 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning User Interests via Reasoning and Distillation for Cross-Domain News Recommendation
Feb 16, 2026News recommendation plays a critical role in online news platforms by helping users discover relevant content. Cross-domain news recommendation further requires inferring user's underlying information needs from heterogeneous signals that often extend beyond direct news consumption. A key challenge lies in moving beyond surface-level behaviors to capture deeper, reusable user interests while maintaining scalability in large-scale production systems. In this paper, we present a reinforcement learning framework that trains large language models to generate high-quality lists of interest-driven news search queries from cross-domain user signals. We formulate query-list generation as a policy optimization problem and employ GRPO with multiple reward signals. We systematically study two compute dimensions: inference-time sampling and model capacity, and empirically observe consistent improvements with increased compute that exhibit scaling-like behavior. Finally, we perform on-policy distillation to transfer the learned policy from a large, compute-intensive teacher to a compact student model suitable for scalable deployment. Extensive offline experiments, ablation studies and large-scale online A/B tests in a production news recommendation system demonstrate consistent gains in both interest modeling quality and downstream recommendation performance.
Training Large-Scale News Recommenders with Pretrained Language Models in the Loop
Mar 05, 2021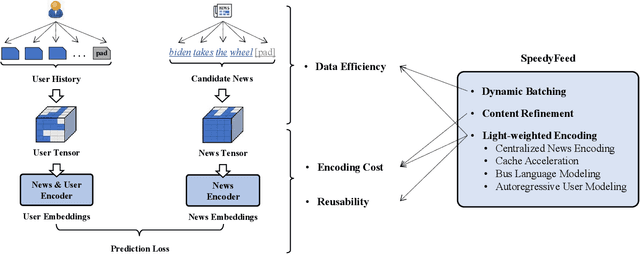
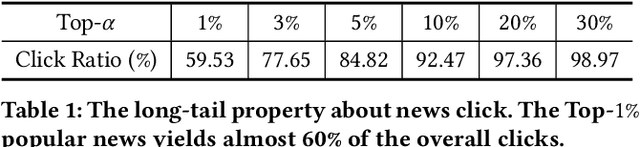
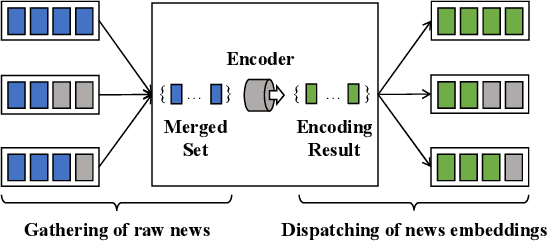

News recommendation calls for deep insights of news articles' underlying semantics. Therefore, pretrained language models (PLMs), like BERT and RoBERTa, may substantially contribute to the recommendation quality. However, it's extremely challenging to have news recommenders trained together with such big models: the learning of news recommenders requires intensive news encoding operations, whose cost is prohibitive if PLMs are used as the news encoder. In this paper, we propose a novel framework, {SpeedyFeed}, which efficiently trains PLMs-based news recommenders of superior quality. SpeedyFeed is highlighted for its light-weighted encoding pipeline, which gives rise to three major advantages. Firstly, it makes the intermedia results fully reusable for the training workflow, which removes most of the repetitive but redundant encoding operations. Secondly, it improves the data efficiency of the training workflow, where non-informative data can be eliminated from encoding. Thirdly, it further saves the cost by leveraging simplified news encoding and compact news representation. Extensive experiments show that SpeedyFeed leads to more than 100$\times$ acceleration of the training process, which enables big models to be trained efficiently and effectively over massive user data. The well-trained PLMs-based model from SpeedyFeed demonstrates highly competitive performance, where it outperforms the state-of-the-art news recommenders with significant margins. SpeedyFeed is also a model-agnostic framework, which is potentially applicable to a wide spectrum of content-based recommender systems; therefore, the whole framework is open-sourced to facilitate the progress in related areas.