 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Defenses via Vector Quantization
May 23, 2023Building upon Randomized Discretization, we develop two novel adversarial defenses against white-box PGD attacks, utilizing vector quantization in higher dimensional spaces. These methods, termed pRD and swRD, not only offer a theoretical guarantee in terms of certified accuracy, they are also shown, via abundant experiments, to perform comparably or even superior to the current art of adversarial defenses. These methods can be extended to a version that allows further training of the target classifier and demonstrates further improved performance.
AdversarialWord Dilution as Text Data Augmentation in Low-Resource Regime
May 16, 2023



Data augmentation is widely used in text classification, especially in the low-resource regime where a few examples for each class are available during training. Despite the success, generating data augmentations as hard positive examples that may increase their effectiveness is under-explored. This paper proposes an Adversarial Word Dilution (AWD) method that can generate hard positive examples as text data augmentations to train the low-resource text classification model efficiently. Our idea of augmenting the text data is to dilute the embedding of strong positive words by weighted mixing with unknown-word embedding, making the augmented inputs hard to be recognized as positive by the classification model. We adversarially learn the dilution weights through a constrained min-max optimization process with the guidance of the labels. Empirical studies on three benchmark datasets show that AWD can generate more effective data augmentations and outperform the state-of-the-art text data augmentation methods. The additional analysis demonstrates that the data augmentations generated by AWD are interpretable and can flexibly extend to new examples without further training.
ContrastNet: A Contrastive Learning Framework for Few-Shot Text Classification
May 16, 2023



Few-shot text classification has recently been promoted by the meta-learning paradigm which aims to identify target classes with knowledge transferred from source classes with sets of small tasks named episodes. Despite their success, existing works building their meta-learner based on Prototypical Networks are unsatisfactory in learning discriminative text representations between similar classes, which may lead to contradictions during label prediction. In addition, the tasklevel and instance-level overfitting problems in few-shot text classification caused by a few training examples are not sufficiently tackled. In this work, we propose a contrastive learning framework named ContrastNet to tackle both discriminative representation and overfitting problems in few-shot text classification. ContrastNet learns to pull closer text representations belonging to the same class and push away text representations belonging to different classes, while simultaneously introducing unsupervised contrastive regularization at both task-level and instance-level to prevent overfitting. Experiments on 8 few-shot text classification datasets show that ContrastNet outperforms the current state-of-the-art models.
Over-training with Mixup May Hurt Generalization
Mar 02, 2023Mixup, which creates synthetic training instances by linearly interpolating random sample pairs, is a simple and yet effective regularization technique to boost the performance of deep models trained with SGD. In this work, we report a previously unobserved phenomenon in Mixup training: on a number of standard datasets, the performance of Mixup-trained models starts to decay after training for a large number of epochs, giving rise to a U-shaped generalization curve. This behavior is further aggravated when the size of original dataset is reduced. To help understand such a behavior of Mixup, we show theoretically that Mixup training may introduce undesired data-dependent label noises to the synthesized data. Via analyzing a least-square regression problem with a random feature model, we explain why noisy labels may cause the U-shaped curve to occur: Mixup improves generalization through fitting the clean patterns at the early training stage, but as training progresses, Mixup becomes over-fitting to the noise in the synthetic data. Extensive experiments are performed on a variety of benchmark datasets, validating this explanation.
Self-training through Classifier Disagreement for Cross-Domain Opinion Target Extraction
Feb 28, 2023Opinion target extraction (OTE) or aspect extraction (AE) is a fundamental task in opinion mining that aims to extract the targets (or aspects) on which opinions have been expressed. Recent work focus on cross-domain OTE, which is typically encountered in real-world scenarios, where the testing and training distributions differ. Most methods use domain adversarial neural networks that aim to reduce the domain gap between the labelled source and unlabelled target domains to improve target domain performance. However, this approach only aligns feature distributions and does not account for class-wise feature alignment, leading to suboptimal results. Semi-supervised learning (SSL) has been explored as a solution, but is limited by the quality of pseudo-labels generated by the model. Inspired by the theoretical foundations in domain adaptation [2], we propose a new SSL approach that opts for selecting target samples whose model output from a domain-specific teacher and student network disagree on the unlabelled target data, in an effort to boost the target domain performance. Extensive experiments on benchmark cross-domain OTE datasets show that this approach is effective and performs consistently well in settings with large domain shifts.
Tighter Information-Theoretic Generalization Bounds from Supersamples
Feb 05, 2023We present a variety of novel information-theoretic generalization bounds for learning algorithms, from the supersample setting of Steinke & Zakynthinou (2020)-the setting of the "conditional mutual information" framework. Our development exploits projecting the loss pair (obtained from a training instance and a testing instance) down to a single number and correlating loss values with a Rademacher sequence (and its shifted variants). The presented bounds include square-root bounds, fast-rate bounds, including those based on variance and sharpness, and bounds for interpolating algorithms etc. We show theoretically or empirically that these bounds are tighter than all information-theoretic bounds known to date on the same supersample setting.
Two Facets of SDE Under an Information-Theoretic Lens: Generalization of SGD via Training Trajectories and via Terminal States
Nov 19, 2022Stochastic differential equations (SDEs) have been shown recently to well characterize the dynamics of training machine learning models with SGD. This provides two opportunities for better understanding the generalization behaviour of SGD through its SDE approximation. First, under the SDE characterization, SGD may be regarded as the full-batch gradient descent with Gaussian gradient noise. This allows the application of the generalization bounds developed by Xu & Raginsky (2017) to analyzing the generalization behaviour of SGD, resulting in upper bounds in terms of the mutual information between the training set and the training trajectory. Second, under mild assumptions, it is possible to obtain an estimate of the steady-state weight distribution of SDE. Using this estimate, we apply the PAC-Bayes-like information-theoretic bounds developed in both Xu & Raginsky (2017) and Negrea et al. (2019) to obtain generalization upper bounds in terms of the KL divergence between the steady-state weight distribution of SGD with respect to a prior distribution. Among various options, one may choose the prior as the steady-state weight distribution obtained by SGD on the same training set but with one example held out. In this case, the bound can be elegantly expressed using the influence function (Koh & Liang, 2017), which suggests that the generalization of the SGD is related to the stability of SGD. Various insights are presented along the development of these bounds, which are subsequently validated numerically.
Information-Theoretic Analysis of Unsupervised Domain Adaptation
Oct 03, 2022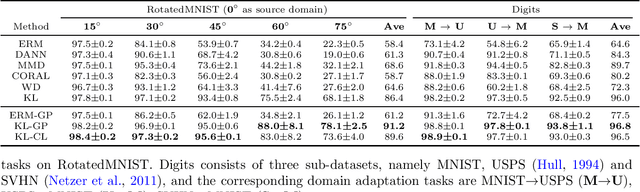

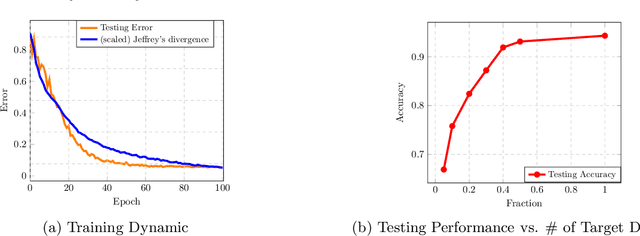
This paper uses information-theoretic tools to analyze the generalization error in unsupervised domain adaptation (UDA). We present novel upper bounds for two notions of generalization errors. The first notion measures the gap between the population risk in the target domain and that in the source domain, and the second measures the gap between the population risk in the target domain and the empirical risk in the source domain. While our bounds for the first kind of error are in line with the traditional analysis and give similar insights, our bounds on the second kind of error are algorithm-dependent, which also provide insights into algorithm designs. Specifically, we present two simple techniques for improving generalization in UDA and validate them experimentally.
Cross Domain Few-Shot Learning via Meta Adversarial Training
Mar 01, 2022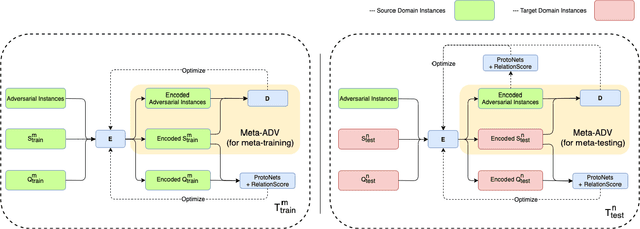
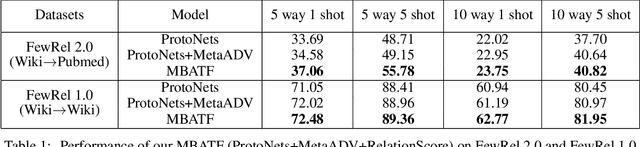
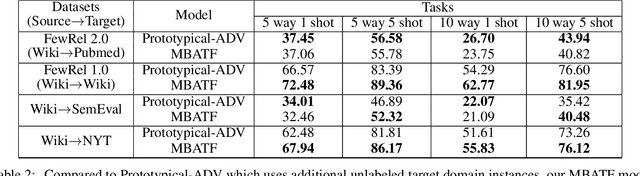
Few-shot relation classification (RC) is one of the critical problems in machine learning. Current research merely focuses on the set-ups that both training and testing are from the same domain. However, in practice, this assumption is not always guaranteed. In this study, we present a novel model that takes into consideration the afore-mentioned cross-domain situation. Not like previous models, we only use the source domain data to train the prototypical networks and test the model on target domain data. A meta-based adversarial training framework (MBATF) is proposed to fine-tune the trained networks for adapting to data from the target domain. Empirical studies confirm the effectiveness of the proposed model.
Dual Contrastive Learning: Text Classification via Label-Aware Data Augmentation
Jan 21, 2022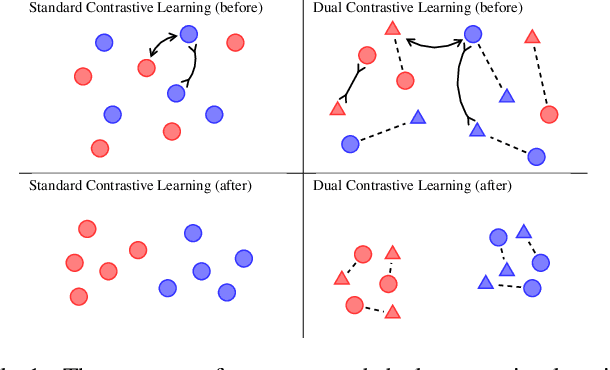
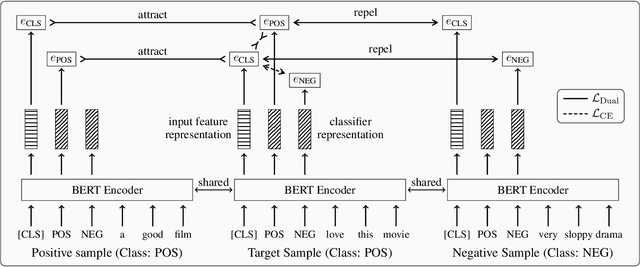
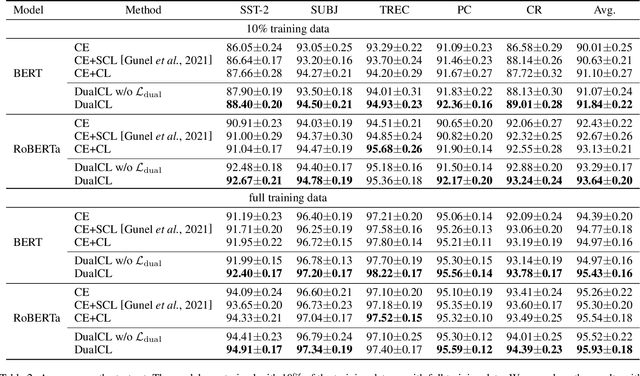
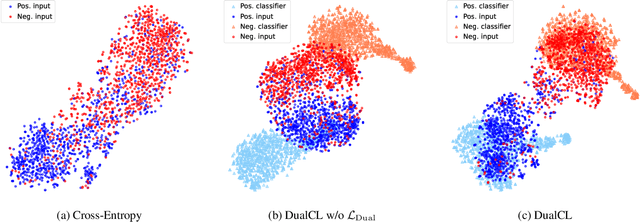
Contrastive learning has achieved remarkable success in representation learning via self-supervision in unsupervised settings. However, effectively adapting contrastive learning to supervised learning tasks remains as a challenge in practice. In this work, we introduce a dual contrastive learning (DualCL) framework that simultaneously learns the features of input samples and the parameters of classifiers in the same space. Specifically, DualCL regards the parameters of the classifiers as augmented samples associating to different labels and then exploits the contrastive learning between the input samples and the augmented samples. Empirical studies on five benchmark text classification datasets and their low-resource version demonstrate the improvement in classification accuracy and confirm the capability of learning discriminative representations of DualCL.