 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Multi-Robot Systems Meet Agentic AI:Towards Embodied Collective Intelligence
Jun 26, 2026Embodied AI is increasingly becoming agentic, shifting robots from perception--control pipelines towards closed-loop systems that can retrieve context, deliberate during execution, monitor feedback, and refine future behavior. In parallel, robotics research has also moved from single-robot autonomy towards multi-robot systems, driven by the need for wider sensing, distributed action, heterogeneous capabilities, and fault tolerance. As AI agents move from single-agent use towards multi-agent collaboration, robotics faces a parallel challenge: robot teams must move beyond sharing maps, task assignments, and datasets towards sharing the state produced by embodied agent loops. This article explores Embodied Collective Intelligence (ECI), a future multi-robot paradigm in which a robot team accumulates and uses world context, task progress, and skill experience as shared resources. Specifically, we first review how embodied AI is becoming agentic and how multi-robot cooperation has evolved. We then present Embodied Collective Intelligence through Co-Perception, Co-Action, and Co-Evolution. Finally, we use an illustrative navigation study to examine one concrete component of the concept: shared world-memory inheritance. The study shows that a newly added robot can benefit from merged team memory, but it is not intended as a full evaluation of the ECI framework. Taken together, the review and conceptual framework motivate Embodied Collective Intelligence as a direction for embodied multi-agent intelligence, while the case study grounds one measurable part of the concept.
CoVSpec: Efficient Device-Edge Co-Inference for Vision-Language Models via Speculative Decoding
May 04, 2026Vision-language models (VLMs) have demonstrated strong capabilities in multimodal perception and reasoning. However, deploying large VLMs on mobile devices remains challenging due to their substantial computational and memory demands. A practical alternative is device-edge co-inference, where a lightweight draft VLM on the mobile device collaborates with a larger target VLM on the edge server via speculative decoding. Nevertheless, directly extending speculative decoding to VLMs suffers from severe inefficiency due to excessive visual-token computation and high communication overhead. To address these challenges, we propose CoVSpec, an efficient collaborative speculative decoding framework for VLM inference. Specifically, we first develop a training-free visual token reduction framework that prunes redundant visual tokens on the mobile device by jointly considering query relevance, token activity, and low-rank dependency. Moreover, we design an adaptive drafting strategy that dynamically adjusts both the verification frequency and the draft length. In addition, we introduce a parallel branching mechanism with decoupled verification-correction to improve draft-side utilization during target-side verification and reduce correction-related transmission overhead. Experiments on multiple benchmarks show that CoVSpec achieves up to 2.21x higher throughput than target-only inference and reduces communication overhead by more than 96% compared with baselines, without compromising task accuracy.
Rethinking Secure Semantic Communications in the Age of Generative and Agentic AI: Threats and Opportunities
Jan 06, 2026Semantic communication (SemCom) improves communication efficiency by transmitting task-relevant information instead of raw bits and is expected to be a key technology for 6G networks. Recent advances in generative AI (GenAI) further enhance SemCom by enabling robust semantic encoding and decoding under limited channel conditions. However, these efficiency gains also introduce new security and privacy vulnerabilities. Due to the broadcast nature of wireless channels, eavesdroppers can also use powerful GenAI-based semantic decoders to recover private information from intercepted signals. Moreover, rapid advances in agentic AI enable eavesdroppers to perform long-term and adaptive inference through the integration of memory, external knowledge, and reasoning capabilities. This allows eavesdroppers to further infer user private behavior and intent beyond the transmitted content. Motivated by these emerging challenges, this paper comprehensively rethinks the security and privacy of SemCom systems in the age of generative and agentic AI. We first present a systematic taxonomy of eavesdropping threat models in SemCom systems. Then, we provide insights into how GenAI and agentic AI can enhance eavesdropping threats. Meanwhile, we also highlight potential opportunities for leveraging GenAI and agentic AI to design privacy-preserving SemCom systems.
Enabling Training-Free Semantic Communication Systems with Generative Diffusion Models
May 05, 2025



Semantic communication (SemCom) has recently emerged as a promising paradigm for next-generation wireless systems. Empowered by advanced artificial intelligence (AI) technologies, SemCom has achieved significant improvements in transmission quality and efficiency. However, existing SemCom systems either rely on training over large datasets and specific channel conditions or suffer from performance degradation under channel noise when operating in a training-free manner. To address these issues, we explore the use of generative diffusion models (GDMs) as training-free SemCom systems. Specifically, we design a semantic encoding and decoding method based on the inversion and sampling process of the denoising diffusion implicit model (DDIM), which introduces a two-stage forward diffusion process, split between the transmitter and receiver to enhance robustness against channel noise. Moreover, we optimize sampling steps to compensate for the increased noise level caused by channel noise. We also conduct a brief analysis to provide insights about this design. Simulations on the Kodak dataset validate that the proposed system outperforms the existing baseline SemCom systems across various metrics.
FHEDN: A based on context modeling Feature Hierarchy Encoder-Decoder Network for face detection
Dec 11, 2017

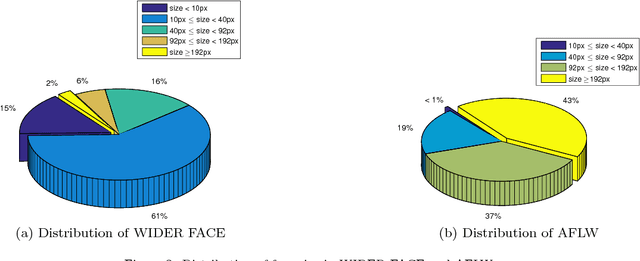
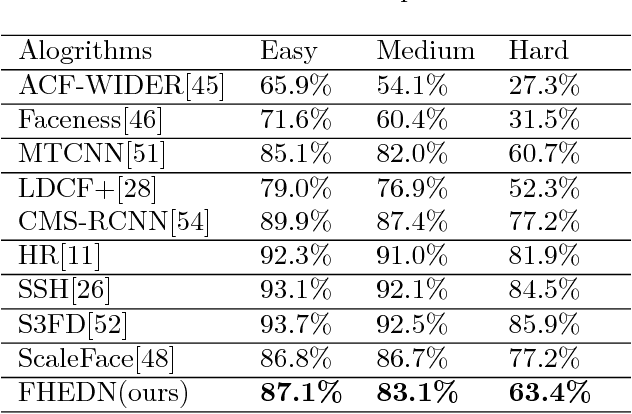
Because of affected by weather conditions, camera pose and range, etc. Objects are usually small, blur, occluded and diverse pose in the images gathered from outdoor surveillance cameras or access control system. It is challenging and important to detect faces precisely for face recognition system in the field of public security. In this paper, we design a based on context modeling structure named Feature Hierarchy Encoder-Decoder Network for face detection(FHEDN), which can detect small, blur and occluded face with hierarchy by hierarchy from the end to the beginning likes encoder-decoder in a single network. The proposed network is consist of multiple context modeling and prediction modules, which are in order to detect small, blur, occluded and diverse pose faces. In addition, we analyse the influence of distribution of training set, scale of default box and receipt field size to detection performance in implement stage. Demonstrated by experiments, Our network achieves promising performance on WIDER FACE and FDDB benchmarks.