 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeN-BEATS: Neural basis expansion analysis for interpretable time series forecasting
May 28, 2019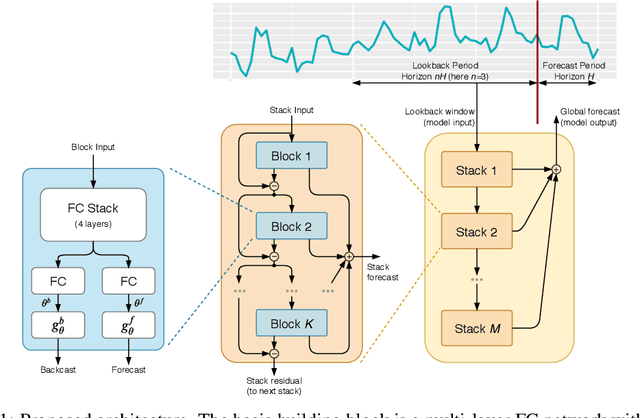
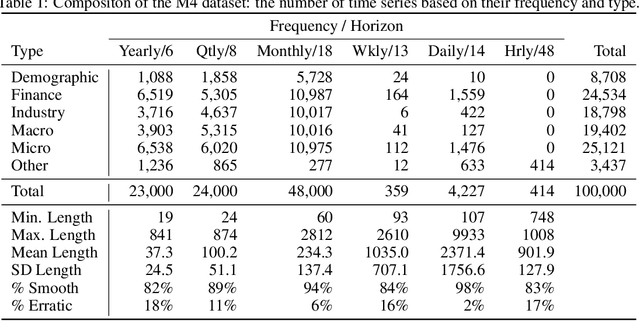
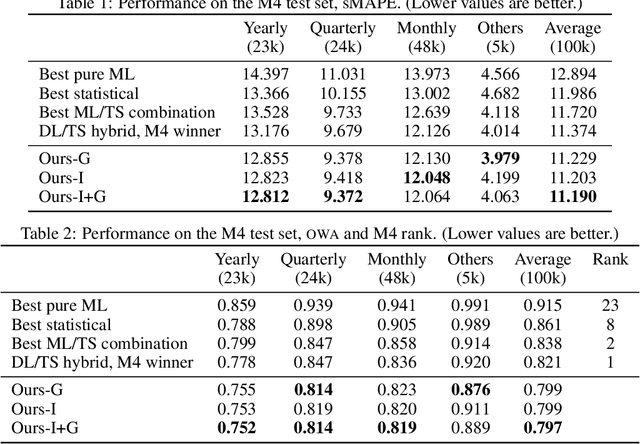
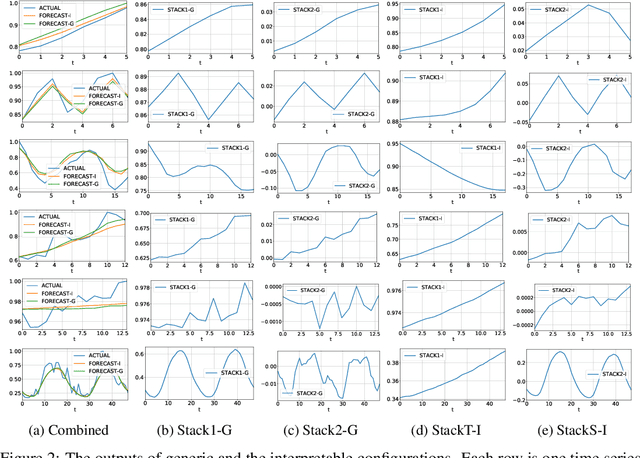
We focus on solving the univariate times series point forecasting problem using deep learning. We propose a deep neural architecture based on backward and forward residual links and a very deep stack of fully-connected layers. The architecture has a number of desirable properties, being interpretable, applicable without modification to a wide array of target domains, and fast to train. We test the proposed architecture on the well-known M4 competition dataset containing 100k time series from diverse domains. We demonstrate state-of-the-art performance for two configurations of N-BEATS, improving forecast accuracy by 11% over a statistical benchmark and by 3% over last year's winner of the M4 competition, a domain-adjusted hand-crafted hybrid between neural network and statistical time series models. The first configuration of our model does not employ any time-series-specific components and its performance on the M4 dataset strongly suggests that, contrarily to received wisdom, deep learning primitives such as residual blocks are by themselves sufficient to solve a wide range of forecasting problems. Finally, we demonstrate how the proposed architecture can be augmented to provide outputs that are interpretable without loss in accuracy.
State-Reification Networks: Improving Generalization by Modeling the Distribution of Hidden Representations
May 26, 2019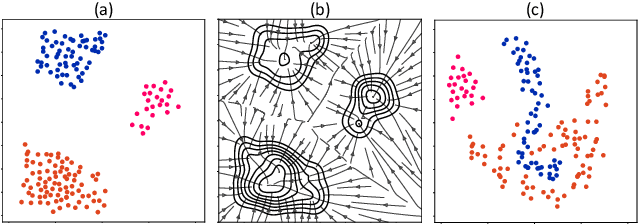
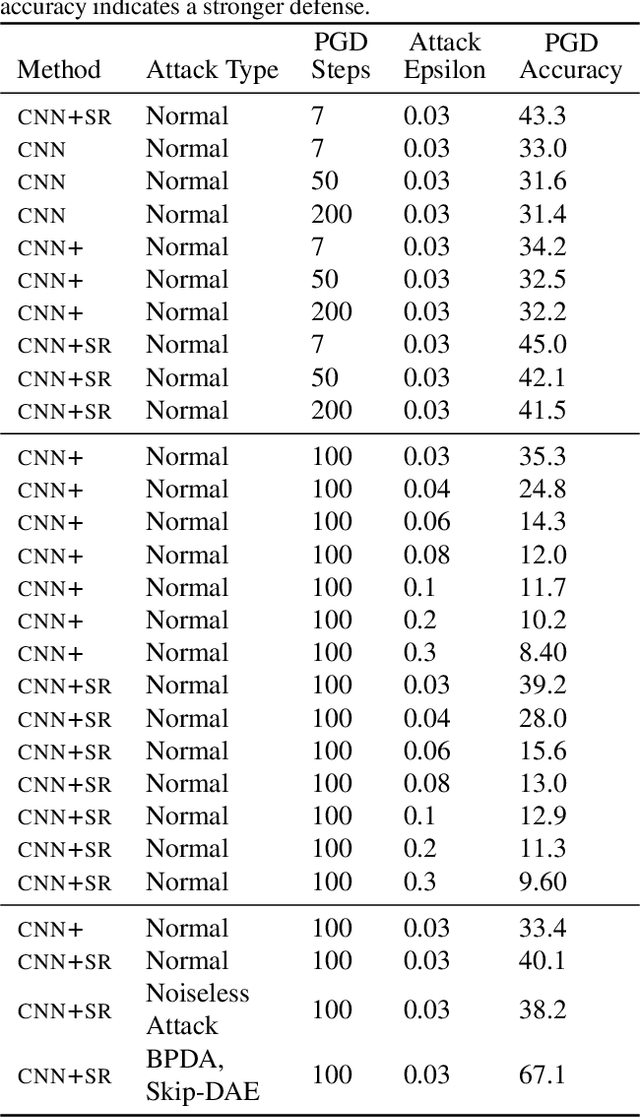
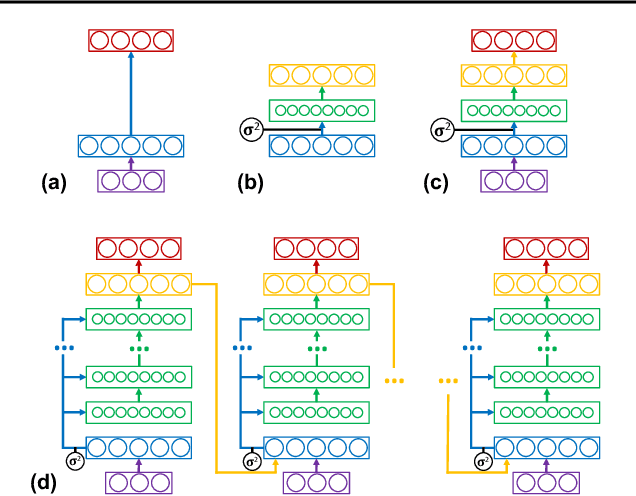
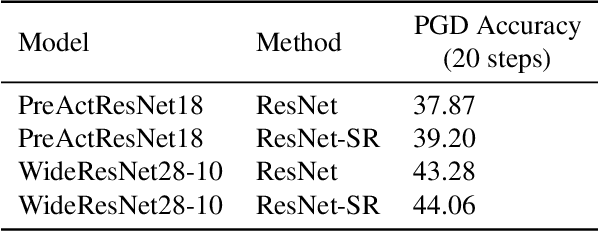
Machine learning promises methods that generalize well from finite labeled data. However, the brittleness of existing neural net approaches is revealed by notable failures, such as the existence of adversarial examples that are misclassified despite being nearly identical to a training example, or the inability of recurrent sequence-processing nets to stay on track without teacher forcing. We introduce a method, which we refer to as \emph{state reification}, that involves modeling the distribution of hidden states over the training data and then projecting hidden states observed during testing toward this distribution. Our intuition is that if the network can remain in a familiar manifold of hidden space, subsequent layers of the net should be well trained to respond appropriately. We show that this state-reification method helps neural nets to generalize better, especially when labeled data are sparse, and also helps overcome the challenge of achieving robust generalization with adversarial training.
Compositional generalization in a deep seq2seq model by separating syntax and semantics
May 23, 2019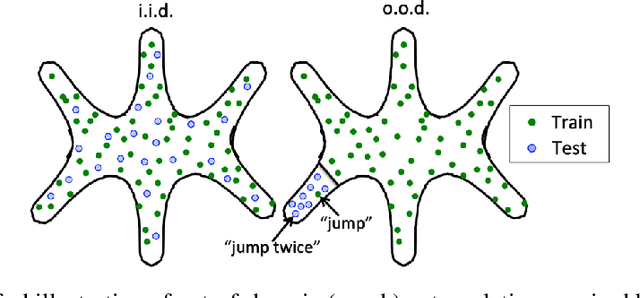
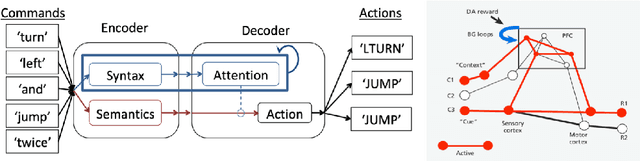

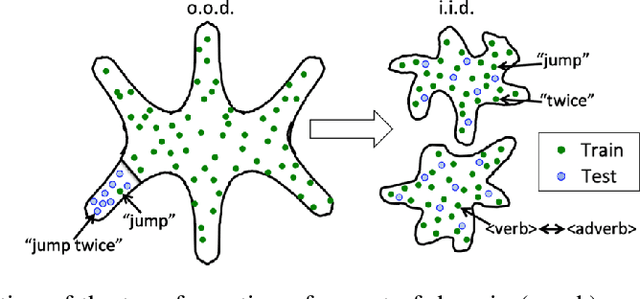
Standard methods in deep learning for natural language processing fail to capture the compositional structure of human language that allows for systematic generalization outside of the training distribution. However, human learners readily generalize in this way, e.g. by applying known grammatical rules to novel words. Inspired by work in neuroscience suggesting separate brain systems for syntactic and semantic processing, we implement a modification to standard approaches in neural machine translation, imposing an analogous separation. The novel model, which we call Syntactic Attention, substantially outperforms standard methods in deep learning on the SCAN dataset, a compositional generalization task, without any hand-engineered features or additional supervision. Our work suggests that separating syntactic from semantic learning may be a useful heuristic for capturing compositional structure.
The Journey is the Reward: Unsupervised Learning of Influential Trajectories
May 22, 2019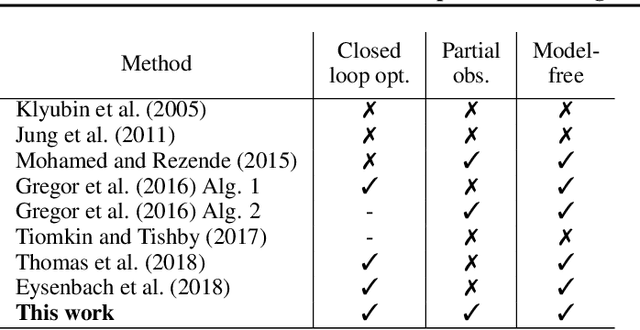
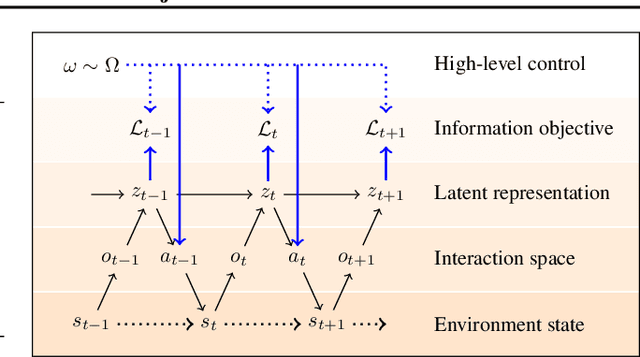
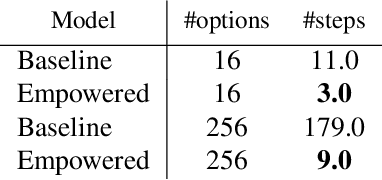
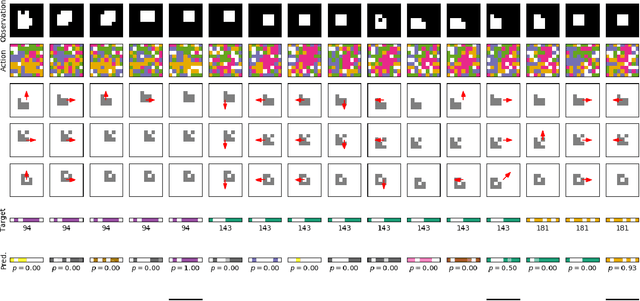
Unsupervised exploration and representation learning become increasingly important when learning in diverse and sparse environments. The information-theoretic principle of empowerment formalizes an unsupervised exploration objective through an agent trying to maximize its influence on the future states of its environment. Previous approaches carry certain limitations in that they either do not employ closed-loop feedback or do not have an internal state. As a consequence, a privileged final state is taken as an influence measure, rather than the full trajectory. We provide a model-free method which takes into account the whole trajectory while still offering the benefits of option-based approaches. We successfully apply our approach to settings with large action spaces, where discovery of meaningful action sequences is particularly difficult.
GMNN: Graph Markov Neural Networks
May 15, 2019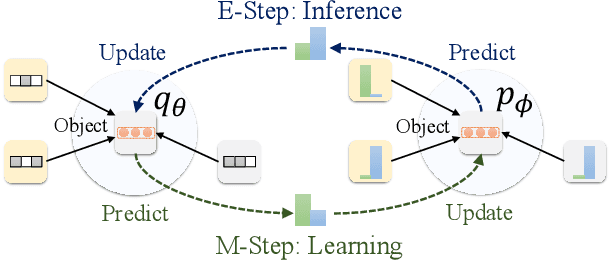

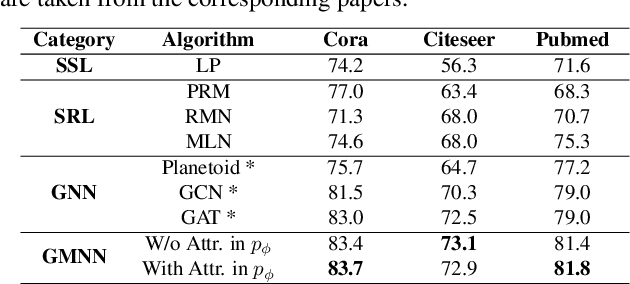
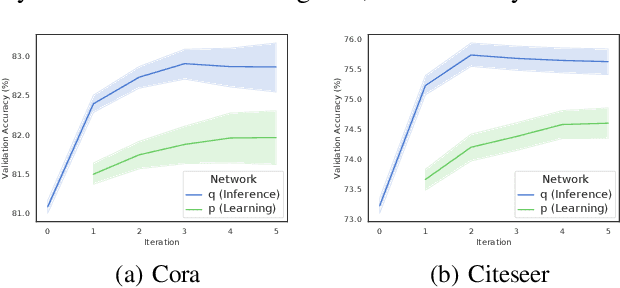
This paper studies semi-supervised object classification in relational data, which is a fundamental problem in relational data modeling. The problem has been extensively studied in the literature of both statistical relational learning (e.g. relational Markov networks) and graph neural networks (e.g. graph convolutional networks). Statistical relational learning methods can effectively model the dependency of object labels through conditional random fields for collective classification, whereas graph neural networks learn effective object representations for classification through end-to-end training. In this paper, we propose the Graph Markov Neural Network (GMNN) that combines the advantages of both worlds. A GMNN models the joint distribution of object labels with a conditional random field, which can be effectively trained with the variational EM algorithm. In the E-step, one graph neural network learns effective object representations for approximating the posterior distributions of object labels. In the M-step, another graph neural network is used to model the local label dependency. Experiments on object classification, link classification, and unsupervised node representation learning show that GMNN achieves state-of-the-art results.
Visualizing the Consequences of Climate Change Using Cycle-Consistent Adversarial Networks
May 02, 2019
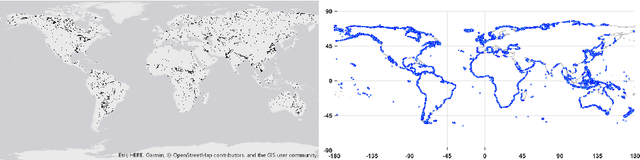
We present a project that aims to generate images that depict accurate, vivid, and personalized outcomes of climate change using Cycle-Consistent Adversarial Networks (CycleGANs). By training our CycleGAN model on street-view images of houses before and after extreme weather events (e.g. floods, forest fires, etc.), we learn a mapping that can then be applied to images of locations that have not yet experienced these events. This visual transformation is paired with climate model predictions to assess likelihood and type of climate-related events in the long term (50 years) in order to bring the future closer in the viewers mind. The eventual goal of our project is to enable individuals to make more informed choices about their climate future by creating a more visceral understanding of the effects of climate change, while maintaining scientific credibility by drawing on climate model projections.
GradMask: Reduce Overfitting by Regularizing Saliency
Apr 16, 2019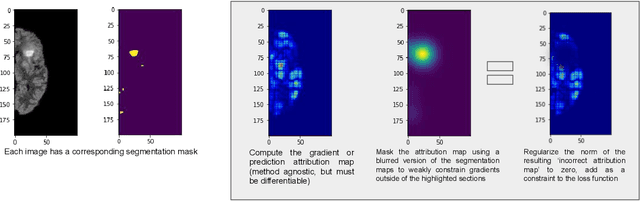
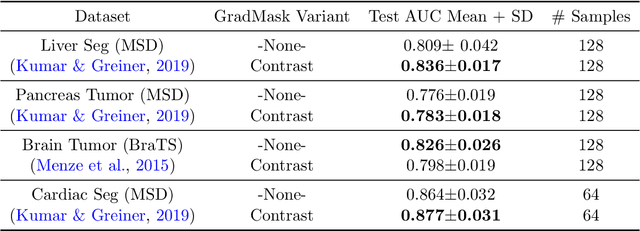
With too few samples or too many model parameters, overfitting can inhibit the ability to generalise predictions to new data. Within medical imaging, this can occur when features are incorrectly assigned importance such as distinct hospital specific artifacts, leading to poor performance on a new dataset from a different institution without those features, which is undesirable. Most regularization methods do not explicitly penalize the incorrect association of these features to the target class and hence fail to address this issue. We propose a regularization method, GradMask, which penalizes saliency maps inferred from the classifier gradients when they are not consistent with the lesion segmentation. This prevents non-tumor related features to contribute to the classification of unhealthy samples. We demonstrate that this method can improve test accuracy between 1-3% compared to the baseline without GradMask, showing that it has an impact on reducing overfitting.
Speech Model Pre-training for End-to-End Spoken Language Understanding
Apr 07, 2019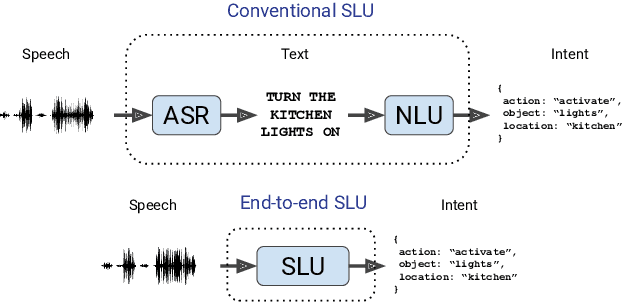
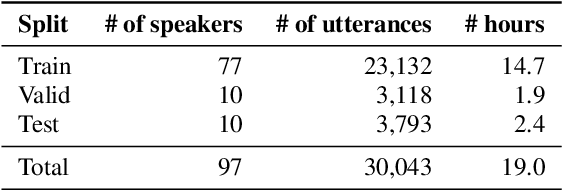
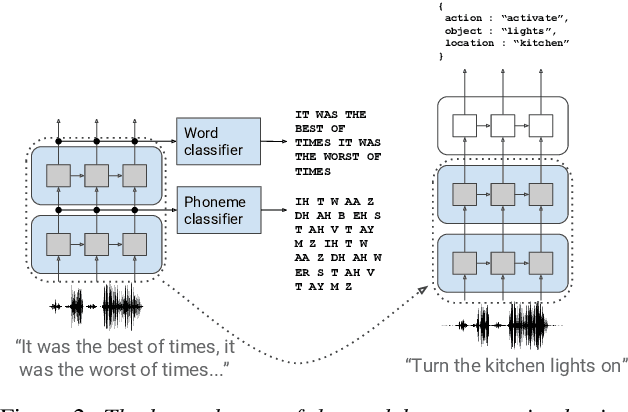
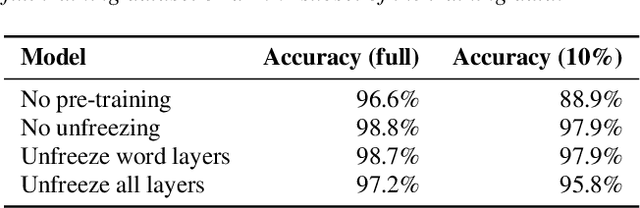
Whereas conventional spoken language understanding (SLU) systems map speech to text, and then text to intent, end-to-end SLU systems map speech directly to intent through a single trainable model. Achieving high accuracy with these end-to-end models without a large amount of training data is difficult. We propose a method to reduce the data requirements of end-to-end SLU in which the model is first pre-trained to predict words and phonemes, thus learning good features for SLU. We introduce a new SLU dataset, Fluent Speech Commands, and show that our method improves performance both when the full dataset is used for training and when only a small subset is used. We also describe preliminary experiments to gauge the model's ability to generalize to new phrases not heard during training.
Reinforced Imitation in Heterogeneous Action Space
Apr 06, 2019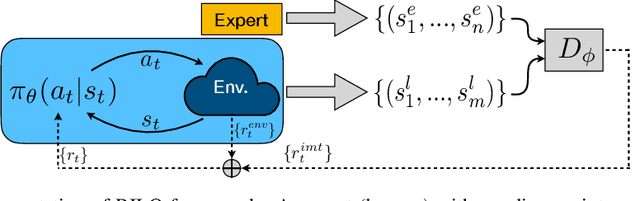

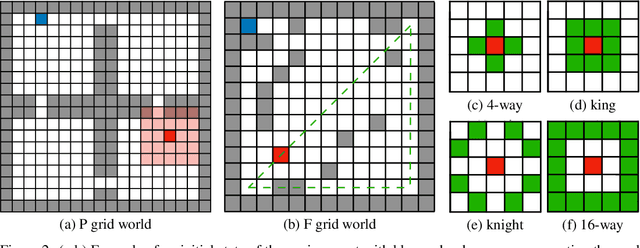
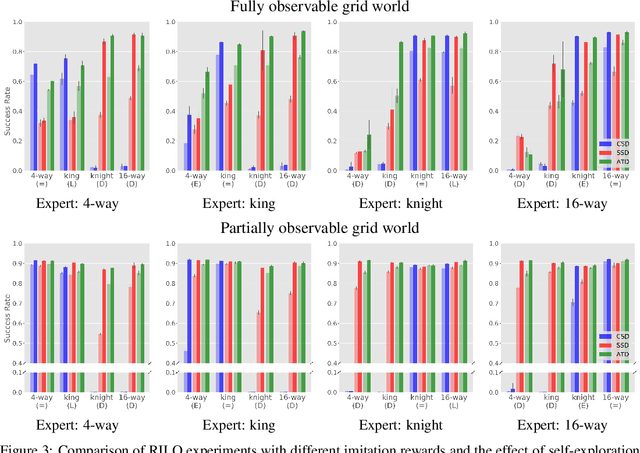
Imitation learning is an effective alternative approach to learn a policy when the reward function is sparse. In this paper, we consider a challenging setting where an agent and an expert use different actions from each other. We assume that the agent has access to a sparse reward function and state-only expert observations. We propose a method which gradually balances between the imitation learning cost and the reinforcement learning objective. In addition, this method adapts the agent's policy based on either mimicking expert behavior or maximizing sparse reward. We show, through navigation scenarios, that (i) an agent is able to efficiently leverage sparse rewards to outperform standard state-only imitation learning, (ii) it can learn a policy even when its actions are different from the expert, and (iii) the performance of the agent is not bounded by that of the expert, due to the optimized usage of sparse rewards.
Learning Problem-agnostic Speech Representations from Multiple Self-supervised Tasks
Apr 06, 2019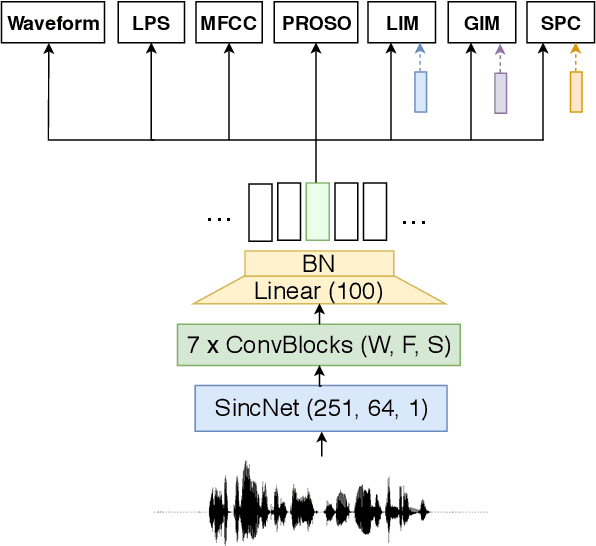
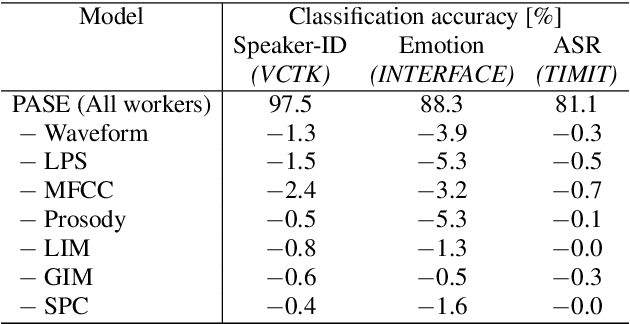
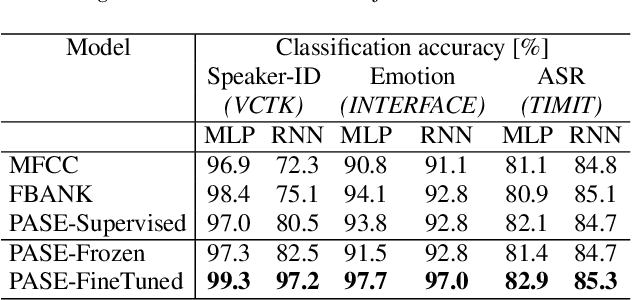
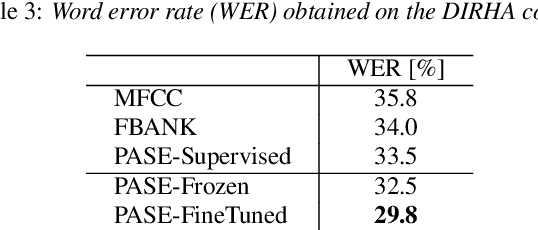
Learning good representations without supervision is still an open issue in machine learning, and is particularly challenging for speech signals, which are often characterized by long sequences with a complex hierarchical structure. Some recent works, however, have shown that it is possible to derive useful speech representations by employing a self-supervised encoder-discriminator approach. This paper proposes an improved self-supervised method, where a single neural encoder is followed by multiple workers that jointly solve different self-supervised tasks. The needed consensus across different tasks naturally imposes meaningful constraints to the encoder, contributing to discover general representations and to minimize the risk of learning superficial ones. Experiments show that the proposed approach can learn transferable, robust, and problem-agnostic features that carry on relevant information from the speech signal, such as speaker identity, phonemes, and even higher-level features such as emotional cues. In addition, a number of design choices make the encoder easily exportable, facilitating its direct usage or adaptation to different problems.