 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycle Consistent Probability Divergences Across Different Spaces
Nov 22, 2021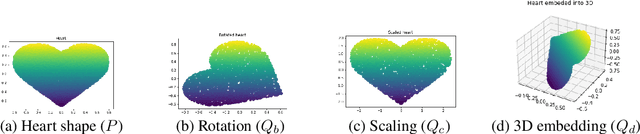
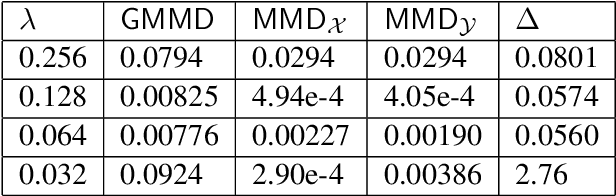
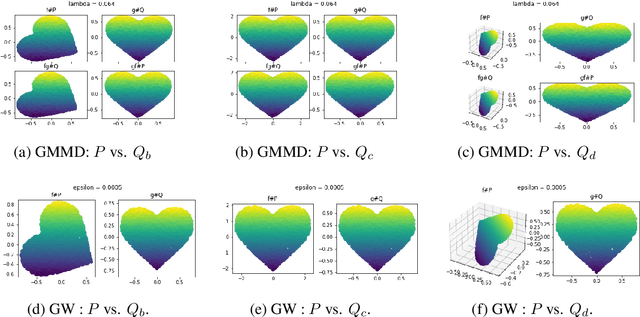
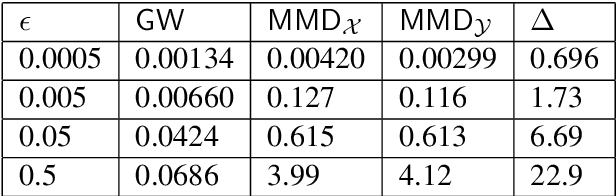
Discrepancy measures between probability distributions are at the core of statistical inference and machine learning. In many applications, distributions of interest are supported on different spaces, and yet a meaningful correspondence between data points is desired. Motivated to explicitly encode consistent bidirectional maps into the discrepancy measure, this work proposes a novel unbalanced Monge optimal transport formulation for matching, up to isometries, distributions on different spaces. Our formulation arises as a principled relaxation of the Gromov-Haussdroff distance between metric spaces, and employs two cycle-consistent maps that push forward each distribution onto the other. We study structural properties of the proposed discrepancy and, in particular, show that it captures the popular cycle-consistent generative adversarial network (GAN) framework as a special case, thereby providing the theory to explain it. Motivated by computational efficiency, we then kernelize the discrepancy and restrict the mappings to parametric function classes. The resulting kernelized version is coined the generalized maximum mean discrepancy (GMMD). Convergence rates for empirical estimation of GMMD are studied and experiments to support our theory are provided.
Physics-enhanced deep surrogates for PDEs
Nov 10, 2021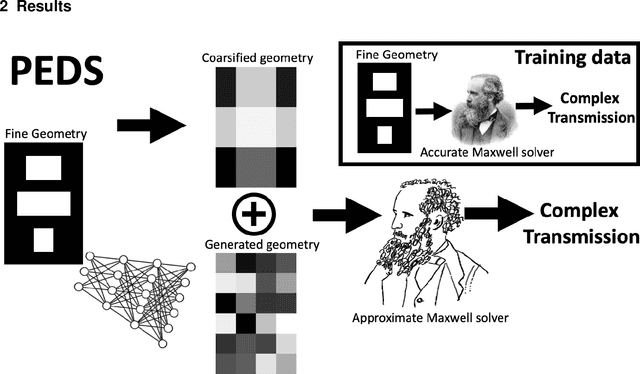

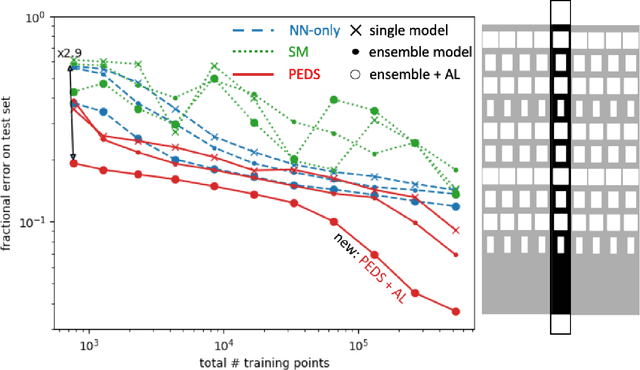
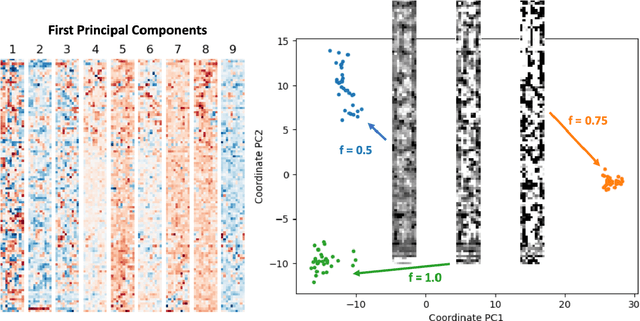
We present a "physics-enhanced deep-surrogate ("PEDS") approach towards developing fast surrogate models for complex physical systems described by partial differential equations (PDEs) and similar models: we show how to combine a low-fidelity "coarse" solver with a neural network that generates "coarsified'' inputs, trained end-to-end to globally match the output of an expensive high-fidelity numerical solver. In this way, by incorporating limited physical knowledge in the form of the low-fidelity model, we find that a PEDS surrogate can be trained with at least $\sim 10\times$ less data than a "black-box'' neural network for the same accuracy. Asymptotically, PEDS appears to learn with a steeper power law than black-box surrogates, and benefits even further when combined with active learning. We demonstrate feasibility and benefit of the proposed approach by using an example problem in electromagnetic scattering that appears in the design of optical metamaterials.
Tighter Sparse Approximation Bounds for ReLU Neural Networks
Oct 07, 2021A well-known line of work (Barron, 1993; Breiman, 1993; Klusowski & Barron, 2018) provides bounds on the width $n$ of a ReLU two-layer neural network needed to approximate a function $f$ over the ball $\mathcal{B}_R(\R^d)$ up to error $\epsilon$, when the Fourier based quantity $C_f = \int_{\R^d} \|\xi\|^2 |\hat{f}(\xi)| \ d\xi$ is finite. More recently Ongie et al. (2019) used the Radon transform as a tool for analysis of infinite-width ReLU two-layer networks. In particular, they introduce the concept of Radon-based $\mathcal{R}$-norms and show that a function defined on $\R^d$ can be represented as an infinite-width two-layer neural network if and only if its $\mathcal{R}$-norm is finite. In this work, we extend the framework of Ongie et al. (2019) and define similar Radon-based semi-norms ($\mathcal{R}, \mathcal{U}$-norms) such that a function admits an infinite-width neural network representation on a bounded open set $\mathcal{U} \subseteq \R^d$ when its $\mathcal{R}, \mathcal{U}$-norm is finite. Building on this, we derive sparse (finite-width) neural network approximation bounds that refine those of Breiman (1993); Klusowski & Barron (2018). Finally, we show that infinite-width neural network representations on bounded open sets are not unique and study their structure, providing a functional view of mode connectivity.
Separation Results between Fixed-Kernel and Feature-Learning Probability Metrics
Jun 29, 2021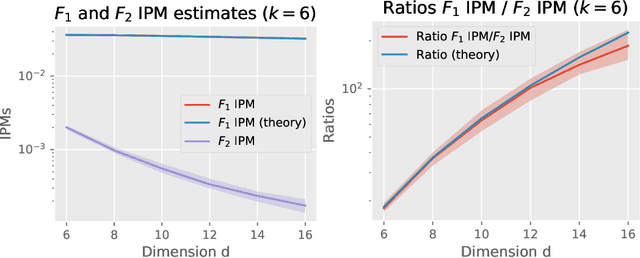
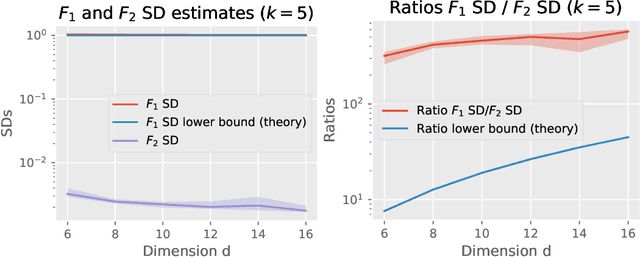
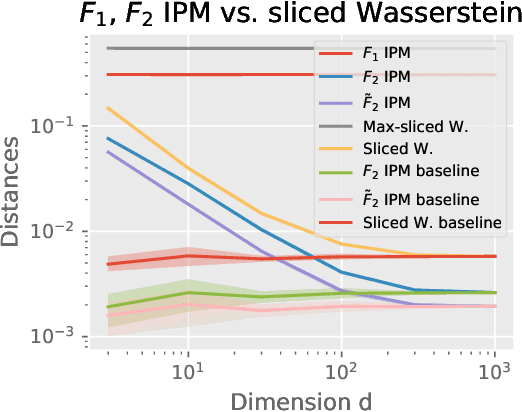
Several works in implicit and explicit generative modeling empirically observed that feature-learning discriminators outperform fixed-kernel discriminators in terms of the sample quality of the models. We provide separation results between probability metrics with fixed-kernel and feature-learning discriminators using the function classes $\mathcal{F}_2$ and $\mathcal{F}_1$ respectively, which were developed to study overparametrized two-layer neural networks. In particular, we construct pairs of distributions over hyper-spheres that can not be discriminated by fixed kernel $(\mathcal{F}_2)$ integral probability metric (IPM) and Stein discrepancy (SD) in high dimensions, but that can be discriminated by their feature learning ($\mathcal{F}_1$) counterparts. To further study the separation we provide links between the $\mathcal{F}_1$ and $\mathcal{F}_2$ IPMs with sliced Wasserstein distances. Our work suggests that fixed-kernel discriminators perform worse than their feature learning counterparts because their corresponding metrics are weaker.
Do Large Scale Molecular Language Representations Capture Important Structural Information?
Jun 17, 2021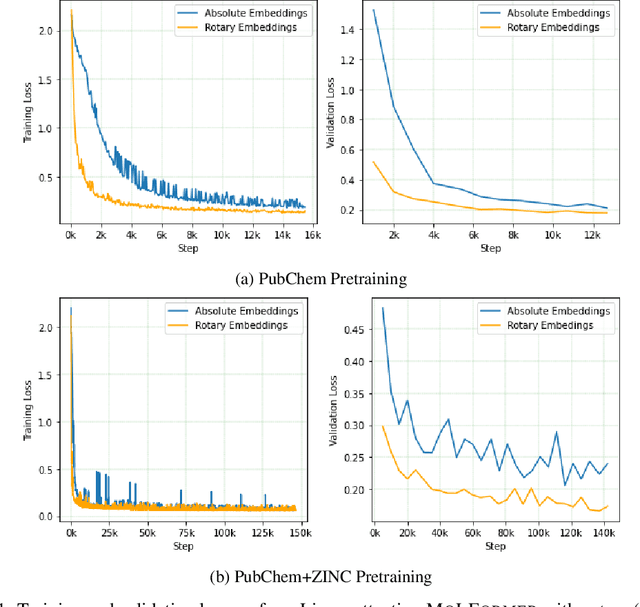
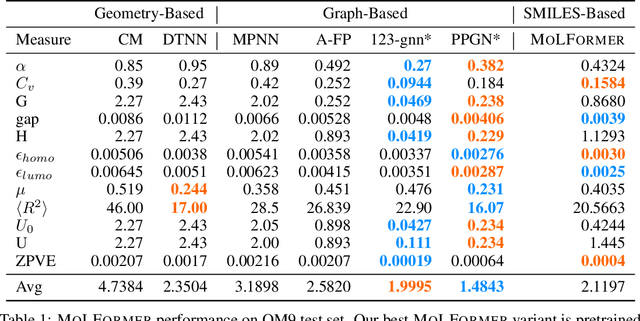
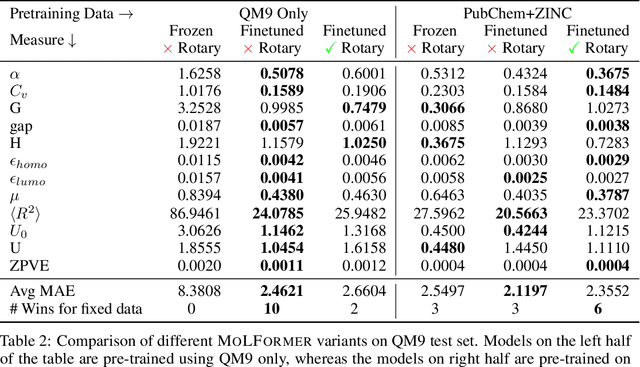
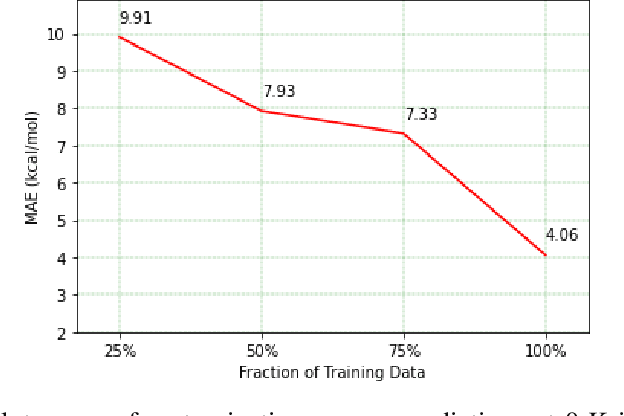
Predicting chemical properties from the structure of a molecule is of great importance in many applications including drug discovery and material design. Machine learning based molecular property prediction holds the promise of enabling accurate predictions at much less complexity, when compared to, for example Density Functional Theory (DFT) calculations. Features extracted from molecular graphs, using graph neural nets in a supervised manner, have emerged as strong baselines for such tasks. However, the vast chemical space together with the limited availability of labels makes supervised learning challenging, calling for learning a general-purpose molecular representation. Recently, pre-trained transformer-based language models (PTLMs) on large unlabeled corpus have produced state-of-the-art results in many downstream natural language processing tasks. Inspired by this development, here we present molecular embeddings obtained by training an efficient transformer encoder model, referred to as MoLFormer. This model was employed with a linear attention mechanism and highly paralleized training on 1D SMILES sequences of 1.1 billion unlabeled molecules from the PubChem and ZINC datasets. Experiments show that the learned molecular representation performs competitively, when compared to existing graph-based and fingerprint-based supervised learning baselines, on the challenging tasks of predicting properties of QM8 and QM9 molecules. Further task-specific fine-tuning of the MoLFormerr representation improves performance on several of those property prediction benchmarks. These results provide encouraging evidence that large-scale molecular language models can capture sufficient structural information to be able to accurately predict quantum chemical properties and beyond.
Optimizing Functionals on the Space of Probabilities with Input Convex Neural Networks
Jun 14, 2021
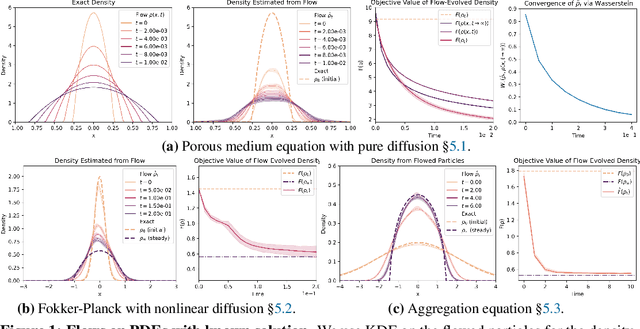
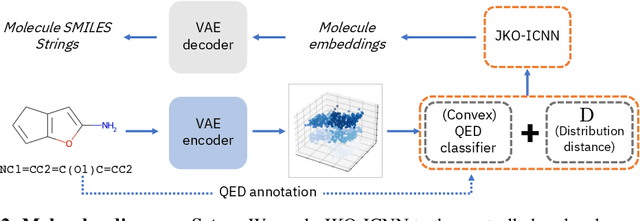
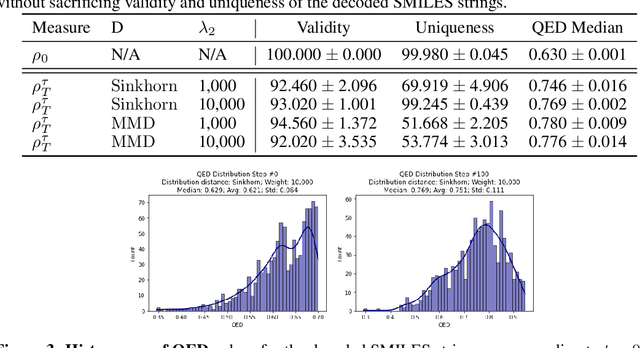
Gradient flows are a powerful tool for optimizing functionals in general metric spaces, including the space of probabilities endowed with the Wasserstein metric. A typical approach to solving this optimization problem relies on its connection to the dynamic formulation of optimal transport and the celebrated Jordan-Kinderlehrer-Otto (JKO) scheme. However, this formulation involves optimization over convex functions, which is challenging, especially in high dimensions. In this work, we propose an approach that relies on the recently introduced input-convex neural networks (ICNN) to parameterize the space of convex functions in order to approximate the JKO scheme, as well as in designing functionals over measures that enjoy convergence guarantees. We derive a computationally efficient implementation of this JKO-ICNN framework and use various experiments to demonstrate its feasibility and validity in approximating solutions of low-dimensional partial differential equations with known solutions. We also explore the use of our JKO-ICNN approach in high dimensions with an experiment in controlled generation for molecular discovery.
Measuring Generalization with Optimal Transport
Jun 07, 2021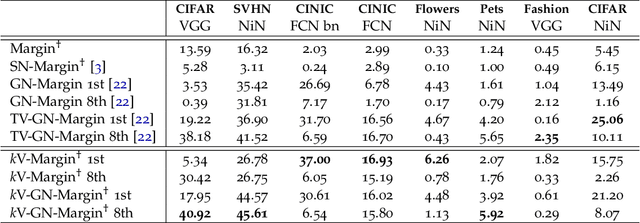
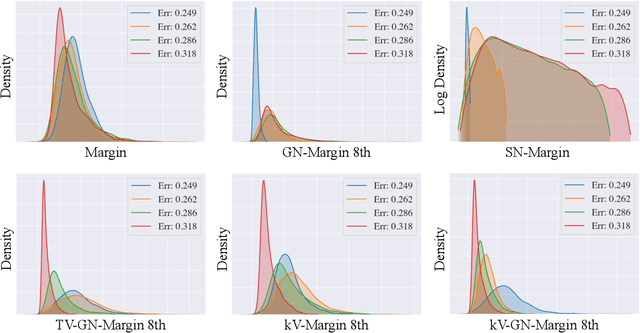

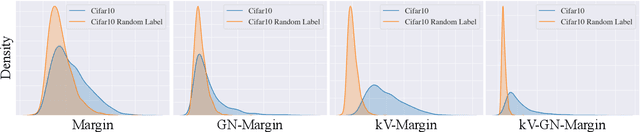
Understanding the generalization of deep neural networks is one of the most important tasks in deep learning. Although much progress has been made, theoretical error bounds still often behave disparately from empirical observations. In this work, we develop margin-based generalization bounds, where the margins are normalized with optimal transport costs between independent random subsets sampled from the training distribution. In particular, the optimal transport cost can be interpreted as a generalization of variance which captures the structural properties of the learned feature space. Our bounds robustly predict the generalization error, given training data and network parameters, on large scale datasets. Theoretically, we demonstrate that the concentration and separation of features play crucial roles in generalization, supporting empirical results in the literature. The code is available at \url{https://github.com/chingyaoc/kV-Margin}.
Fair Mixup: Fairness via Interpolation
Mar 11, 2021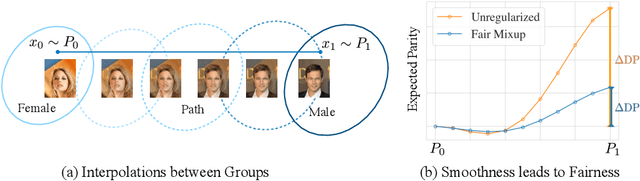
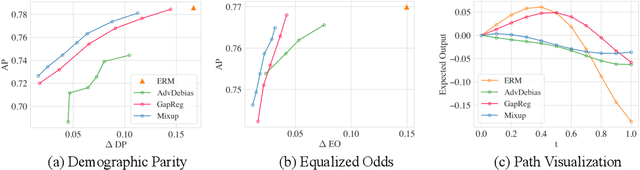
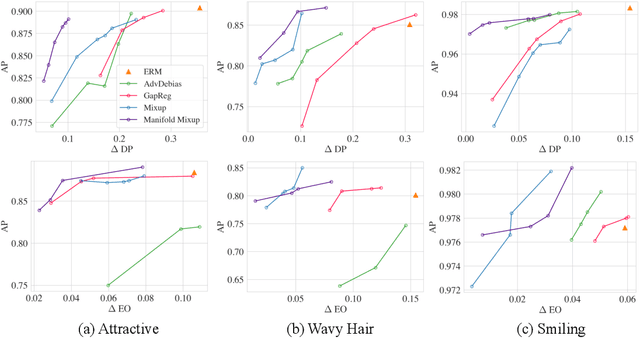
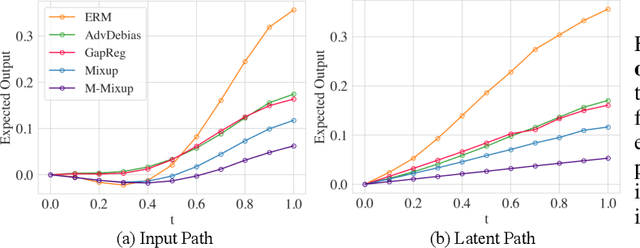
Training classifiers under fairness constraints such as group fairness, regularizes the disparities of predictions between the groups. Nevertheless, even though the constraints are satisfied during training, they might not generalize at evaluation time. To improve the generalizability of fair classifiers, we propose fair mixup, a new data augmentation strategy for imposing the fairness constraint. In particular, we show that fairness can be achieved by regularizing the models on paths of interpolated samples between the groups. We use mixup, a powerful data augmentation strategy to generate these interpolates. We analyze fair mixup and empirically show that it ensures a better generalization for both accuracy and fairness measurement in tabular, vision, and language benchmarks.
Image Captioning as an Assistive Technology: Lessons Learned from VizWiz 2020 Challenge
Dec 21, 2020
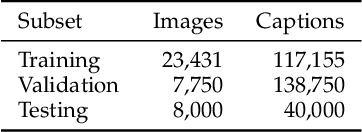
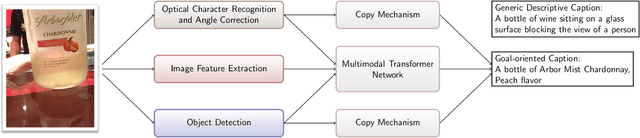
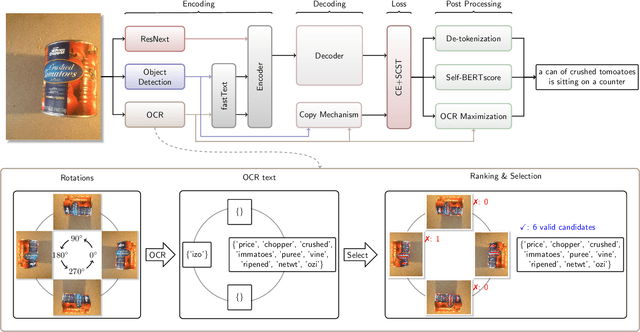
Image captioning has recently demonstrated impressive progress largely owing to the introduction of neural network algorithms trained on curated dataset like MS-COCO. Often work in this field is motivated by the promise of deployment of captioning systems in practical applications. However, the scarcity of data and contexts in many competition datasets renders the utility of systems trained on these datasets limited as an assistive technology in real-world settings, such as helping visually impaired people navigate and accomplish everyday tasks. This gap motivated the introduction of the novel VizWiz dataset, which consists of images taken by the visually impaired and captions that have useful, task-oriented information. In an attempt to help the machine learning computer vision field realize its promise of producing technologies that have positive social impact, the curators of the VizWiz dataset host several competitions, including one for image captioning. This work details the theory and engineering from our winning submission to the 2020 captioning competition. Our work provides a step towards improved assistive image captioning systems.
Alleviating Noisy Data in Image Captioning with Cooperative Distillation
Dec 21, 2020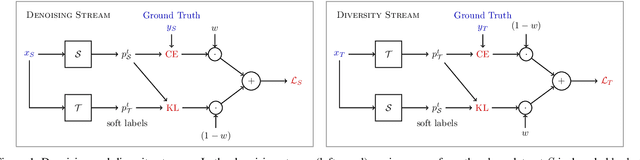

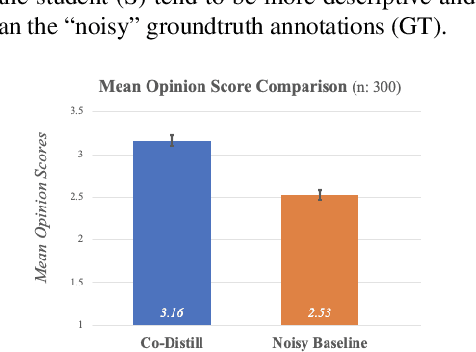
Image captioning systems have made substantial progress, largely due to the availability of curated datasets like Microsoft COCO or Vizwiz that have accurate descriptions of their corresponding images. Unfortunately, scarce availability of such cleanly labeled data results in trained algorithms producing captions that can be terse and idiosyncratically specific to details in the image. We propose a new technique, cooperative distillation that combines clean curated datasets with the web-scale automatically extracted captions of the Google Conceptual Captions dataset (GCC), which can have poor descriptions of images, but is abundant in size and therefore provides a rich vocabulary resulting in more expressive captions.