 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Benchmarking the Trustworthiness in Multimodal LLMs for Video Understanding
Jun 14, 2025Recent advancements in multimodal large language models for video understanding (videoLLMs) have improved their ability to process dynamic multimodal data. However, trustworthiness challenges factual inaccuracies, harmful content, biases, hallucinations, and privacy risks, undermine reliability due to video data's spatiotemporal complexities. This study introduces Trust-videoLLMs, a comprehensive benchmark evaluating videoLLMs across five dimensions: truthfulness, safety, robustness, fairness, and privacy. Comprising 30 tasks with adapted, synthetic, and annotated videos, the framework assesses dynamic visual scenarios, cross-modal interactions, and real-world safety concerns. Our evaluation of 23 state-of-the-art videoLLMs (5 commercial,18 open-source) reveals significant limitations in dynamic visual scene understanding and cross-modal perturbation resilience. Open-source videoLLMs show occasional truthfulness advantages but inferior overall credibility compared to commercial models, with data diversity outperforming scale effects. These findings highlight the need for advanced safety alignment to enhance capabilities. Trust-videoLLMs provides a publicly available, extensible toolbox for standardized trustworthiness assessments, bridging the gap between accuracy-focused benchmarks and critical demands for robustness, safety, fairness, and privacy.
Iterative Adversarial Attack on Image-guided Story Ending Generation
May 16, 2023



Multimodal learning involves developing models that can integrate information from various sources like images and texts. In this field, multimodal text generation is a crucial aspect that involves processing data from multiple modalities and outputting text. The image-guided story ending generation (IgSEG) is a particularly significant task, targeting on an understanding of complex relationships between text and image data with a complete story text ending. Unfortunately, deep neural networks, which are the backbone of recent IgSEG models, are vulnerable to adversarial samples. Current adversarial attack methods mainly focus on single-modality data and do not analyze adversarial attacks for multimodal text generation tasks that use cross-modal information. To this end, we propose an iterative adversarial attack method (Iterative-attack) that fuses image and text modality attacks, allowing for an attack search for adversarial text and image in an more effective iterative way. Experimental results demonstrate that the proposed method outperforms existing single-modal and non-iterative multimodal attack methods, indicating the potential for improving the adversarial robustness of multimodal text generation models, such as multimodal machine translation, multimodal question answering, etc.
Efficient Graph Deep Learning in TensorFlow with tf_geometric
Jan 27, 2021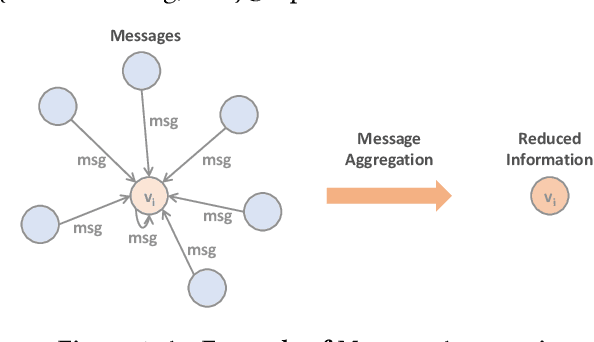
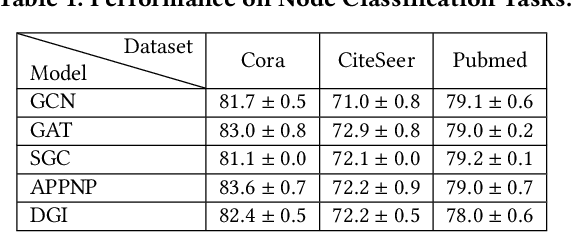
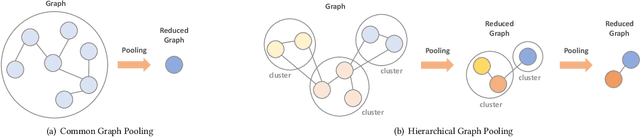
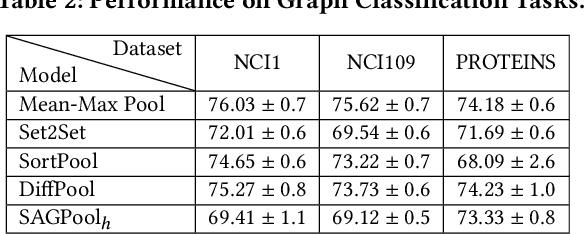
We introduce tf_geometric, an efficient and friendly library for graph deep learning, which is compatible with both TensorFlow 1.x and 2.x. tf_geometric provides kernel libraries for building Graph Neural Networks (GNNs) as well as implementations of popular GNNs. The kernel libraries consist of infrastructures for building efficient GNNs, including graph data structures, graph map-reduce framework, graph mini-batch strategy, etc. These infrastructures enable tf_geometric to support single-graph computation, multi-graph computation, graph mini-batch, distributed training, etc.; therefore, tf_geometric can be used for a variety of graph deep learning tasks, such as transductive node classification, inductive node classification, link prediction, and graph classification. Based on the kernel libraries, tf_geometric implements a variety of popular GNN models for different tasks. To facilitate the implementation of GNNs, tf_geometric also provides some other libraries for dataset management, graph sampling, etc. Different from existing popular GNN libraries, tf_geometric provides not only Object-Oriented Programming (OOP) APIs, but also Functional APIs, which enable tf_geometric to handle advanced graph deep learning tasks such as graph meta-learning. The APIs of tf_geometric are friendly, and they are suitable for both beginners and experts. In this paper, we first present an overview of tf_geometric's framework. Then, we conduct experiments on some benchmark datasets and report the performance of several popular GNN models implemented by tf_geometric.