 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Convolutional Filters with SincNet
Nov 23, 2018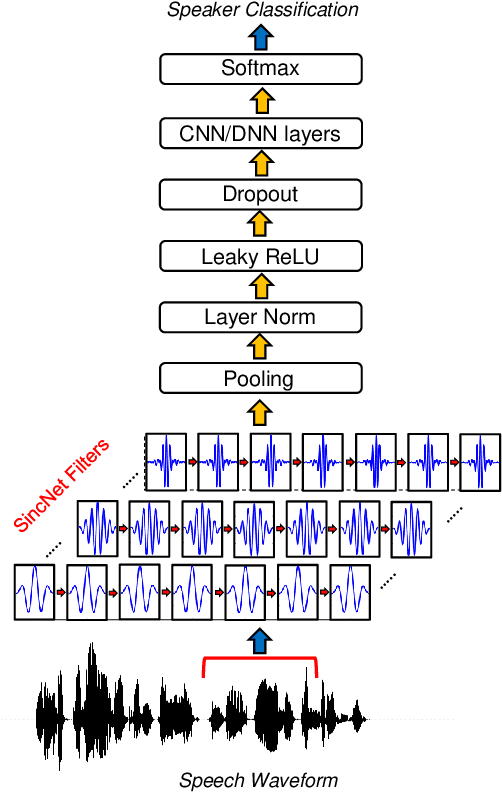
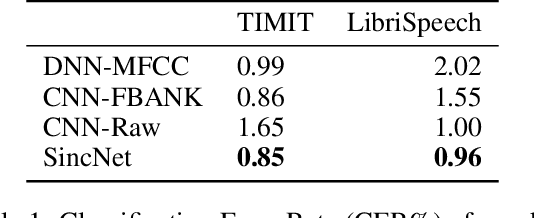
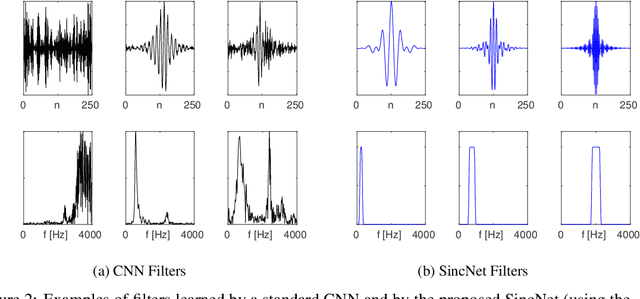
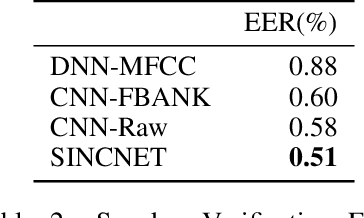
Deep learning is currently playing a crucial role toward higher levels of artificial intelligence. This paradigm allows neural networks to learn complex and abstract representations, that are progressively obtained by combining simpler ones. Nevertheless, the internal "black-box" representations automatically discovered by current neural architectures often suffer from a lack of interpretability, making of primary interest the study of explainable machine learning techniques. This paper summarizes our recent efforts to develop a more interpretable neural model for directly processing speech from the raw waveform. In particular, we propose SincNet, a novel Convolutional Neural Network (CNN) that encourages the first layer to discover more meaningful filters by exploiting parametrized sinc functions. In contrast to standard CNNs, which learn all the elements of each filter, only low and high cutoff frequencies of band-pass filters are directly learned from data. This inductive bias offers a very compact way to derive a customized filter-bank front-end, that only depends on some parameters with a clear physical meaning. Our experiments, conducted on both speaker and speech recognition, show that the proposed architecture converges faster, performs better, and is more interpretable than standard CNNs.
The PyTorch-Kaldi Speech Recognition Toolkit
Nov 19, 2018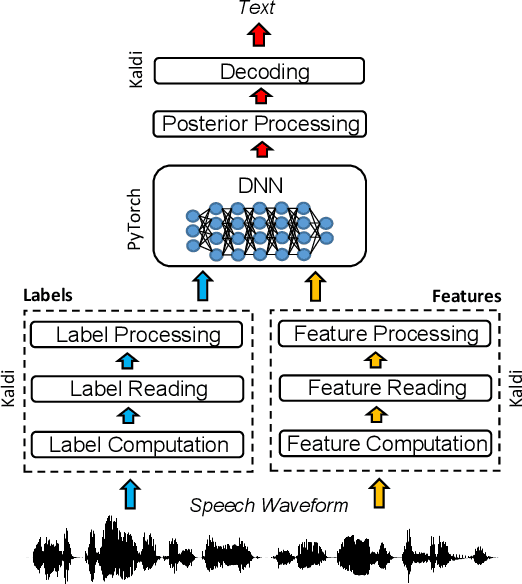
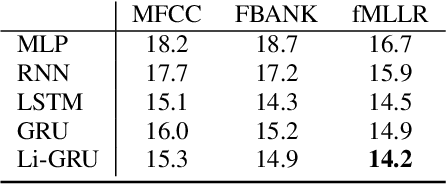

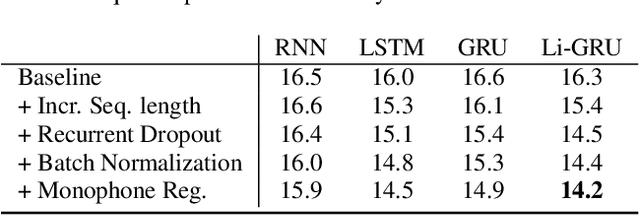
The availability of open-source software is playing a remarkable role in the popularization of speech recognition and deep learning. Kaldi, for instance, is nowadays an established framework used to develop state-of-the-art speech recognizers. PyTorch is used to build neural networks with the Python language and has recently spawn tremendous interest within the machine learning community thanks to its simplicity and flexibility. The PyTorch-Kaldi project aims to bridge the gap between these popular toolkits, trying to inherit the efficiency of Kaldi and the flexibility of PyTorch. PyTorch-Kaldi is not only a simple interface between these software, but it embeds several useful features for developing modern speech recognizers. For instance, the code is specifically designed to naturally plug-in user-defined acoustic models. As an alternative, users can exploit several pre-implemented neural networks that can be customized using intuitive configuration files. PyTorch-Kaldi supports multiple feature and label streams as well as combinations of neural networks, enabling the use of complex neural architectures. The toolkit is publicly-released along with a rich documentation and is designed to properly work locally or on HPC clusters. Experiments, that are conducted on several datasets and tasks, show that PyTorch-Kaldi can effectively be used to develop modern state-of-the-art speech recognizers.
On Training Recurrent Neural Networks for Lifelong Learning
Nov 16, 2018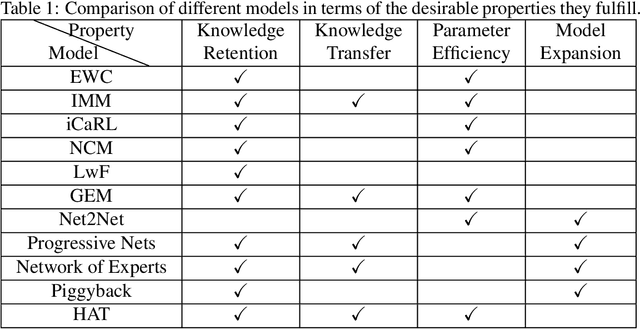
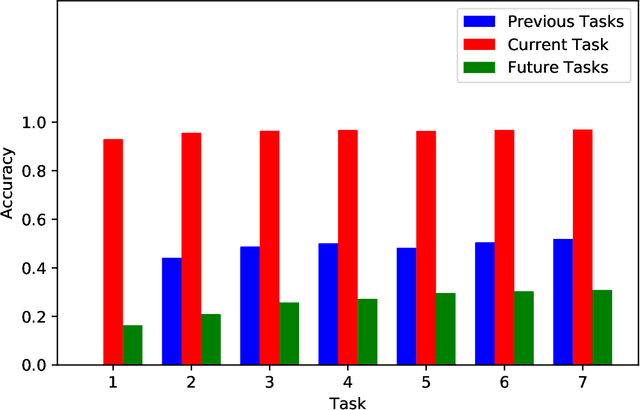

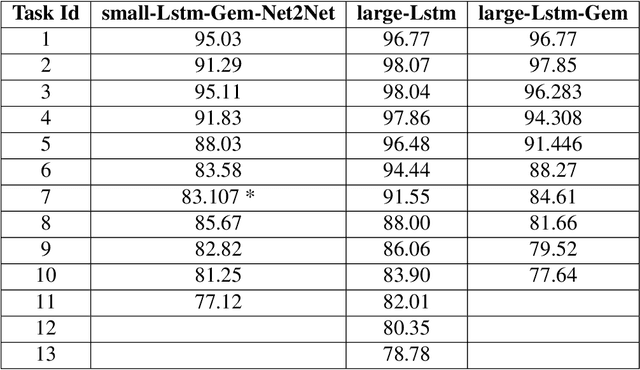
Capacity saturation and catastrophic forgetting are the central challenges of any parametric lifelong learning system. In this work, we study these challenges in the context of sequential supervised learning with emphasis on recurrent neural networks. To evaluate the models in life-long learning setting, we propose a curriculum-based, simple, and intuitive benchmark where the models are trained on a task with increasing levels of difficulty. As a step towards developing true lifelong learning systems, we unify Gradient Episodic Memory (a catastrophic forgetting alleviation approach) and Net2Net (a capacity expansion approach). Evaluation on the proposed benchmark shows that the unified model is more suitable than the constituent models for lifelong learning setting.
Machine Learning for Combinatorial Optimization: a Methodological Tour d'Horizon
Nov 15, 2018
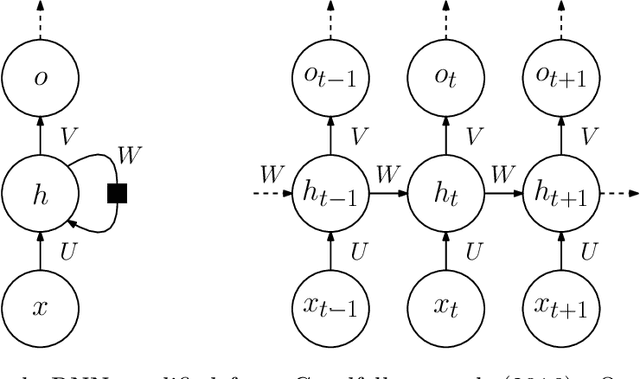
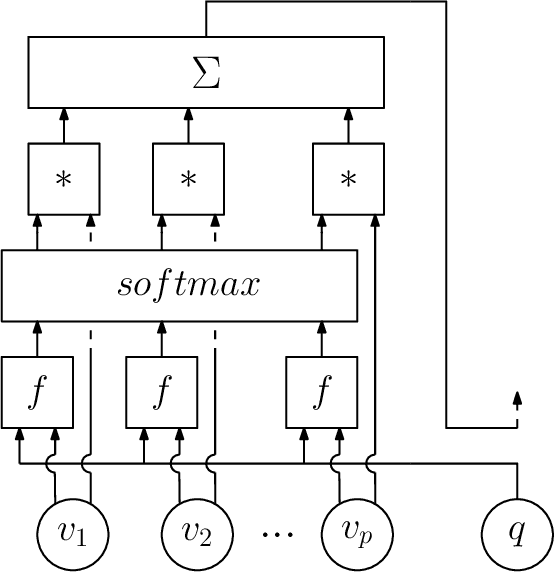
This paper surveys the recent attempts, both from the machine learning and operations research communities, at leveraging machine learning to solve combinatorial optimization problems. Given the hard nature of these problems, state-of-the-art methodologies involve algorithmic decisions that either require too much computing time or are not mathematically well defined. Thus, machine learning looks like a promising candidate to effectively deal with those decisions. We advocate for pushing further the integration of machine learning and combinatorial optimization and detail methodology to do so. A main point of the paper is seeing generic optimization problems as data points and inquiring what is the relevant distribution of problems to use for learning on a given task.
Image-to-image translation for cross-domain disentanglement
Nov 04, 2018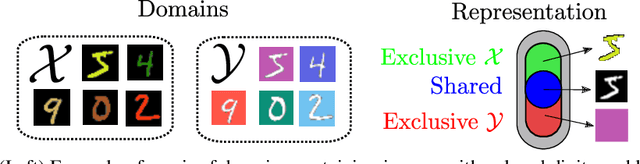
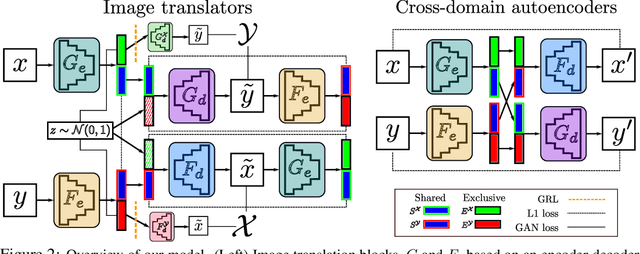
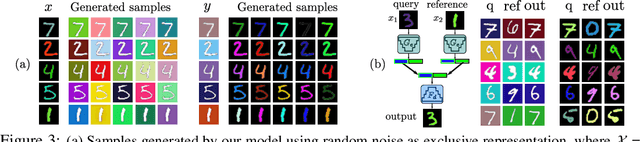

Deep image translation methods have recently shown excellent results, outputting high-quality images covering multiple modes of the data distribution. There has also been increased interest in disentangling the internal representations learned by deep methods to further improve their performance and achieve a finer control. In this paper, we bridge these two objectives and introduce the concept of cross-domain disentanglement. We aim to separate the internal representation into three parts. The shared part contains information for both domains. The exclusive parts, on the other hand, contain only factors of variation that are particular to each domain. We achieve this through bidirectional image translation based on Generative Adversarial Networks and cross-domain autoencoders, a novel network component. Our model offers multiple advantages. We can output diverse samples covering multiple modes of the distributions of both domains, perform domain-specific image transfer and interpolation, and cross-domain retrieval without the need of labeled data, only paired images. We compare our model to the state-of-the-art in multi-modal image translation and achieve better results for translation on challenging datasets as well as for cross-domain retrieval on realistic datasets.
Bayesian Model-Agnostic Meta-Learning
Oct 29, 2018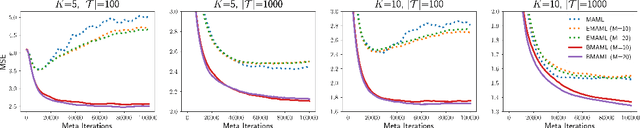
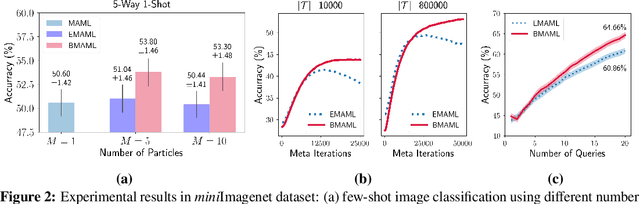
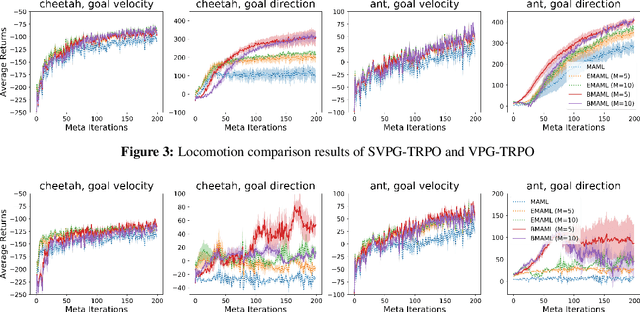
Learning to infer Bayesian posterior from a few-shot dataset is an important step towards robust meta-learning due to the model uncertainty inherent in the problem. In this paper, we propose a novel Bayesian model-agnostic meta-learning method. The proposed method combines scalable gradient-based meta-learning with nonparametric variational inference in a principled probabilistic framework. During fast adaptation, the method is capable of learning complex uncertainty structure beyond a point estimate or a simple Gaussian approximation. In addition, a robust Bayesian meta-update mechanism with a new meta-loss prevents overfitting during meta-update. Remaining an efficient gradient-based meta-learner, the method is also model-agnostic and simple to implement. Experiment results show the accuracy and robustness of the proposed method in various tasks: sinusoidal regression, image classification, active learning, and reinforcement learning.
BabyAI: First Steps Towards Grounded Language Learning With a Human In the Loop
Oct 27, 2018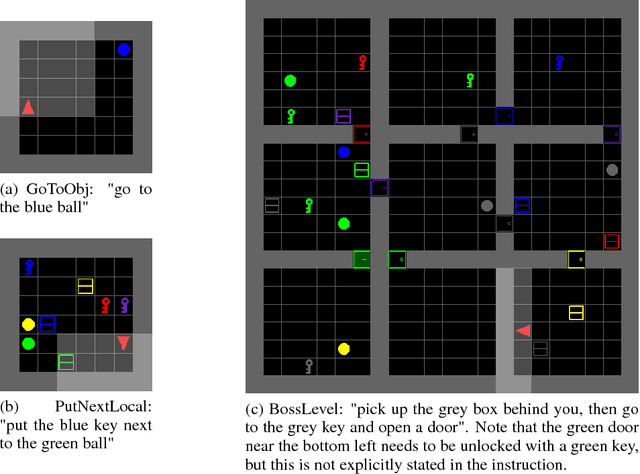
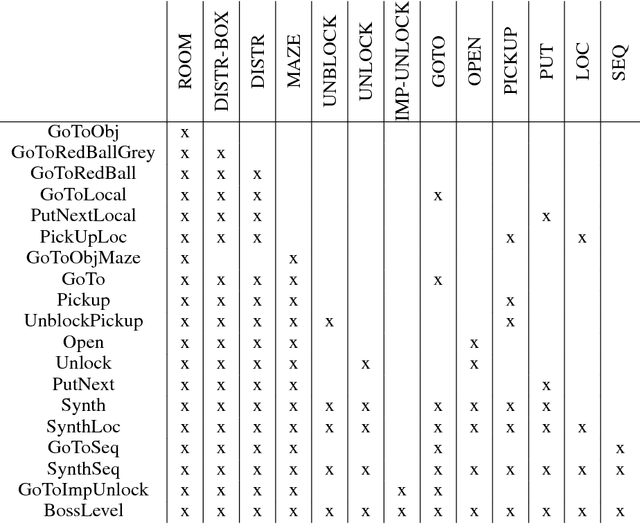
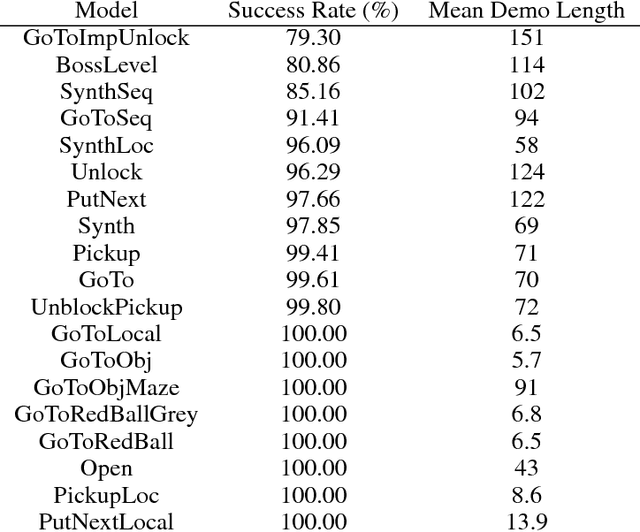

Allowing humans to interactively train artificial agents to understand language instructions is desirable for both practical and scientific reasons, but given the poor data efficiency of the current learning methods, this goal may require substantial research efforts. Here, we introduce the BabyAI research platform to support investigations towards including humans in the loop for grounded language learning. The BabyAI platform comprises an extensible suite of 19 levels of increasing difficulty. The levels gradually lead the agent towards acquiring a combinatorially rich synthetic language which is a proper subset of English. The platform also provides a heuristic expert agent for the purpose of simulating a human teacher. We report baseline results and estimate the amount of human involvement that would be required to train a neural network-based agent on some of the BabyAI levels. We put forward strong evidence that current deep learning methods are not yet sufficiently sample efficient when it comes to learning a language with compositional properties.
Dendritic cortical microcircuits approximate the backpropagation algorithm
Oct 26, 2018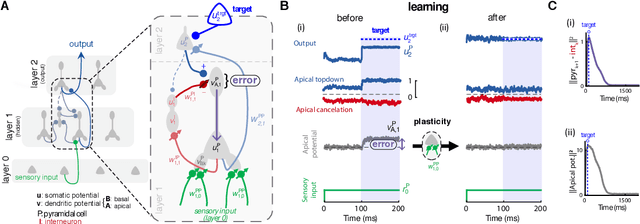
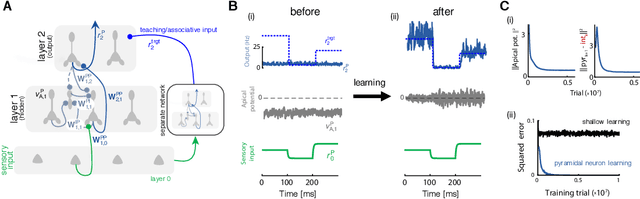
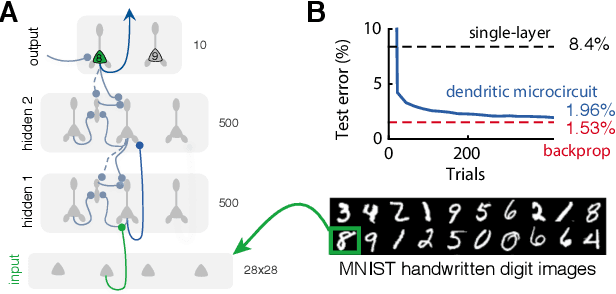
Deep learning has seen remarkable developments over the last years, many of them inspired by neuroscience. However, the main learning mechanism behind these advances - error backpropagation - appears to be at odds with neurobiology. Here, we introduce a multilayer neuronal network model with simplified dendritic compartments in which error-driven synaptic plasticity adapts the network towards a global desired output. In contrast to previous work our model does not require separate phases and synaptic learning is driven by local dendritic prediction errors continuously in time. Such errors originate at apical dendrites and occur due to a mismatch between predictive input from lateral interneurons and activity from actual top-down feedback. Through the use of simple dendritic compartments and different cell-types our model can represent both error and normal activity within a pyramidal neuron. We demonstrate the learning capabilities of the model in regression and classification tasks, and show analytically that it approximates the error backpropagation algorithm. Moreover, our framework is consistent with recent observations of learning between brain areas and the architecture of cortical microcircuits. Overall, we introduce a novel view of learning on dendritic cortical circuits and on how the brain may solve the long-standing synaptic credit assignment problem.
Depth with Nonlinearity Creates No Bad Local Minima in ResNets
Oct 21, 2018In this paper, we prove that depth with nonlinearity creates no bad local minima in a type of arbitrarily deep ResNets studied in previous work, in the sense that the values of all local minima are no worse than the global minima values of corresponding shallow linear predictors with arbitrary fixed features, and are guaranteed to further improve via residual representations. As a result, this paper provides an affirmative answer to an open question stated in a paper in the conference on Neural Information Processing Systems (NIPS) 2018. We note that even though our paper advances the theoretical foundation of deep learning and non-convex optimization, there is still a gap between theory and many practical deep learning applications.
On the Spectral Bias of Neural Networks
Oct 17, 2018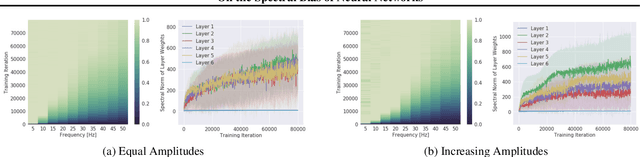
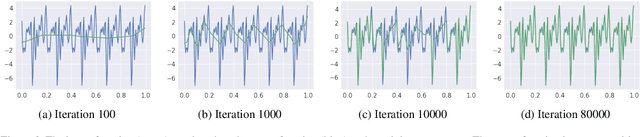
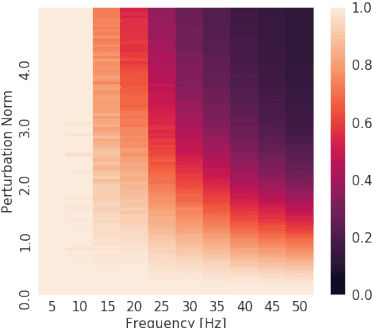
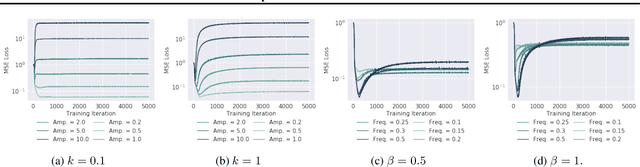
Neural networks are known to be a class of highly expressive functions able to fit even random input-output mappings with $100\%$ accuracy. In this work, we present properties of neural networks that complement this aspect of expressivity. By using tools from Fourier analysis, we show that deep ReLU networks are biased towards low frequency functions, meaning that they cannot have local fluctuations without affecting their global behavior. Intuitively, this property is in line with the observation that over-parameterized networks find simple patterns that generalize across data samples. We also investigate how the shape of the data manifold affects expressivity by showing evidence that learning high frequencies gets \emph{easier} with increasing manifold complexity, and present a theoretical understanding of this behavior. Finally, we study the robustness of the frequency components with respect to parameter perturbation, to develop the intuition that the parameters must be finely tuned to express high frequency functions.