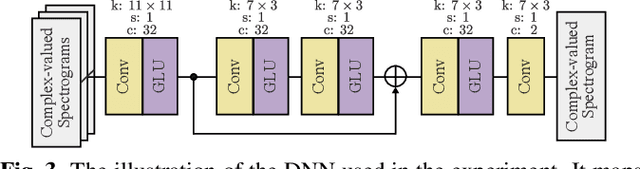
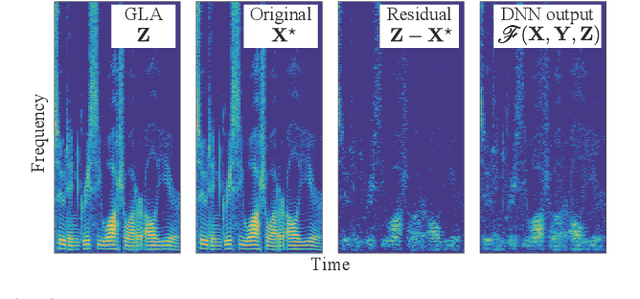
This paper presents a novel phase reconstruction method (only from a given amplitude spectrogram) by combining a signal-processing-based approach and a deep neural network (DNN). To retrieve a time-domain signal from its amplitude spectrogram, the corresponding phase is required. One of the popular phase reconstruction methods is the Griffin-Lim algorithm (GLA), which is based on the redundancy of the short-time Fourier transform. However, GLA often involves many iterations and produces low-quality signals owing to the lack of prior knowledge of the target signal. In order to address these issues, in this study, we propose an architecture which stacks a sub-block including two GLA-inspired fixed layers and a DNN. The number of stacked sub-blocks is adjustable, and we can trade the performance and computational load based on requirements of applications. The effectiveness of the proposed method is investigated by reconstructing phases from amplitude spectrograms of speeches.
AdaFlow: Domain-Adaptive Density Estimator with Application to Anomaly Detection and Unpaired Cross-Domain Translation
Dec 14, 2018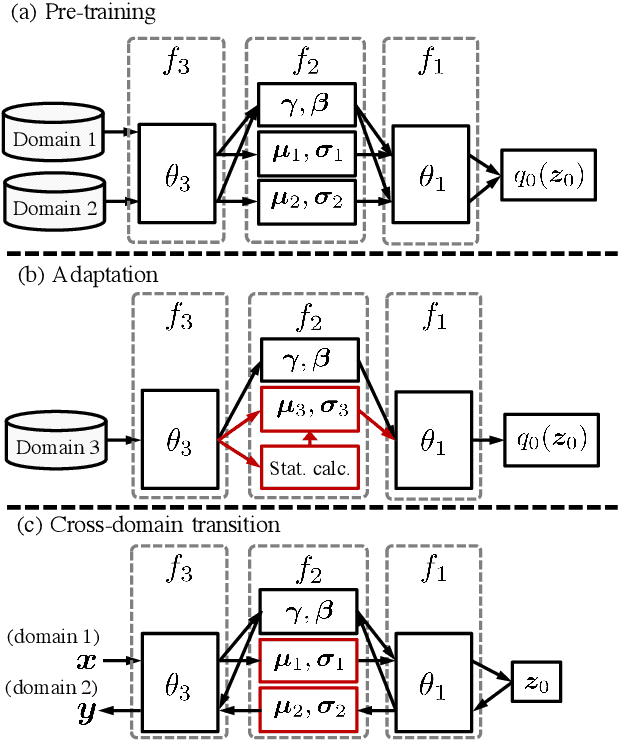
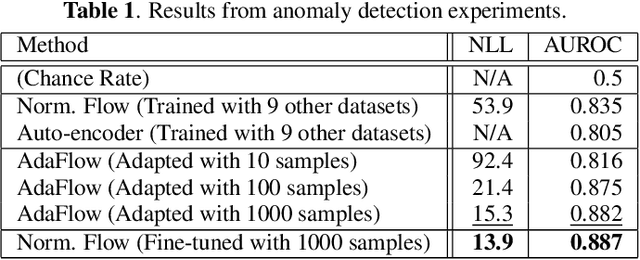

We tackle unsupervised anomaly detection (UAD), a problem of detecting data that significantly differ from normal data. UAD is typically solved by using density estimation. Recently, deep neural network (DNN)-based density estimators, such as Normalizing Flows, have been attracting attention. However, one of their drawbacks is the difficulty in adapting them to the change in the normal data's distribution. To address this difficulty, we propose AdaFlow, a new DNN-based density estimator that can be easily adapted to the change of the distribution. AdaFlow is a unified model of a Normalizing Flow and Adaptive Batch-Normalizations, a module that enables DNNs to adapt to new distributions. AdaFlow can be adapted to a new distribution by just conducting forward propagation once per sample; hence, it can be used on devices that have limited computational resources. We have confirmed the effectiveness of the proposed model through an anomaly detection in a sound task. We also propose a method of applying AdaFlow to the unpaired cross-domain translation problem, in which one has to train a cross-domain translation model with only unpaired samples. We have confirmed that our model can be used for the cross-domain translation problem through experiments on image datasets.
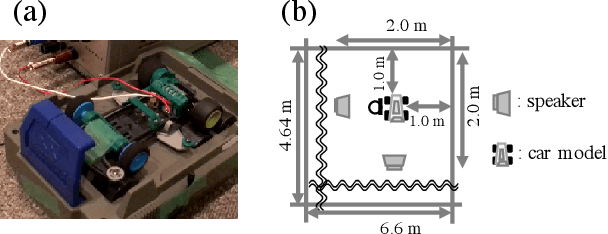
Trainable Adaptive Window Switching for Speech Enhancement
Nov 05, 2018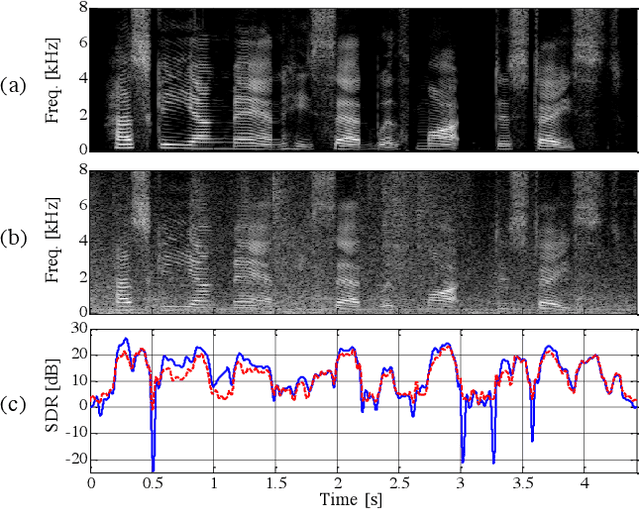
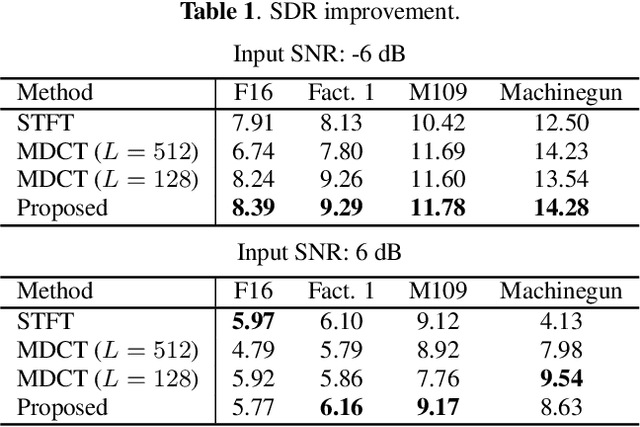
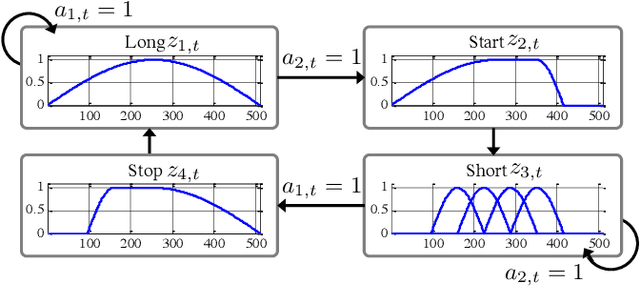
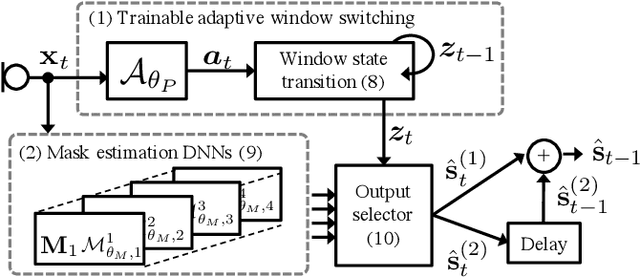
This study proposes a trainable adaptive window switching (AWS) method and apply it to a deep-neural-network (DNN) for speech enhancement in the modified discrete cosine transform domain. Time-frequency (T-F) mask processing in the short-time Fourier transform (STFT)-domain is a typical speech enhancement method. To recover the target signal precisely, DNN-based short-time frequency transforms have recently been investigated and used instead of the STFT. However, since such a fixed-resolution short-time frequency transform method has a T-F resolution problem based on the uncertainty principle, not only the short-time frequency transform but also the length of the windowing function should be optimized. To overcome this problem, we incorporate AWS into the speech enhancement procedure, and the windowing function of each time-frame is manipulated using a DNN depending on the input signal. We confirmed that the proposed method achieved a higher signal-to-distortion ratio than conventional speech enhancement methods in fixed-resolution frequency domains.