 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Multi-task Representation Learning: A Tensor Factorisation Approach
Feb 16, 2017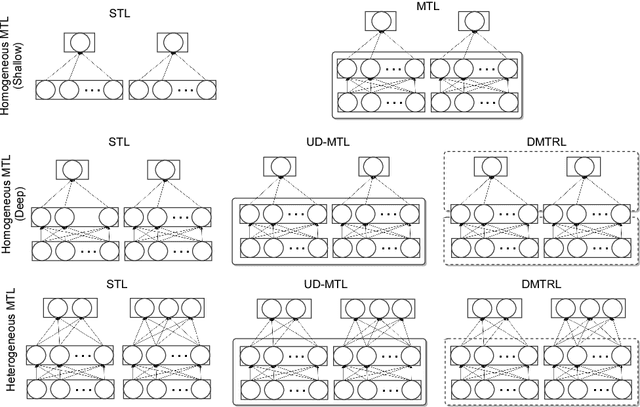
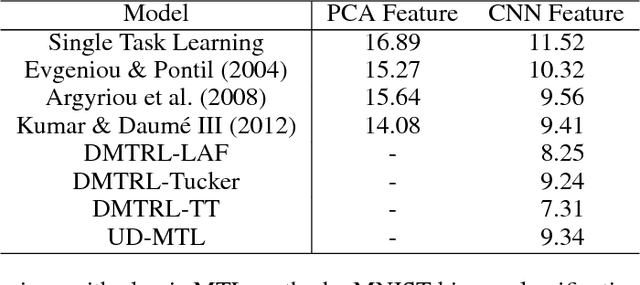
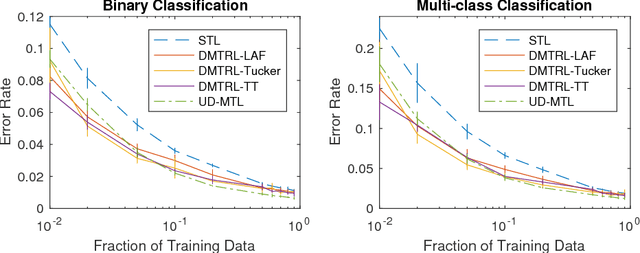
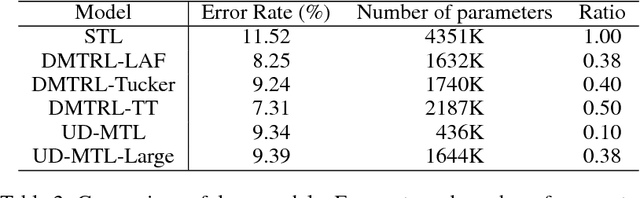
Most contemporary multi-task learning methods assume linear models. This setting is considered shallow in the era of deep learning. In this paper, we present a new deep multi-task representation learning framework that learns cross-task sharing structure at every layer in a deep network. Our approach is based on generalising the matrix factorisation techniques explicitly or implicitly used by many conventional MTL algorithms to tensor factorisation, to realise automatic learning of end-to-end knowledge sharing in deep networks. This is in contrast to existing deep learning approaches that need a user-defined multi-task sharing strategy. Our approach applies to both homogeneous and heterogeneous MTL. Experiments demonstrate the efficacy of our deep multi-task representation learning in terms of both higher accuracy and fewer design choices.
Unifying Multi-Domain Multi-Task Learning: Tensor and Neural Network Perspectives
Nov 28, 2016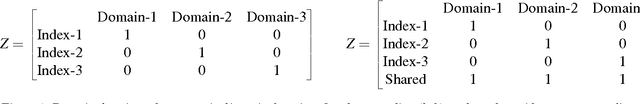
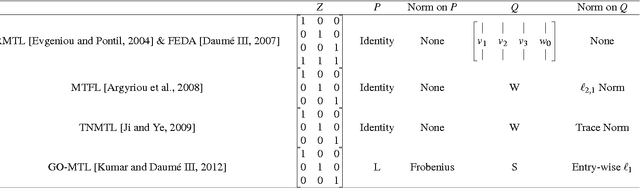
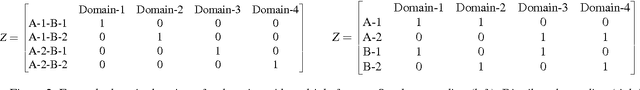
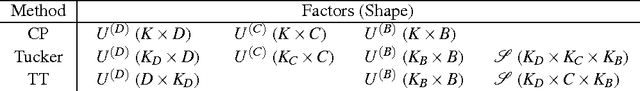
Multi-domain learning aims to benefit from simultaneously learning across several different but related domains. In this chapter, we propose a single framework that unifies multi-domain learning (MDL) and the related but better studied area of multi-task learning (MTL). By exploiting the concept of a \emph{semantic descriptor} we show how our framework encompasses various classic and recent MDL/MTL algorithms as special cases with different semantic descriptor encodings. As a second contribution, we present a higher order generalisation of this framework, capable of simultaneous multi-task-multi-domain learning. This generalisation has two mathematically equivalent views in multi-linear algebra and gated neural networks respectively. Moreover, by exploiting the semantic descriptor, it provides neural networks the capability of zero-shot learning (ZSL), where a classifier is generated for an unseen class without any training data; as well as zero-shot domain adaptation (ZSDA), where a model is generated for an unseen domain without any training data. In practice, this framework provides a powerful yet easy to implement method that can be flexibly applied to MTL, MDL, ZSL and ZSDA.
Gated Neural Networks for Option Pricing: Rationality by Design
Nov 19, 2016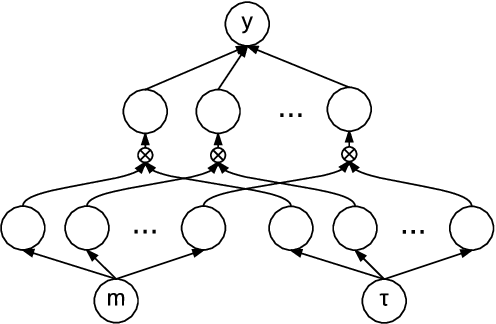


We propose a neural network approach to price EU call options that significantly outperforms some existing pricing models and comes with guarantees that its predictions are economically reasonable. To achieve this, we introduce a class of gated neural networks that automatically learn to divide-and-conquer the problem space for robust and accurate pricing. We then derive instantiations of these networks that are 'rational by design' in terms of naturally encoding a valid call option surface that enforces no arbitrage principles. This integration of human insight within data-driven learning provides significantly better generalisation in pricing performance due to the encoded inductive bias in the learning, guarantees sanity in the model's predictions, and provides econometrically useful byproduct such as risk neutral density.
Zero-Shot Domain Adaptation via Kernel Regression on the Grassmannian
Jul 29, 2015


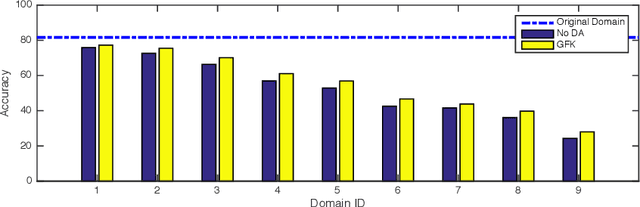
Most visual recognition methods implicitly assume the data distribution remains unchanged from training to testing. However, in practice domain shift often exists, where real-world factors such as lighting and sensor type change between train and test, and classifiers do not generalise from source to target domains. It is impractical to train separate models for all possible situations because collecting and labelling the data is expensive. Domain adaptation algorithms aim to ameliorate domain shift, allowing a model trained on a source to perform well on a different target domain. However, even for the setting of unsupervised domain adaptation, where the target domain is unlabelled, collecting data for every possible target domain is still costly. In this paper, we propose a new domain adaptation method that has no need to access either data or labels of the target domain when it can be described by a parametrised vector and there exits several related source domains within the same parametric space. It greatly reduces the burden of data collection and annotation, and our experiments show some promising results.
Sketch-a-Net that Beats Humans
Jul 21, 2015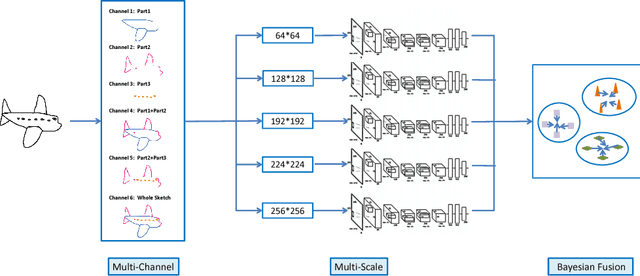


We propose a multi-scale multi-channel deep neural network framework that, for the first time, yields sketch recognition performance surpassing that of humans. Our superior performance is a result of explicitly embedding the unique characteristics of sketches in our model: (i) a network architecture designed for sketch rather than natural photo statistics, (ii) a multi-channel generalisation that encodes sequential ordering in the sketching process, and (iii) a multi-scale network ensemble with joint Bayesian fusion that accounts for the different levels of abstraction exhibited in free-hand sketches. We show that state-of-the-art deep networks specifically engineered for photos of natural objects fail to perform well on sketch recognition, regardless whether they are trained using photo or sketch. Our network on the other hand not only delivers the best performance on the largest human sketch dataset to date, but also is small in size making efficient training possible using just CPUs.
When Face Recognition Meets with Deep Learning: an Evaluation of Convolutional Neural Networks for Face Recognition
Apr 09, 2015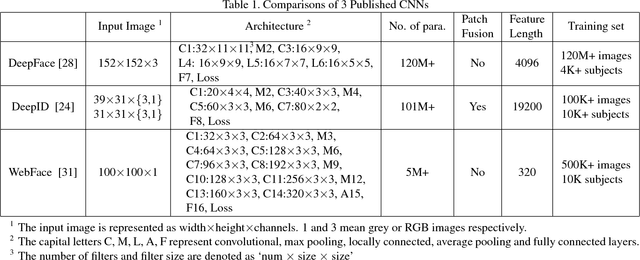


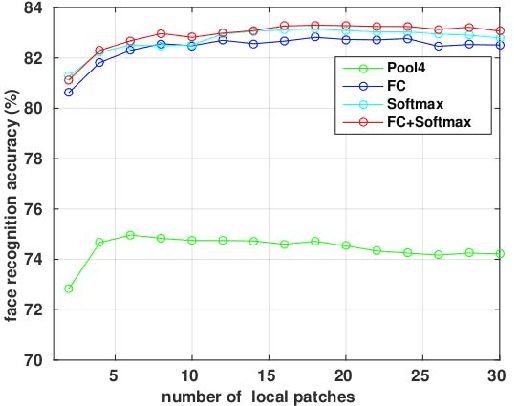
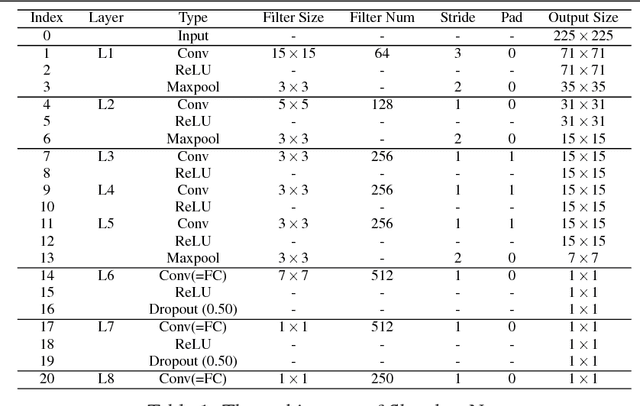
Deep learning, in particular Convolutional Neural Network (CNN), has achieved promising results in face recognition recently. However, it remains an open question: why CNNs work well and how to design a 'good' architecture. The existing works tend to focus on reporting CNN architectures that work well for face recognition rather than investigate the reason. In this work, we conduct an extensive evaluation of CNN-based face recognition systems (CNN-FRS) on a common ground to make our work easily reproducible. Specifically, we use public database LFW (Labeled Faces in the Wild) to train CNNs, unlike most existing CNNs trained on private databases. We propose three CNN architectures which are the first reported architectures trained using LFW data. This paper quantitatively compares the architectures of CNNs and evaluate the effect of different implementation choices. We identify several useful properties of CNN-FRS. For instance, the dimensionality of the learned features can be significantly reduced without adverse effect on face recognition accuracy. In addition, traditional metric learning method exploiting CNN-learned features is evaluated. Experiments show two crucial factors to good CNN-FRS performance are the fusion of multiple CNNs and metric learning. To make our work reproducible, source code and models will be made publicly available.
Weakly Supervised Learning of Objects, Attributes and their Associations
Mar 31, 2015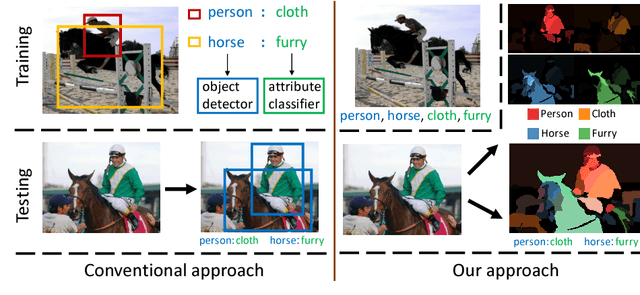
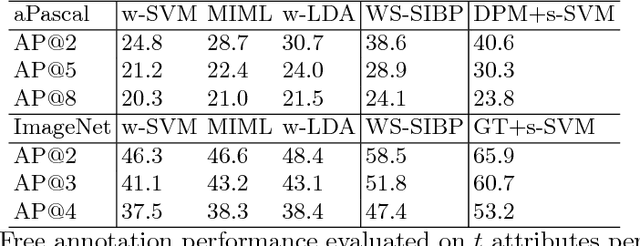
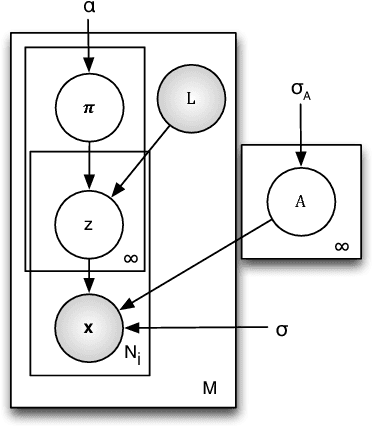
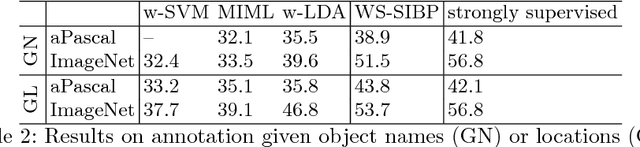
When humans describe images they tend to use combinations of nouns and adjectives, corresponding to objects and their associated attributes respectively. To generate such a description automatically, one needs to model objects, attributes and their associations. Conventional methods require strong annotation of object and attribute locations, making them less scalable. In this paper, we model object-attribute associations from weakly labelled images, such as those widely available on media sharing sites (e.g. Flickr), where only image-level labels (either object or attributes) are given, without their locations and associations. This is achieved by introducing a novel weakly supervised non-parametric Bayesian model. Once learned, given a new image, our model can describe the image, including objects, attributes and their associations, as well as their locations and segmentation. Extensive experiments on benchmark datasets demonstrate that our weakly supervised model performs at par with strongly supervised models on tasks such as image description and retrieval based on object-attribute associations.
Transductive Multi-class and Multi-label Zero-shot Learning
Mar 26, 2015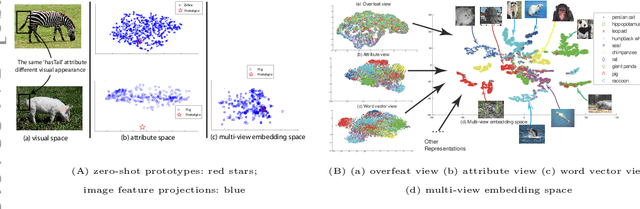

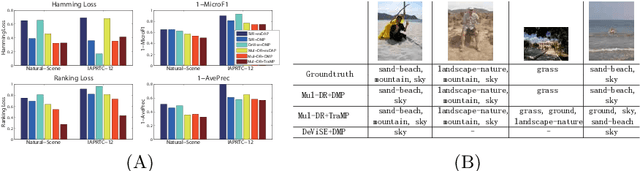
Recently, zero-shot learning (ZSL) has received increasing interest. The key idea underpinning existing ZSL approaches is to exploit knowledge transfer via an intermediate-level semantic representation which is assumed to be shared between the auxiliary and target datasets, and is used to bridge between these domains for knowledge transfer. The semantic representation used in existing approaches varies from visual attributes to semantic word vectors and semantic relatedness. However, the overall pipeline is similar: a projection mapping low-level features to the semantic representation is learned from the auxiliary dataset by either classification or regression models and applied directly to map each instance into the same semantic representation space where a zero-shot classifier is used to recognise the unseen target class instances with a single known 'prototype' of each target class. In this paper we discuss two related lines of work improving the conventional approach: exploiting transductive learning ZSL, and generalising ZSL to the multi-label case.
Transductive Multi-label Zero-shot Learning
Mar 26, 2015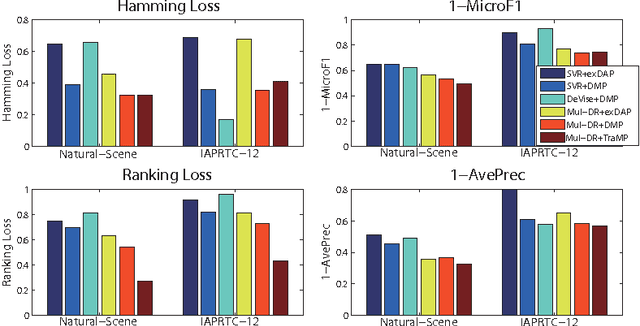


Zero-shot learning has received increasing interest as a means to alleviate the often prohibitive expense of annotating training data for large scale recognition problems. These methods have achieved great success via learning intermediate semantic representations in the form of attributes and more recently, semantic word vectors. However, they have thus far been constrained to the single-label case, in contrast to the growing popularity and importance of more realistic multi-label data. In this paper, for the first time, we investigate and formalise a general framework for multi-label zero-shot learning, addressing the unique challenge therein: how to exploit multi-label correlation at test time with no training data for those classes? In particular, we propose (1) a multi-output deep regression model to project an image into a semantic word space, which explicitly exploits the correlations in the intermediate semantic layer of word vectors; (2) a novel zero-shot learning algorithm for multi-label data that exploits the unique compositionality property of semantic word vector representations; and (3) a transductive learning strategy to enable the regression model learned from seen classes to generalise well to unseen classes. Our zero-shot learning experiments on a number of standard multi-label datasets demonstrate that our method outperforms a variety of baselines.
A Unified Perspective on Multi-Domain and Multi-Task Learning
Mar 26, 2015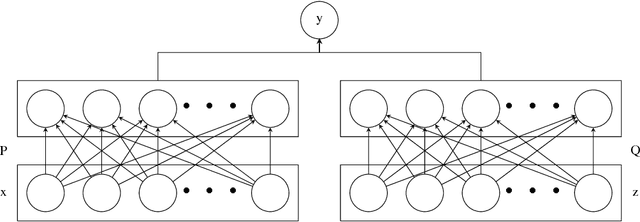
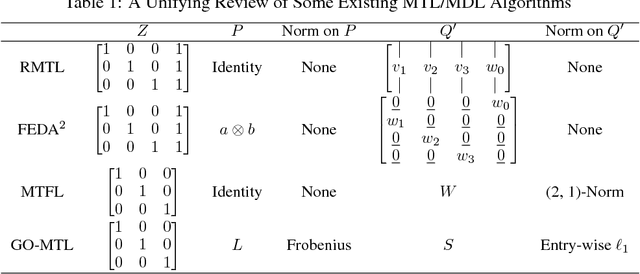


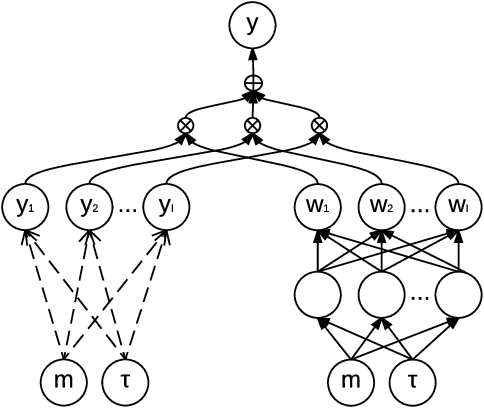
In this paper, we provide a new neural-network based perspective on multi-task learning (MTL) and multi-domain learning (MDL). By introducing the concept of a semantic descriptor, this framework unifies MDL and MTL as well as encompassing various classic and recent MTL/MDL algorithms by interpreting them as different ways of constructing semantic descriptors. Our interpretation provides an alternative pipeline for zero-shot learning (ZSL), where a model for a novel class can be constructed without training data. Moreover, it leads to a new and practically relevant problem setting of zero-shot domain adaptation (ZSDA), which is the analogous to ZSL but for novel domains: A model for an unseen domain can be generated by its semantic descriptor. Experiments across this range of problems demonstrate that our framework outperforms a variety of alternatives.