 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Transfer Learning for End-to-End Speech Synthesis from Deep Pre-Trained Language Models
Jun 17, 2019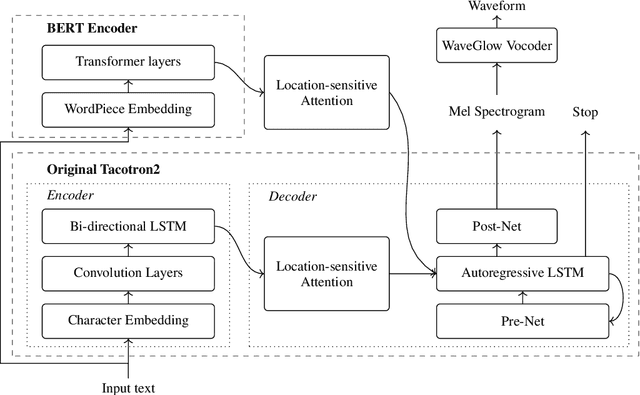

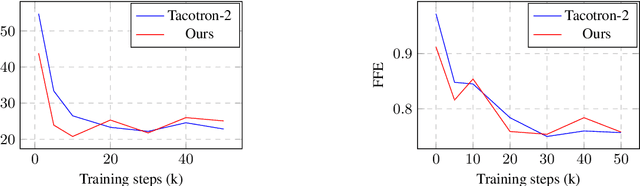
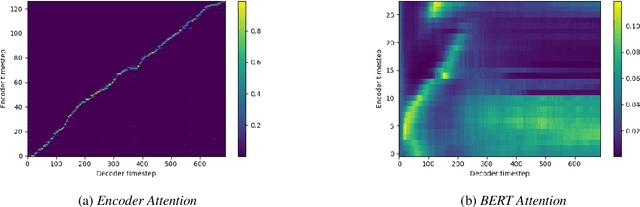
Modern text-to-speech (TTS) systems are able to generate audio that sounds almost as natural as human speech. However, the bar of developing high-quality TTS systems remains high since a sizable set of studio-quality <text, audio> pairs is usually required. Compared to commercial data used to develop state-of-the-art systems, publicly available data are usually worse in terms of both quality and size. Audio generated by TTS systems trained on publicly available data tends to not only sound less natural, but also exhibits more background noise. In this work, we aim to lower TTS systems' reliance on high-quality data by providing them the textual knowledge extracted by deep pre-trained language models during training. In particular, we investigate the use of BERT to assist the training of Tacotron-2, a state of the art TTS consisting of an encoder and an attention-based decoder. BERT representations learned from large amounts of unlabeled text data are shown to contain very rich semantic and syntactic information about the input text, and have potential to be leveraged by a TTS system to compensate the lack of high-quality data. We incorporate BERT as a parallel branch to the Tacotron-2 encoder with its own attention head. For an input text, it is simultaneously passed into BERT and the Tacotron-2 encoder. The representations extracted by the two branches are concatenated and then fed to the decoder. As a preliminary study, although we have not found incorporating BERT into Tacotron-2 generates more natural or cleaner speech at a human-perceivable level, we observe improvements in other aspects such as the model is being significantly better at knowing when to stop decoding such that there is much less babbling at the end of the synthesized audio and faster convergence during training.
An Unsupervised Autoregressive Model for Speech Representation Learning
Apr 05, 2019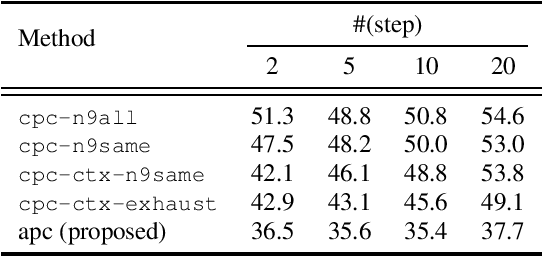
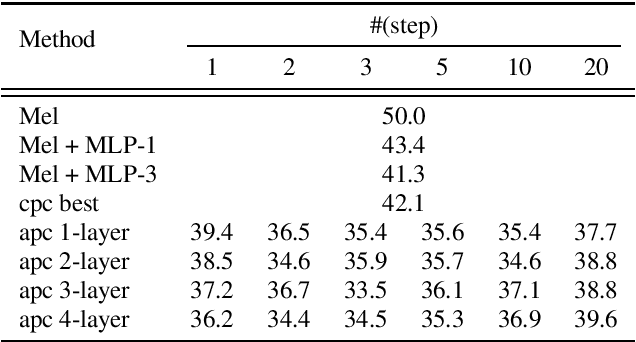
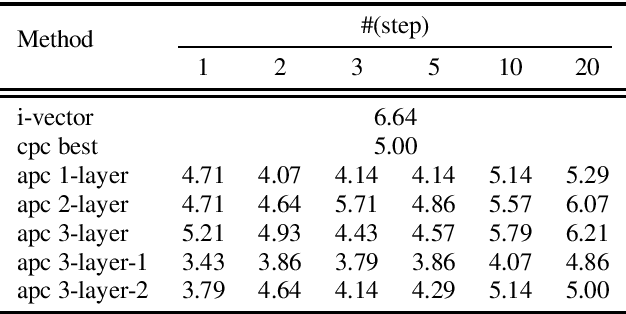
This paper proposes a novel unsupervised autoregressive neural model for learning generic speech representations. In contrast to other speech representation learning methods that aim to remove noise or speaker variabilities, ours is designed to preserve information for a wide range of downstream tasks. In addition, the proposed model does not require any phonetic or word boundary labels, allowing the model to benefit from large quantities of unlabeled data. Speech representations learned by our model significantly improve performance on both phone classification and speaker verification over the surface features and other supervised and unsupervised approaches. Further analysis shows that different levels of speech information are captured by our model at different layers. In particular, the lower layers tend to be more discriminative for speakers, while the upper layers provide more phonetic content.
Unsupervised Clinical Language Translation
Feb 04, 2019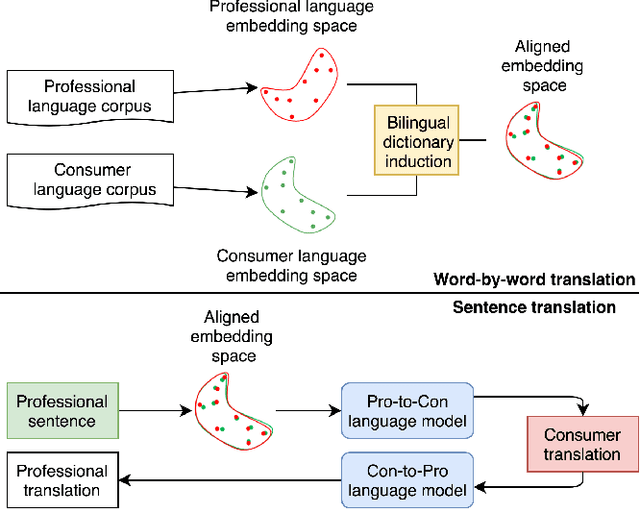
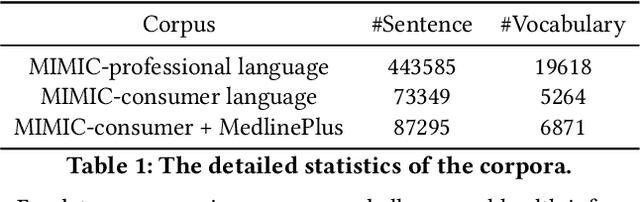

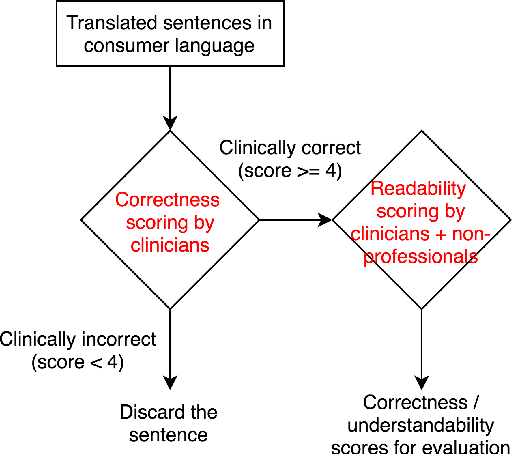
As patients' access to their doctors' clinical notes becomes common, translating professional, clinical jargon to layperson-understandable language is essential to improve patient-clinician communication. Such translation yields better clinical outcomes by enhancing patients' understanding of their own health conditions, and thus improving patients' involvement in their own care. Existing research has used dictionary-based word replacement or definition insertion to approach the need. However, these methods are limited by expert curation, which is hard to scale and has trouble generalizing to unseen datasets that do not share an overlapping vocabulary. In contrast, we approach the clinical word and sentence translation problem in a completely unsupervised manner. We show that a framework using representation learning, bilingual dictionary induction and statistical machine translation yields the best precision at 10 of 0.827 on professional-to-consumer word translation, and mean opinion scores of 4.10 and 4.28 out of 5 for clinical correctness and layperson readability, respectively, on sentence translation. Our fully-unsupervised strategy overcomes the curation problem, and the clinically meaningful evaluation reduces biases from inappropriate evaluators, which are critical in clinical machine learning.
Towards Unsupervised Speech-to-Text Translation
Nov 04, 2018
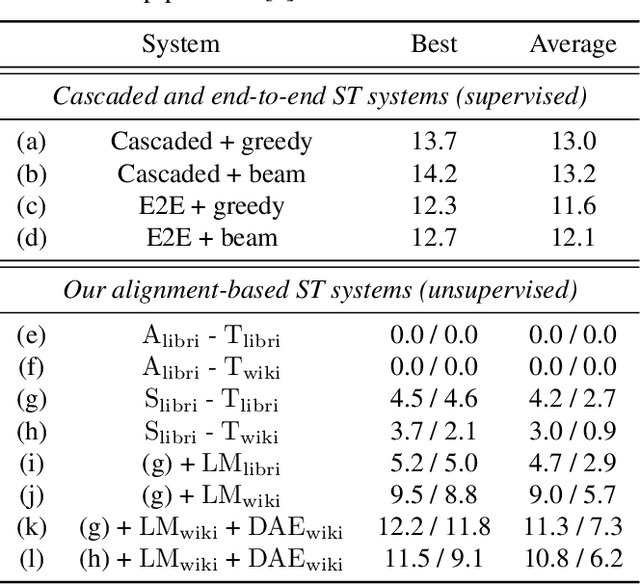
We present a framework for building speech-to-text translation (ST) systems using only monolingual speech and text corpora, in other words, speech utterances from a source language and independent text from a target language. As opposed to traditional cascaded systems and end-to-end architectures, our system does not require any labeled data (i.e., transcribed source audio or parallel source and target text corpora) during training, making it especially applicable to language pairs with very few or even zero bilingual resources. The framework initializes the ST system with a cross-modal bilingual dictionary inferred from the monolingual corpora, that maps every source speech segment corresponding to a spoken word to its target text translation. For unseen source speech utterances, the system first performs word-by-word translation on each speech segment in the utterance. The translation is improved by leveraging a language model and a sequence denoising autoencoder to provide prior knowledge about the target language. Experimental results show that our unsupervised system achieves comparable BLEU scores to supervised end-to-end models despite the lack of supervision. We also provide an ablation analysis to examine the utility of each component in our system.
Unsupervised Cross-Modal Alignment of Speech and Text Embedding Spaces
Sep 20, 2018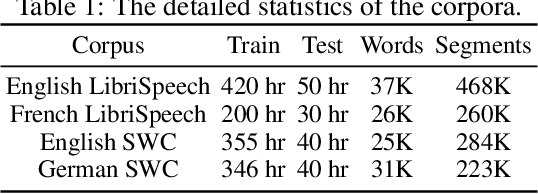

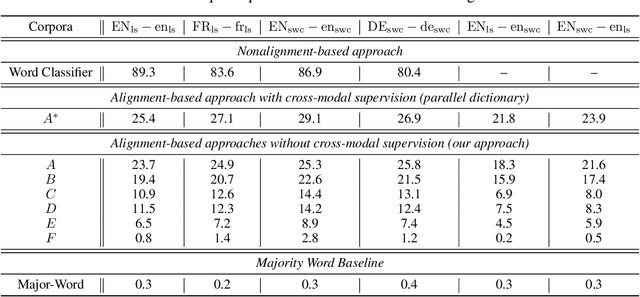

Recent research has shown that word embedding spaces learned from text corpora of different languages can be aligned without any parallel data supervision. Inspired by the success in unsupervised cross-lingual word embeddings, in this paper we target learning a cross-modal alignment between the embedding spaces of speech and text learned from corpora of their respective modalities in an unsupervised fashion. The proposed framework learns the individual speech and text embedding spaces, and attempts to align the two spaces via adversarial training, followed by a refinement procedure. We show how our framework could be used to perform spoken word classification and translation, and the results on these two tasks demonstrate that the performance of our unsupervised alignment approach is comparable to its supervised counterpart. Our framework is especially useful for developing automatic speech recognition (ASR) and speech-to-text translation systems for low- or zero-resource languages, which have little parallel audio-text data for training modern supervised ASR and speech-to-text translation models, but account for the majority of the languages spoken across the world.
Semi-Supervised Training for Improving Data Efficiency in End-to-End Speech Synthesis
Aug 30, 2018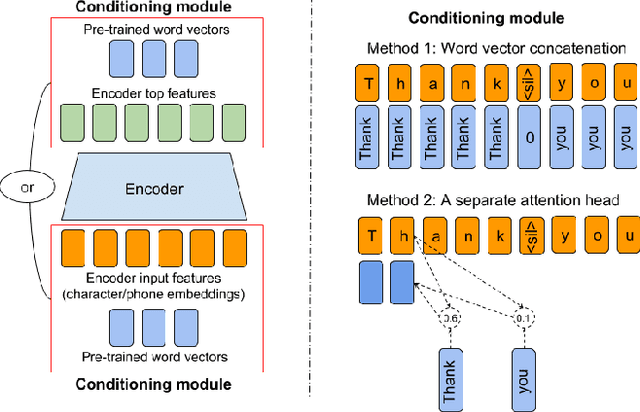
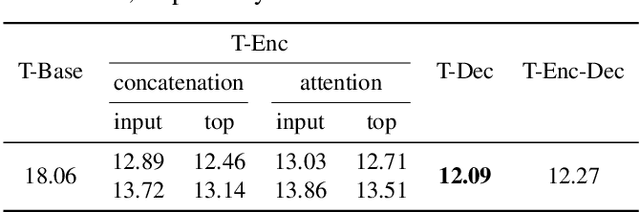
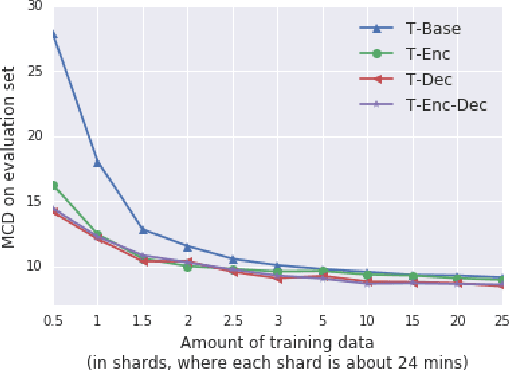
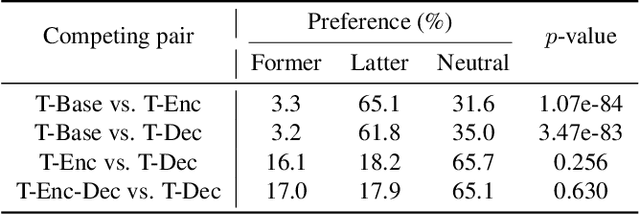
Although end-to-end text-to-speech (TTS) models such as Tacotron have shown excellent results, they typically require a sizable set of high-quality <text, audio> pairs for training, which are expensive to collect. In this paper, we propose a semi-supervised training framework to improve the data efficiency of Tacotron. The idea is to allow Tacotron to utilize textual and acoustic knowledge contained in large, publicly-available text and speech corpora. Importantly, these external data are unpaired and potentially noisy. Specifically, first we embed each word in the input text into word vectors and condition the Tacotron encoder on them. We then use an unpaired speech corpus to pre-train the Tacotron decoder in the acoustic domain. Finally, we fine-tune the model using available paired data. We demonstrate that the proposed framework enables Tacotron to generate intelligible speech using less than half an hour of paired training data.
Speech2Vec: A Sequence-to-Sequence Framework for Learning Word Embeddings from Speech
Jun 09, 2018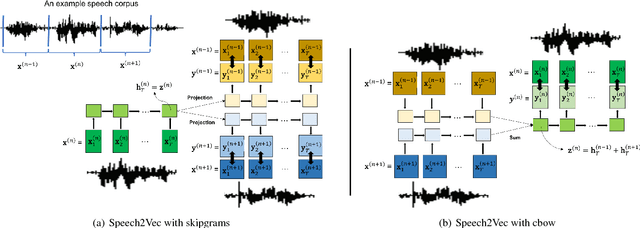
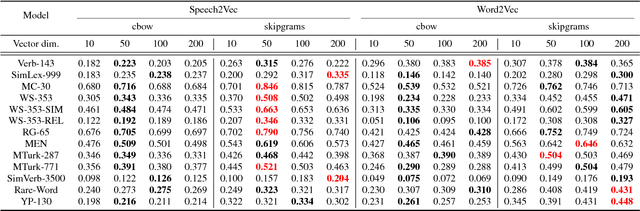
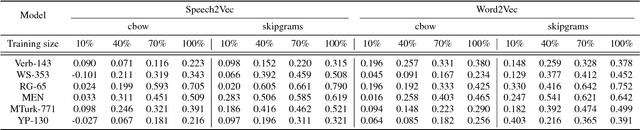
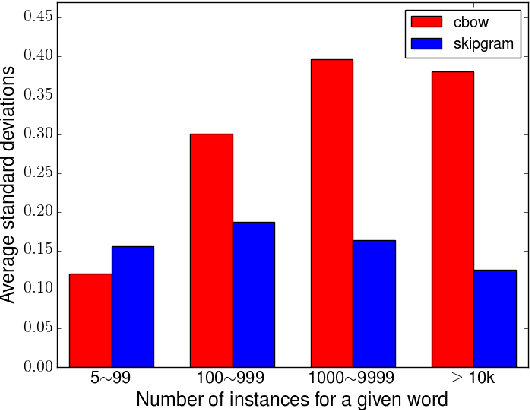
In this paper, we propose a novel deep neural network architecture, Speech2Vec, for learning fixed-length vector representations of audio segments excised from a speech corpus, where the vectors contain semantic information pertaining to the underlying spoken words, and are close to other vectors in the embedding space if their corresponding underlying spoken words are semantically similar. The proposed model can be viewed as a speech version of Word2Vec. Its design is based on a RNN Encoder-Decoder framework, and borrows the methodology of skipgrams or continuous bag-of-words for training. Learning word embeddings directly from speech enables Speech2Vec to make use of the semantic information carried by speech that does not exist in plain text. The learned word embeddings are evaluated and analyzed on 13 widely used word similarity benchmarks, and outperform word embeddings learned by Word2Vec from the transcriptions.
Supervised and Unsupervised Transfer Learning for Question Answering
Apr 21, 2018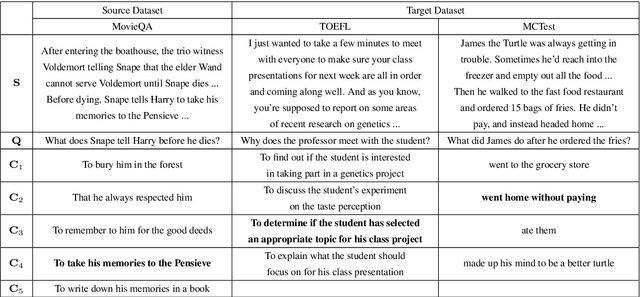
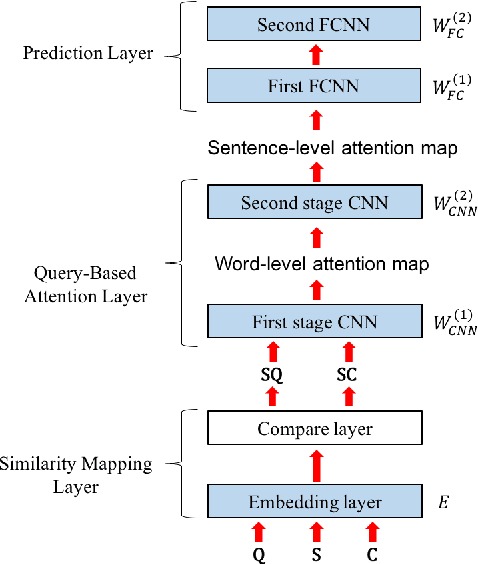
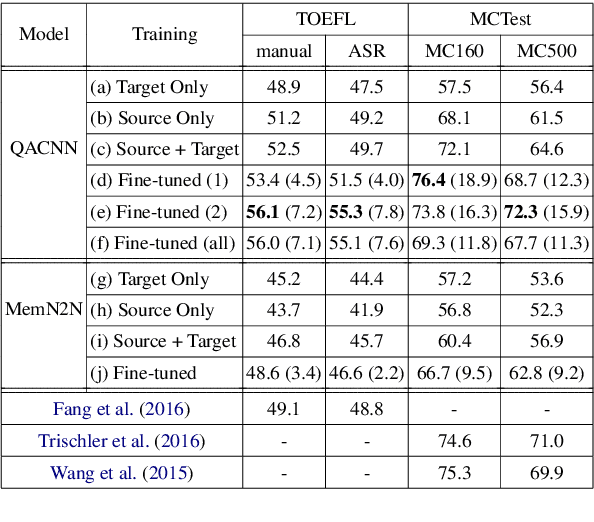
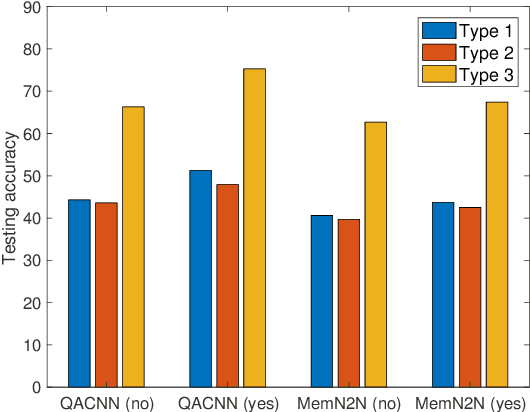
Although transfer learning has been shown to be successful for tasks like object and speech recognition, its applicability to question answering (QA) has yet to be well-studied. In this paper, we conduct extensive experiments to investigate the transferability of knowledge learned from a source QA dataset to a target dataset using two QA models. The performance of both models on a TOEFL listening comprehension test (Tseng et al., 2016) and MCTest (Richardson et al., 2013) is significantly improved via a simple transfer learning technique from MovieQA (Tapaswi et al., 2016). In particular, one of the models achieves the state-of-the-art on all target datasets; for the TOEFL listening comprehension test, it outperforms the previous best model by 7%. Finally, we show that transfer learning is helpful even in unsupervised scenarios when correct answers for target QA dataset examples are not available.
Learning Deep Representations of Medical Images using Siamese CNNs with Application to Content-Based Image Retrieval
Dec 27, 2017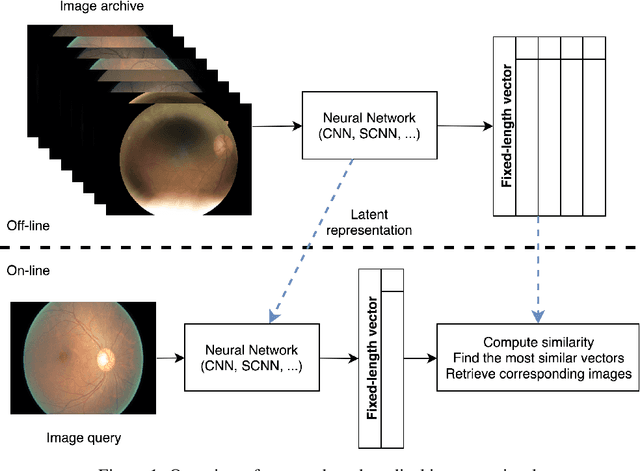
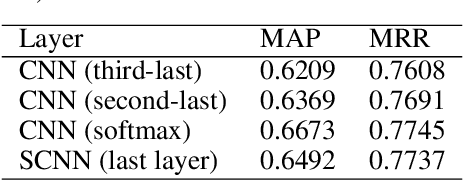
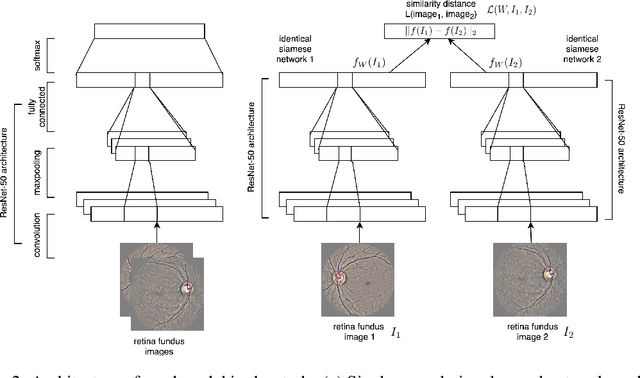
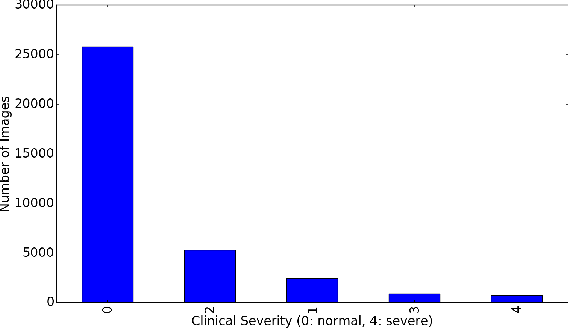
Deep neural networks have been investigated in learning latent representations of medical images, yet most of the studies limit their approach in a single supervised convolutional neural network (CNN), which usually rely heavily on a large scale annotated dataset for training. To learn image representations with less supervision involved, we propose a deep Siamese CNN (SCNN) architecture that can be trained with only binary image pair information. We evaluated the learned image representations on a task of content-based medical image retrieval using a publicly available multiclass diabetic retinopathy fundus image dataset. The experimental results show that our proposed deep SCNN is comparable to the state-of-the-art single supervised CNN, and requires much less supervision for training.
Learning Word Embeddings from Speech
Nov 05, 2017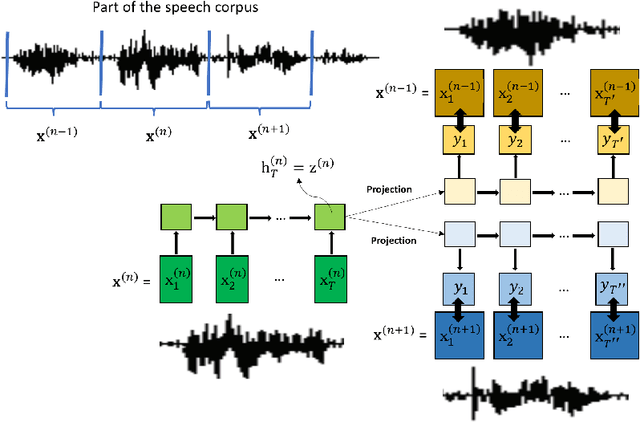
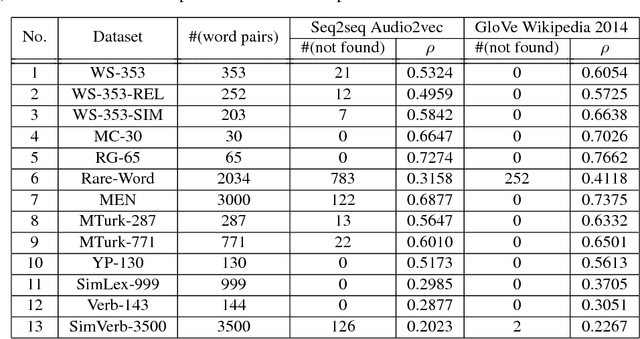
In this paper, we propose a novel deep neural network architecture, Sequence-to-Sequence Audio2Vec, for unsupervised learning of fixed-length vector representations of audio segments excised from a speech corpus, where the vectors contain semantic information pertaining to the segments, and are close to other vectors in the embedding space if their corresponding segments are semantically similar. The design of the proposed model is based on the RNN Encoder-Decoder framework, and borrows the methodology of continuous skip-grams for training. The learned vector representations are evaluated on 13 widely used word similarity benchmarks, and achieved competitive results to that of GloVe. The biggest advantage of the proposed model is its capability of extracting semantic information of audio segments taken directly from raw speech, without relying on any other modalities such as text or images, which are challenging and expensive to collect and annotate.