 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabular Transformers for Modeling Multivariate Time Series
Nov 03, 2020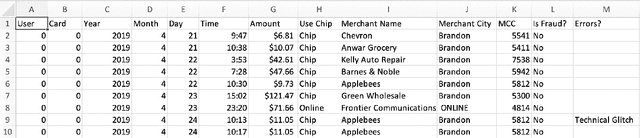

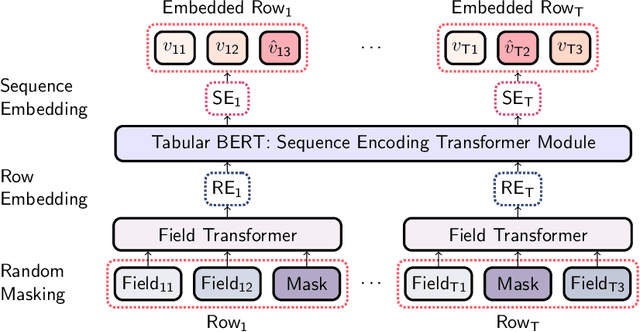
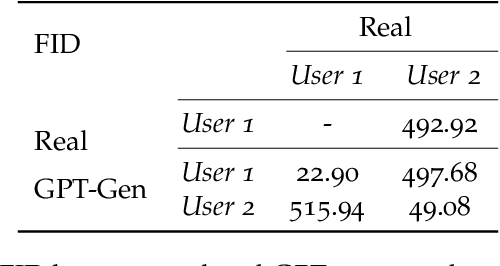
Tabular datasets are ubiquitous in data science applications. Given their importance, it seems natural to apply state-of-the-art deep learning algorithms in order to fully unlock their potential. Here we propose neural network models that represent tabular time series that can optionally leverage their hierarchical structure. This results in two architectures for tabular time series: one for learning representations that is analogous to BERT and can be pre-trained end-to-end and used in downstream tasks, and one that is akin to GPT and can be used for generation of realistic synthetic tabular sequences. We demonstrate our models on two datasets: a synthetic credit card transaction dataset, where the learned representations are used for fraud detection and synthetic data generation, and on a real pollution dataset, where the learned encodings are used to predict atmospheric pollutant concentrations. Code and data are available at https://github.com/IBM/TabFormer.
Unbalanced Sobolev Descent
Sep 29, 2020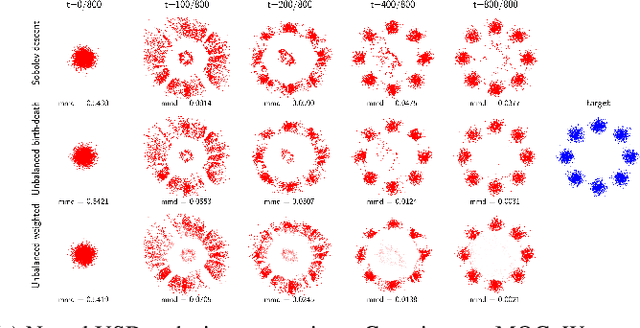



We introduce Unbalanced Sobolev Descent (USD), a particle descent algorithm for transporting a high dimensional source distribution to a target distribution that does not necessarily have the same mass. We define the Sobolev-Fisher discrepancy between distributions and show that it relates to advection-reaction transport equations and the Wasserstein-Fisher-Rao metric between distributions. USD transports particles along gradient flows of the witness function of the Sobolev-Fisher discrepancy (advection step) and reweighs the mass of particles with respect to this witness function (reaction step). The reaction step can be thought of as a birth-death process of the particles with rate of growth proportional to the witness function. When the Sobolev-Fisher witness function is estimated in a Reproducing Kernel Hilbert Space (RKHS), under mild assumptions we show that USD converges asymptotically (in the limit of infinite particles) to the target distribution in the Maximum Mean Discrepancy (MMD) sense. We then give two methods to estimate the Sobolev-Fisher witness with neural networks, resulting in two Neural USD algorithms. The first one implements the reaction step with mirror descent on the weights, while the second implements it through a birth-death process of particles. We show on synthetic examples that USD transports distributions with or without conservation of mass faster than previous particle descent algorithms, and finally demonstrate its use for molecular biology analyses where our method is naturally suited to match developmental stages of populations of differentiating cells based on their single-cell RNA sequencing profile. Code is available at https://github.com/ibm/usd .
Active learning of deep surrogates for PDEs: Application to metasurface design
Aug 24, 2020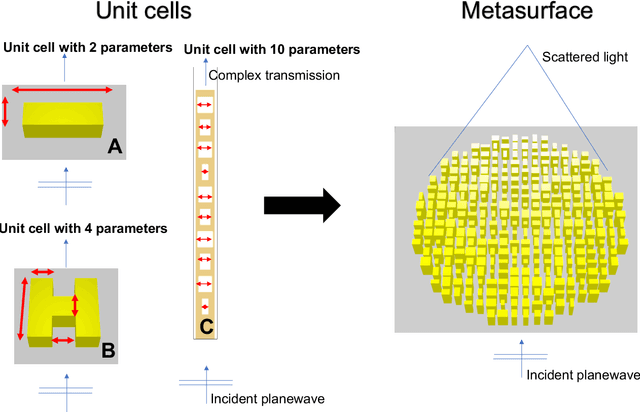
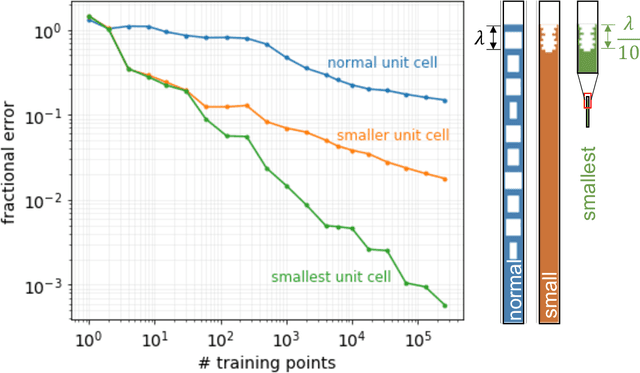
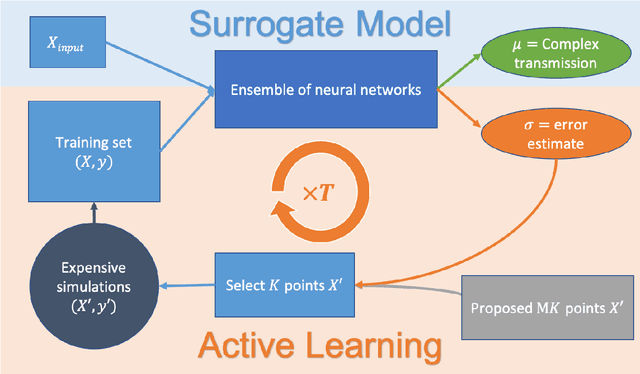
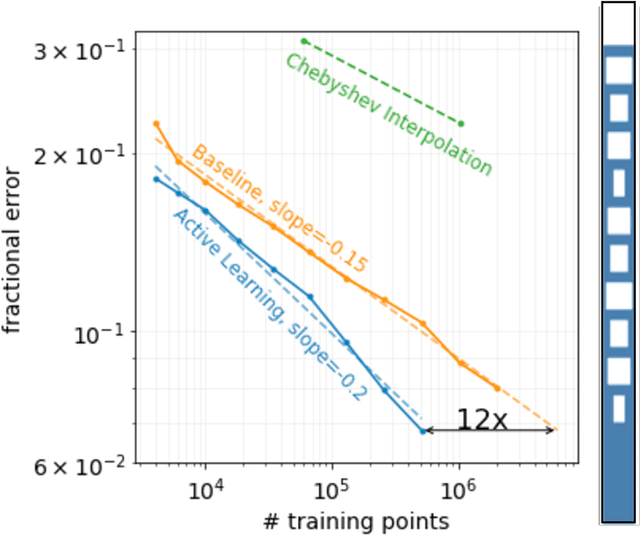
Surrogate models for partial-differential equations are widely used in the design of meta-materials to rapidly evaluate the behavior of composable components. However, the training cost of accurate surrogates by machine learning can rapidly increase with the number of variables. For photonic-device models, we find that this training becomes especially challenging as design regions grow larger than the optical wavelength. We present an active learning algorithm that reduces the number of training points by more than an order of magnitude for a neural-network surrogate model of optical-surface components compared to random samples. Results show that the surrogate evaluation is over two orders of magnitude faster than a direct solve, and we demonstrate how this can be exploited to accelerate large-scale engineering optimization.
Kernel Stein Generative Modeling
Jul 06, 2020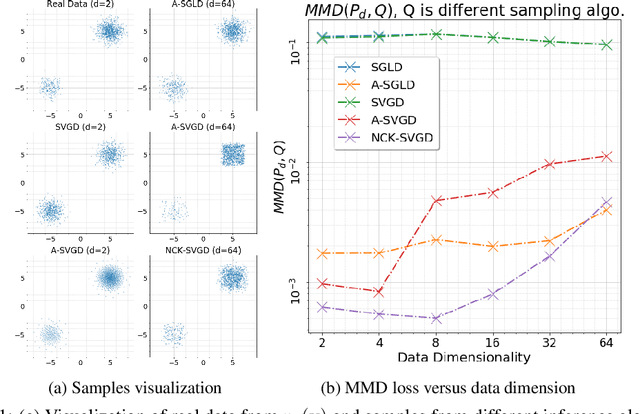
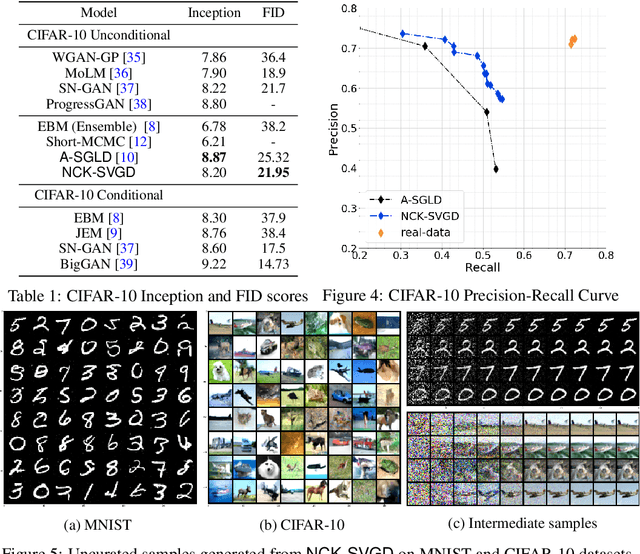
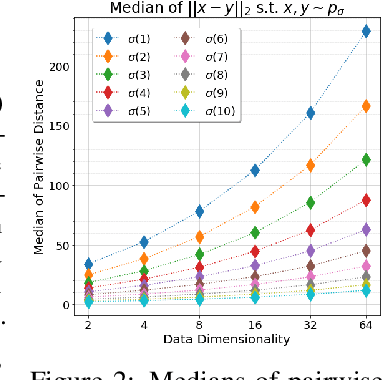
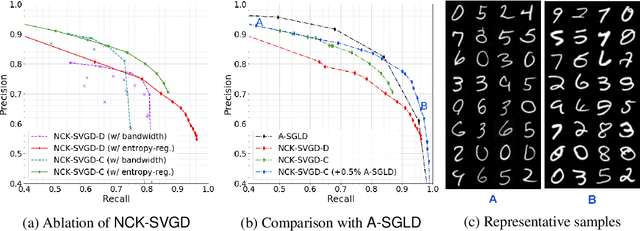
We are interested in gradient-based Explicit Generative Modeling where samples can be derived from iterative gradient updates based on an estimate of the score function of the data distribution. Recent advances in Stochastic Gradient Langevin Dynamics (SGLD) demonstrates impressive results with energy-based models on high-dimensional and complex data distributions. Stein Variational Gradient Descent (SVGD) is a deterministic sampling algorithm that iteratively transports a set of particles to approximate a given distribution, based on functional gradient descent that decreases the KL divergence. SVGD has promising results on several Bayesian inference applications. However, applying SVGD on high dimensional problems is still under-explored. The goal of this work is to study high dimensional inference with SVGD. We first identify key challenges in practical kernel SVGD inference in high-dimension. We propose noise conditional kernel SVGD (NCK-SVGD), that works in tandem with the recently introduced Noise Conditional Score Network estimator. NCK is crucial for successful inference with SVGD in high dimension, as it adapts the kernel to the noise level of the score estimate. As we anneal the noise, NCK-SVGD targets the real data distribution. We then extend the annealed SVGD with an entropic regularization. We show that this offers a flexible control between sample quality and diversity, and verify it empirically by precision and recall evaluations. The NCK-SVGD produces samples comparable to GANs and annealed SGLD on computer vision benchmarks, including MNIST and CIFAR-10.
Fast Mixing of Multi-Scale Langevin Dynamics under the Manifold Hypothesis
Jun 22, 2020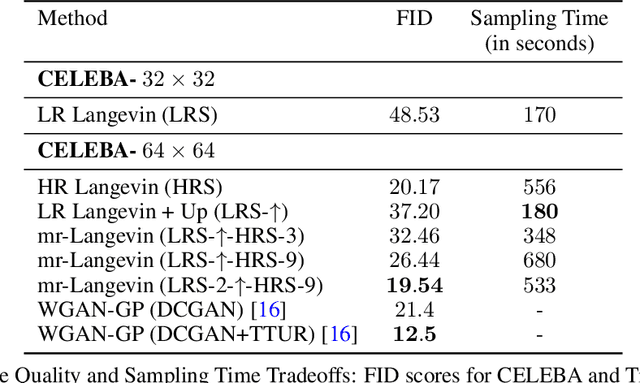

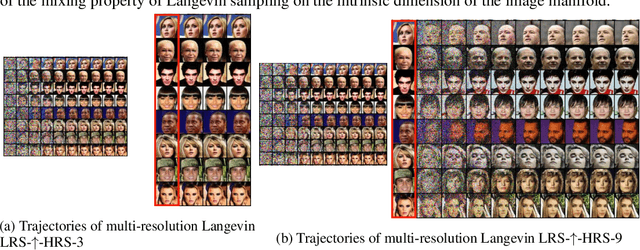
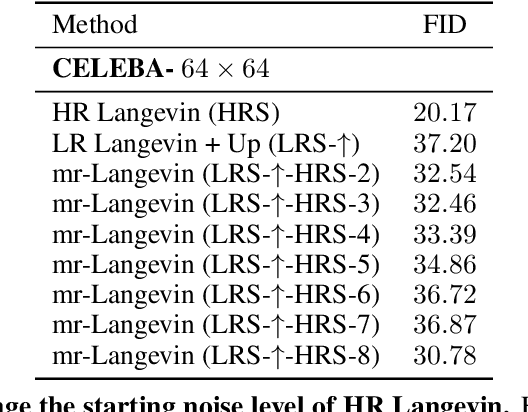
Recently, the task of image generation has attracted much attention. In particular, the recent empirical successes of the Markov Chain Monte Carlo (MCMC) technique of Langevin Dynamics have prompted a number of theoretical advances; despite this, several outstanding problems remain. First, the Langevin Dynamics is run in very high dimension on a nonconvex landscape; in the worst case, due to the NP-hardness of nonconvex optimization, it is thought that Langevin Dynamics mixes only in time exponential in the dimension. In this work, we demonstrate how the manifold hypothesis allows for the considerable reduction of mixing time, from exponential in the ambient dimension to depending only on the (much smaller) intrinsic dimension of the data. Second, the high dimension of the sampling space significantly hurts the performance of Langevin Dynamics; we leverage a multi-scale approach to help ameliorate this issue and observe that this multi-resolution algorithm allows for a trade-off between image quality and computational expense in generation.
Learning Implicit Text Generation via Feature Matching
May 09, 2020
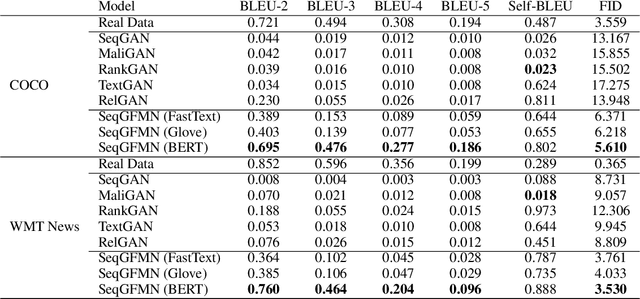
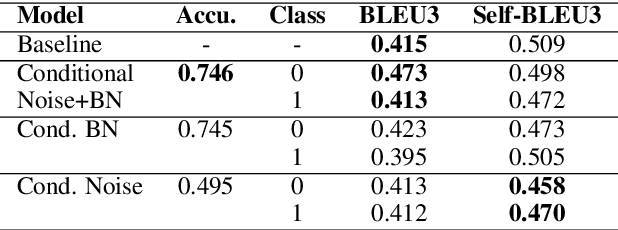
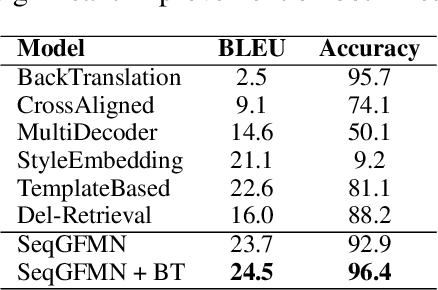
Generative feature matching network (GFMN) is an approach for training implicit generative models for images by performing moment matching on features from pre-trained neural networks. In this paper, we present new GFMN formulations that are effective for sequential data. Our experimental results show the effectiveness of the proposed method, SeqGFMN, for three distinct generation tasks in English: unconditional text generation, class-conditional text generation, and unsupervised text style transfer. SeqGFMN is stable to train and outperforms various adversarial approaches for text generation and text style transfer.
Generative Modeling with Denoising Auto-Encoders and Langevin Sampling
Feb 17, 2020We study convergence of a generative modeling method that first estimates the score function of the distribution using Denoising Auto-Encoders (DAE) or Denoising Score Matching (DSM) and then employs Langevin diffusion for sampling. We show that both DAE and DSM provide estimates of the score of the Gaussian smoothed population density, allowing us to apply the machinery of Empirical Processes. We overcome the challenge of relying only on $L^2$ bounds on the score estimation error and provide finite-sample bounds in the Wasserstein distance between the law of the population distribution and the law of this sampling scheme. We then apply our results to the homotopy method of arXiv:1907.05600 and provide theoretical justification for its empirical success.
Improving Efficiency in Large-Scale Decentralized Distributed Training
Feb 04, 2020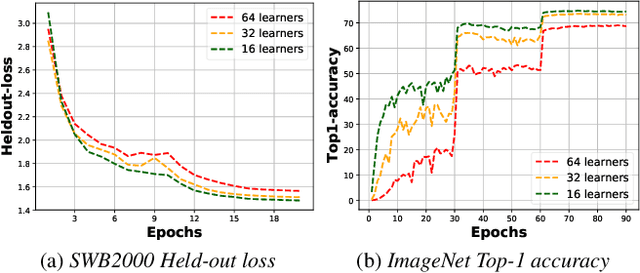
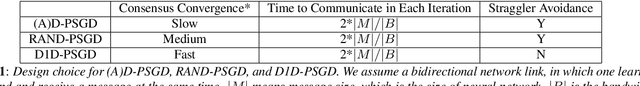
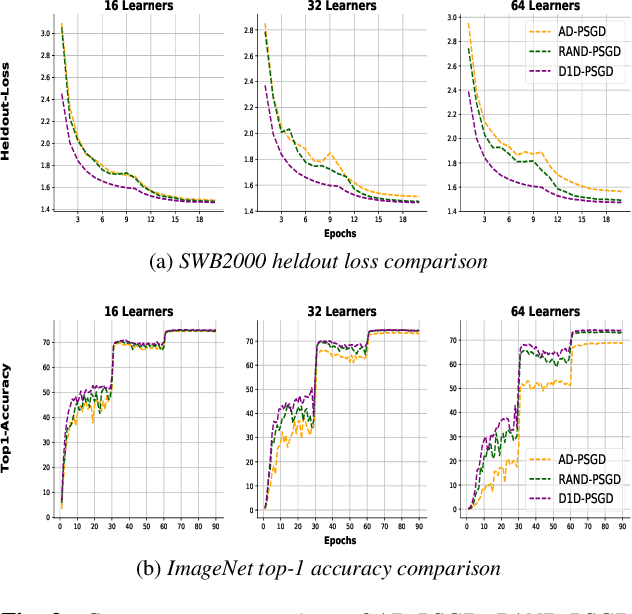

Decentralized Parallel SGD (D-PSGD) and its asynchronous variant Asynchronous Parallel SGD (AD-PSGD) is a family of distributed learning algorithms that have been demonstrated to perform well for large-scale deep learning tasks. One drawback of (A)D-PSGD is that the spectral gap of the mixing matrix decreases when the number of learners in the system increases, which hampers convergence. In this paper, we investigate techniques to accelerate (A)D-PSGD based training by improving the spectral gap while minimizing the communication cost. We demonstrate the effectiveness of our proposed techniques by running experiments on the 2000-hour Switchboard speech recognition task and the ImageNet computer vision task. On an IBM P9 supercomputer, our system is able to train an LSTM acoustic model in 2.28 hours with 7.5% WER on the Hub5-2000 Switchboard (SWB) test set and 13.3% WER on the CallHome (CH) test set using 64 V100 GPUs and in 1.98 hours with 7.7% WER on SWB and 13.3% WER on CH using 128 V100 GPUs, the fastest training time reported to date.
Towards Better Understanding of Adaptive Gradient Algorithms in Generative Adversarial Nets
Dec 26, 2019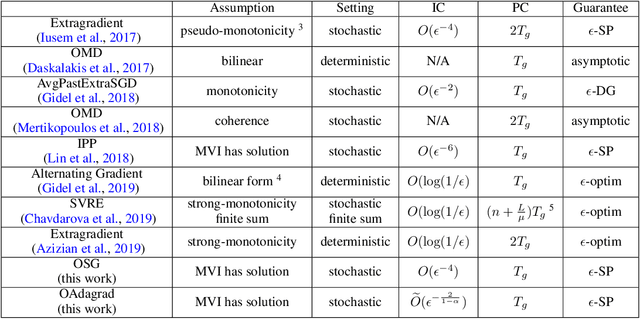
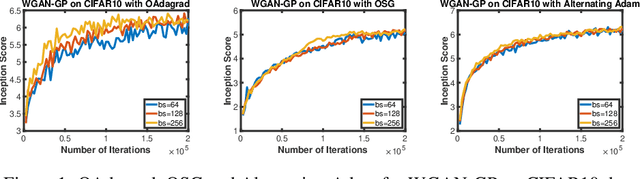
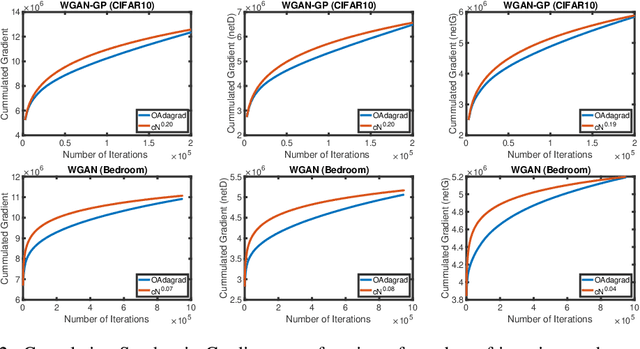
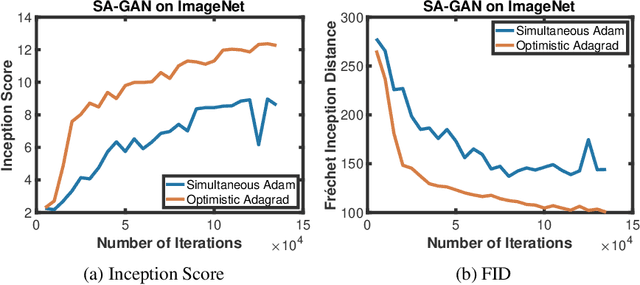
Adaptive gradient algorithms perform gradient-based updates using the history of gradients and are ubiquitous in training deep neural networks. While adaptive gradient methods theory is well understood for minimization problems, the underlying factors driving their empirical success in min-max problems such as GANs remain unclear. In this paper, we aim at bridging this gap from both theoretical and empirical perspectives. First, we analyze a variant of Optimistic Stochastic Gradient (OSG) proposed in~\citep{daskalakis2017training} for solving a class of non-convex non-concave min-max problem and establish $O(\epsilon^{-4})$ complexity for finding $\epsilon$-first-order stationary point, in which the algorithm only requires invoking one stochastic first-order oracle while enjoying state-of-the-art iteration complexity achieved by stochastic extragradient method by~\citep{iusem2017extragradient}. Then we propose an adaptive variant of OSG named Optimistic Adagrad (OAdagrad) and reveal an \emph{improved} adaptive complexity $\widetilde{O}\left(\epsilon^{-\frac{2}{1-\alpha}}\right)$~\footnote{Here $\widetilde{O}(\cdot)$ compresses a logarithmic factor of $\epsilon$.}, where $\alpha$ characterizes the growth rate of the cumulative stochastic gradient and $0\leq \alpha\leq 1/2$. To the best of our knowledge, this is the first work for establishing adaptive complexity in non-convex non-concave min-max optimization. Empirically, our experiments show that indeed adaptive gradient algorithms outperform their non-adaptive counterparts in GAN training. Moreover, this observation can be explained by the slow growth rate of the cumulative stochastic gradient, as observed empirically.
Unsupervised Hierarchy Matching with Optimal Transport over Hyperbolic Spaces
Nov 06, 2019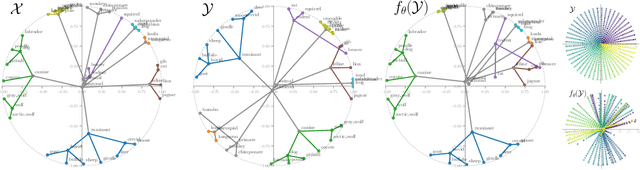
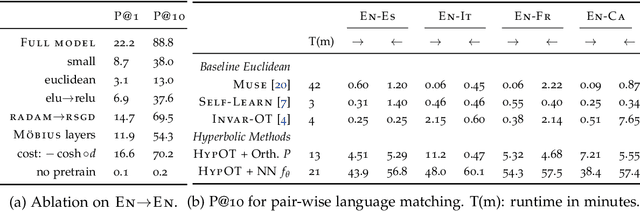
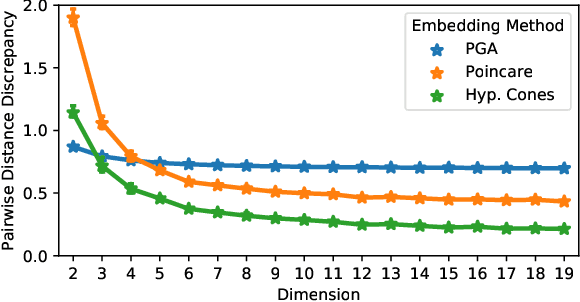
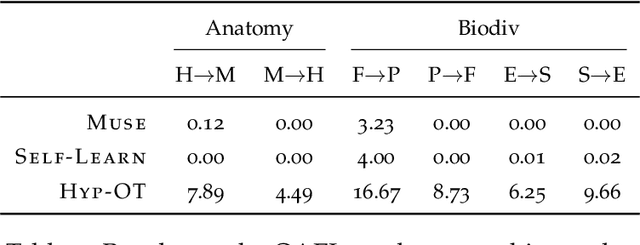
This paper focuses on the problem of unsupervised alignment of hierarchical data such as ontologies or lexical databases. This is a problem that appears across areas, from natural language processing to bioinformatics, and is typically solved by appeal to outside knowledge bases and label-textual similarity. In contrast, we approach the problem from a purely geometric perspective: given only a vector-space representation of the items in the two hierarchies, we seek to infer correspondences across them. Our work derives from and interweaves hyperbolic-space representations for hierarchical data, on one hand, and unsupervised word-alignment methods, on the other. We first provide a set of negative results showing how and why Euclidean methods fail in this hyperbolic setting. We then propose a novel approach based on optimal transport over hyperbolic spaces, and show that it outperforms standard embedding alignment techniques in various experiments on cross-lingual WordNet alignment and ontology matching tasks.