 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnveiling and Steering Connectome Organization with Interpretable Latent Variables
May 19, 2025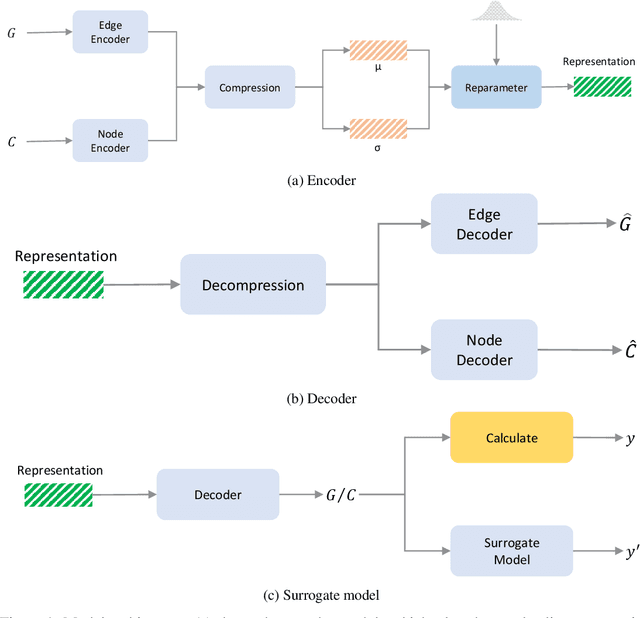
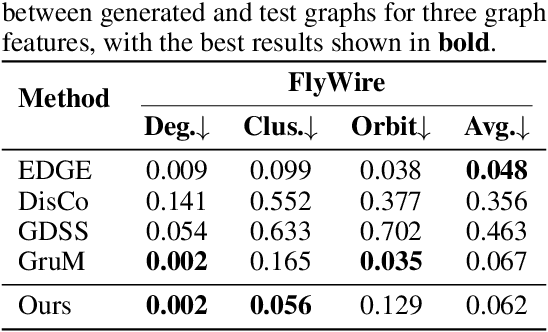


The brain's intricate connectome, a blueprint for its function, presents immense complexity, yet it arises from a compact genetic code, hinting at underlying low-dimensional organizational principles. This work bridges connectomics and representation learning to uncover these principles. We propose a framework that combines subgraph extraction from the Drosophila connectome, FlyWire, with a generative model to derive interpretable low-dimensional representations of neural circuitry. Crucially, an explainability module links these latent dimensions to specific structural features, offering insights into their functional relevance. We validate our approach by demonstrating effective graph reconstruction and, significantly, the ability to manipulate these latent codes to controllably generate connectome subgraphs with predefined properties. This research offers a novel tool for understanding brain architecture and a potential avenue for designing bio-inspired artificial neural networks.
ESE: Efficient Speech Recognition Engine with Sparse LSTM on FPGA
Feb 20, 2017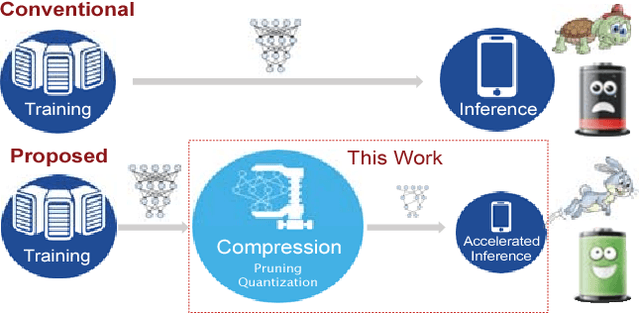

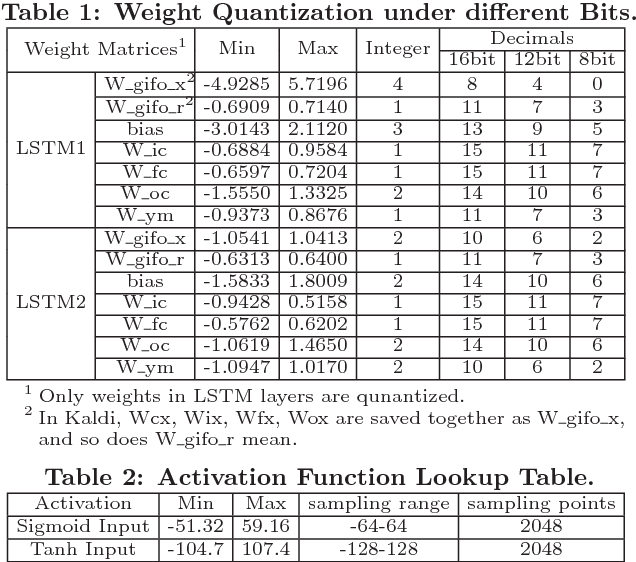
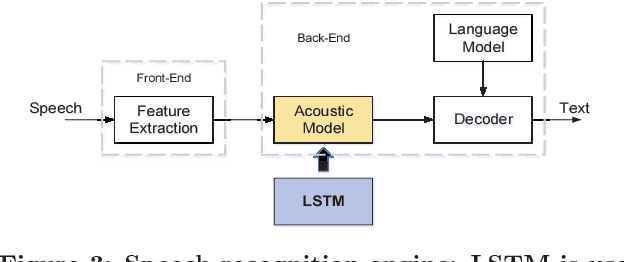
Long Short-Term Memory (LSTM) is widely used in speech recognition. In order to achieve higher prediction accuracy, machine learning scientists have built larger and larger models. Such large model is both computation intensive and memory intensive. Deploying such bulky model results in high power consumption and leads to high total cost of ownership (TCO) of a data center. In order to speedup the prediction and make it energy efficient, we first propose a load-balance-aware pruning method that can compress the LSTM model size by 20x (10x from pruning and 2x from quantization) with negligible loss of the prediction accuracy. The pruned model is friendly for parallel processing. Next, we propose scheduler that encodes and partitions the compressed model to each PE for parallelism, and schedule the complicated LSTM data flow. Finally, we design the hardware architecture, named Efficient Speech Recognition Engine (ESE) that works directly on the compressed model. Implemented on Xilinx XCKU060 FPGA running at 200MHz, ESE has a performance of 282 GOPS working directly on the compressed LSTM network, corresponding to 2.52 TOPS on the uncompressed one, and processes a full LSTM for speech recognition with a power dissipation of 41 Watts. Evaluated on the LSTM for speech recognition benchmark, ESE is 43x and 3x faster than Core i7 5930k CPU and Pascal Titan X GPU implementations. It achieves 40x and 11.5x higher energy efficiency compared with the CPU and GPU respectively.