 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrinity: A Scenario-Aware Recommendation Framework for Large-Scale Cold-Start Users
Feb 28, 2026Early-stage users in a new scenario intensify cold-start challenges, yet prior works often address only parts of the problem through model architecture. Launching a new user experience to replace an established product involves sparse behavioral signals, low-engagement cohorts, and unstable model performance. We argue that effective recommendations require the synergistic integration of feature engineering, model architecture, and stable model updating. We propose Trinity, a framework embodying this principle. Trinity extracts valuable information from existing scenarios while ensuring predictive effectiveness and accuracy in the new scenario. In this paper, we showcase Trinity applied to a billion-user Microsoft product transition. Both offline and online experiments demonstrate that our framework achieves substantial improvements in addressing the combined challenge of new users in new scenarios.
Learning User Interests via Reasoning and Distillation for Cross-Domain News Recommendation
Feb 16, 2026News recommendation plays a critical role in online news platforms by helping users discover relevant content. Cross-domain news recommendation further requires inferring user's underlying information needs from heterogeneous signals that often extend beyond direct news consumption. A key challenge lies in moving beyond surface-level behaviors to capture deeper, reusable user interests while maintaining scalability in large-scale production systems. In this paper, we present a reinforcement learning framework that trains large language models to generate high-quality lists of interest-driven news search queries from cross-domain user signals. We formulate query-list generation as a policy optimization problem and employ GRPO with multiple reward signals. We systematically study two compute dimensions: inference-time sampling and model capacity, and empirically observe consistent improvements with increased compute that exhibit scaling-like behavior. Finally, we perform on-policy distillation to transfer the learned policy from a large, compute-intensive teacher to a compact student model suitable for scalable deployment. Extensive offline experiments, ablation studies and large-scale online A/B tests in a production news recommendation system demonstrate consistent gains in both interest modeling quality and downstream recommendation performance.
DeepGen: Diverse Search Ad Generation and Real-Time Customization
Aug 06, 2022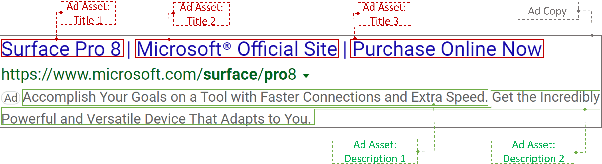

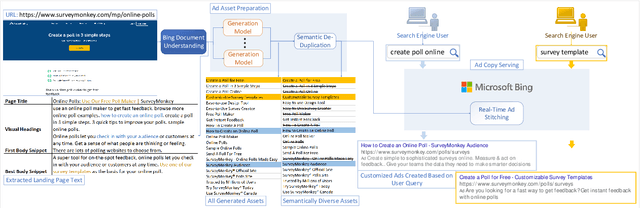
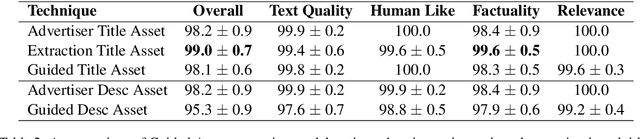
We present DeepGen, a system deployed at web scale for automatically creating sponsored search advertisements (ads) for BingAds customers. We leverage state-of-the-art natural language generation (NLG) models to generate fluent ads from advertiser's web pages in an abstractive fashion and solve practical issues such as factuality and inference speed. In addition, our system creates a customized ad in real-time in response to the user's search query, therefore highlighting different aspects of the same product based on what the user is looking for. To achieve this, our system generates a diverse choice of smaller pieces of the ad ahead of time and, at query time, selects the most relevant ones to be stitched into a complete ad. We improve generation diversity by training a controllable NLG model to generate multiple ads for the same web page highlighting different selling points. Our system design further improves diversity horizontally by first running an ensemble of generation models trained with different objectives and then using a diversity sampling algorithm to pick a diverse subset of generation results for online selection. Experimental results show the effectiveness of our proposed system design. Our system is currently deployed in production, serving ${\sim}4\%$ of global ads served in Bing.