 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Privacy-preserving Filter
Aug 04, 2020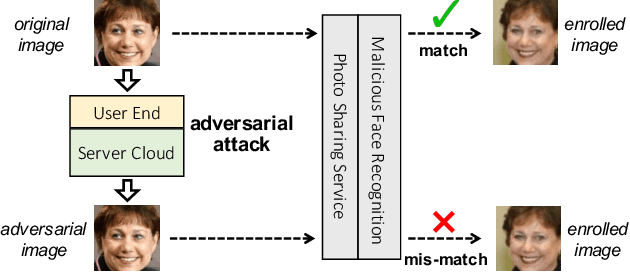
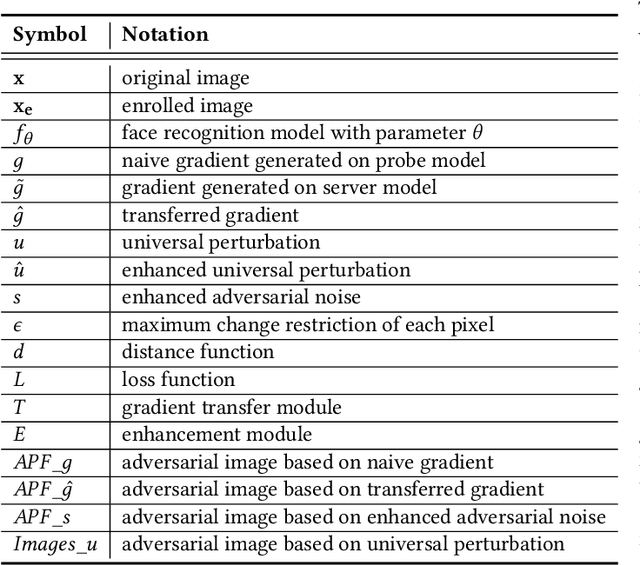
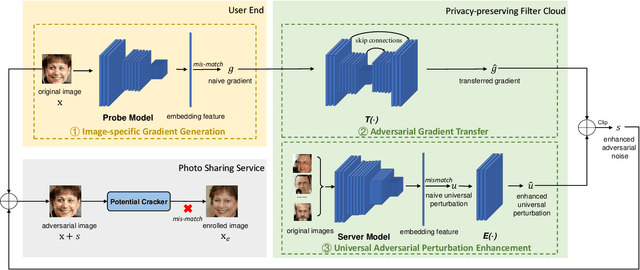
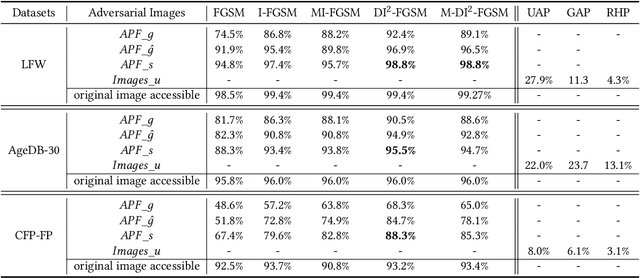
While widely adopted in practical applications, face recognition has been critically discussed regarding the malicious use of face images and the potential privacy problems, e.g., deceiving payment system and causing personal sabotage. Online photo sharing services unintentionally act as the main repository for malicious crawler and face recognition applications. This work aims to develop a privacy-preserving solution, called Adversarial Privacy-preserving Filter (APF), to protect the online shared face images from being maliciously used.We propose an end-cloud collaborated adversarial attack solution to satisfy requirements of privacy, utility and nonaccessibility. Specifically, the solutions consist of three modules: (1) image-specific gradient generation, to extract image-specific gradient in the user end with a compressed probe model; (2) adversarial gradient transfer, to fine-tune the image-specific gradient in the server cloud; and (3) universal adversarial perturbation enhancement, to append image-independent perturbation to derive the final adversarial noise. Extensive experiments on three datasets validate the effectiveness and efficiency of the proposed solution. A prototype application is also released for further evaluation.We hope the end-cloud collaborated attack framework could shed light on addressing the issue of online multimedia sharing privacy-preserving issues from user side.
blessing in disguise: Designing Robust Turing Test by Employing Algorithm Unrobustness
Apr 22, 2019
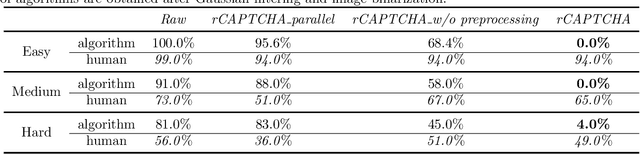
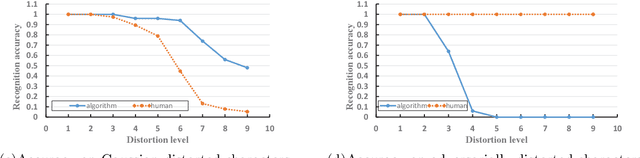
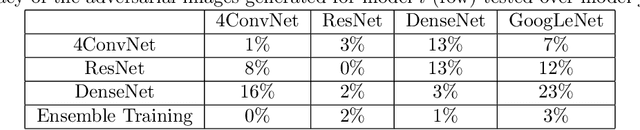
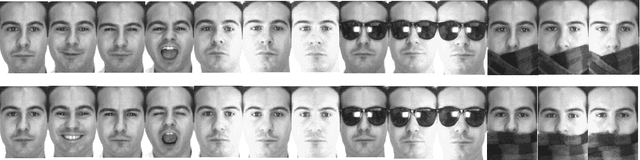
Turing test was originally proposed to examine whether machine's behavior is indistinguishable from a human. The most popular and practical Turing test is CAPTCHA, which is to discriminate algorithm from human by offering recognition-alike questions. The recent development of deep learning has significantly advanced the capability of algorithm in solving CAPTCHA questions, forcing CAPTCHA designers to increase question complexity. Instead of designing questions difficult for both algorithm and human, this study attempts to employ the limitations of algorithm to design robust CAPTCHA questions easily solvable to human. Specifically, our data analysis observes that human and algorithm demonstrates different vulnerability to visual distortions: adversarial perturbation is significantly annoying to algorithm yet friendly to human. We are motivated to employ adversarially perturbed images for robust CAPTCHA design in the context of character-based questions. Three modules of multi-target attack, ensemble adversarial training, and image preprocessing differentiable approximation are proposed to address the characteristics of character-based CAPTCHA cracking. Qualitative and quantitative experimental results demonstrate the effectiveness of the proposed solution. We hope this study can lead to the discussions around adversarial attack/defense in CAPTCHA design and also inspire the future attempts in employing algorithm limitation for practical usage.
Vectorial Dimension Reduction for Tensors Based on Bayesian Inference
Jul 03, 2017


Dimensionality reduction for high-order tensors is a challenging problem. In conventional approaches, higher order tensors are `vectorized` via Tucker decomposition to obtain lower order tensors. This will destroy the inherent high-order structures or resulting in undesired tensors, respectively. This paper introduces a probabilistic vectorial dimensionality reduction model for tensorial data. The model represents a tensor by employing a linear combination of same order basis tensors, thus it offers a mechanism to directly reduce a tensor to a vector. Under this expression, the projection base of the model is based on the tensor CandeComp/PARAFAC (CP) decomposition and the number of free parameters in the model only grows linearly with the number of modes rather than exponentially. A Bayesian inference has been established via the variational EM approach. A criterion to set the parameters (factor number of CP decomposition and the number of extracted features) is empirically given. The model outperforms several existing PCA-based methods and CP decomposition on several publicly available databases in terms of classification and clustering accuracy.
Localized LRR on Grassmann Manifolds: An Extrinsic View
May 17, 2017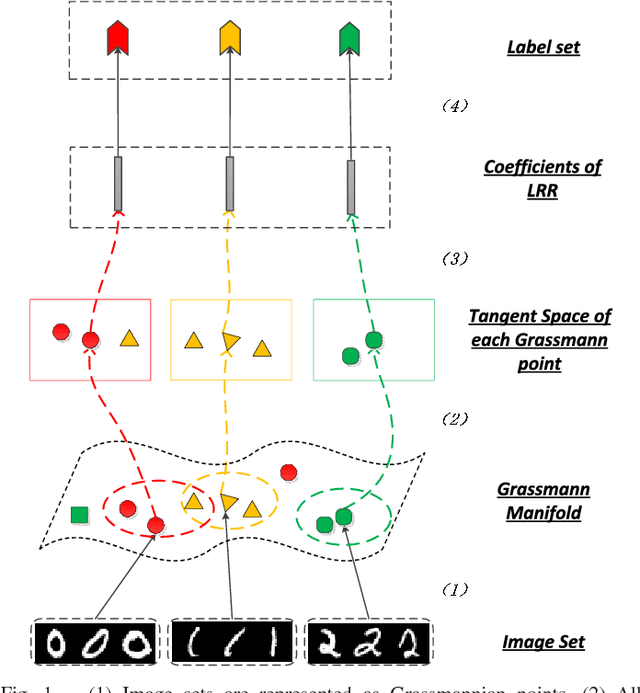

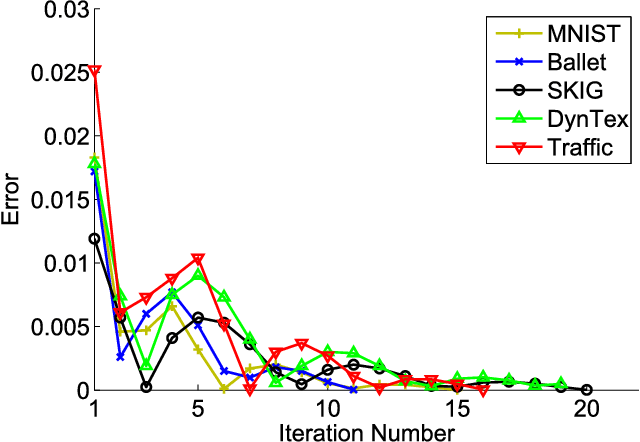
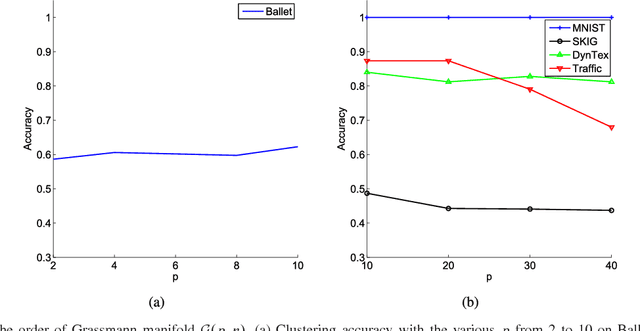
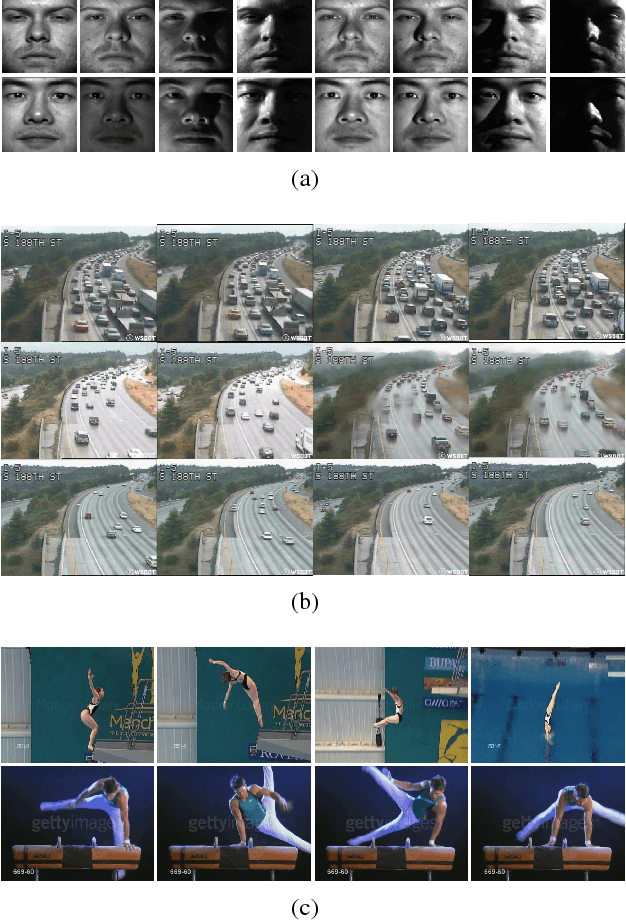
Subspace data representation has recently become a common practice in many computer vision tasks. It demands generalizing classical machine learning algorithms for subspace data. Low-Rank Representation (LRR) is one of the most successful models for clustering vectorial data according to their subspace structures. This paper explores the possibility of extending LRR for subspace data on Grassmann manifolds. Rather than directly embedding the Grassmann manifolds into the symmetric matrix space, an extrinsic view is taken to build the LRR self-representation in the local area of the tangent space at each Grassmannian point, resulting in a localized LRR method on Grassmann manifolds. A novel algorithm for solving the proposed model is investigated and implemented. The performance of the new clustering algorithm is assessed through experiments on several real-world datasets including MNIST handwritten digits, ballet video clips, SKIG action clips, DynTex++ dataset and highway traffic video clips. The experimental results show the new method outperforms a number of state-of-the-art clustering methods
Partial Sum Minimization of Singular Values Representation on Grassmann Manifolds
Apr 28, 2017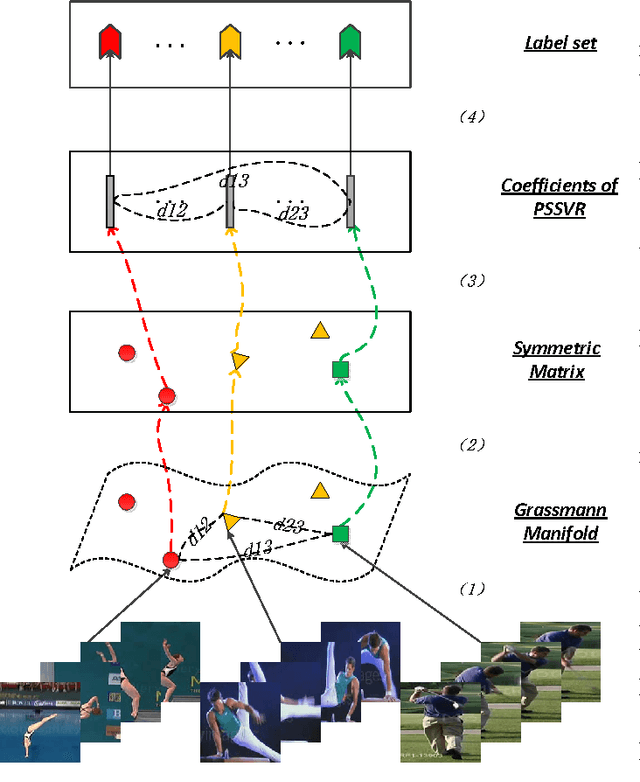
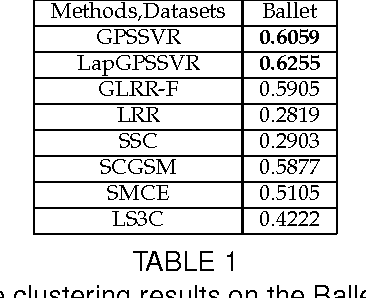

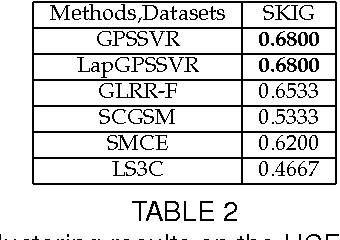
As a significant subspace clustering method, low rank representation (LRR) has attracted great attention in recent years. To further improve the performance of LRR and extend its applications, there are several issues to be resolved. The nuclear norm in LRR does not sufficiently use the prior knowledge of the rank which is known in many practical problems. The LRR is designed for vectorial data from linear spaces, thus not suitable for high dimensional data with intrinsic non-linear manifold structure. This paper proposes an extended LRR model for manifold-valued Grassmann data which incorporates prior knowledge by minimizing partial sum of singular values instead of the nuclear norm, namely Partial Sum minimization of Singular Values Representation (GPSSVR). The new model not only enforces the global structure of data in low rank, but also retains important information by minimizing only smaller singular values. To further maintain the local structures among Grassmann points, we also integrate the Laplacian penalty with GPSSVR. An effective algorithm is proposed to solve the optimization problem based on the GPSSVR model. The proposed model and algorithms are assessed on some widely used human action video datasets and a real scenery dataset. The experimental results show that the proposed methods obviously outperform other state-of-the-art methods.
Locality Preserving Projections for Grassmann manifold
Apr 27, 2017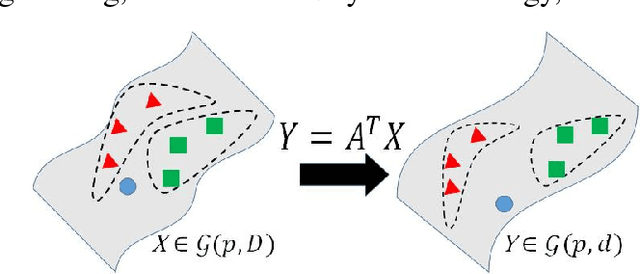

Learning on Grassmann manifold has become popular in many computer vision tasks, with the strong capability to extract discriminative information for imagesets and videos. However, such learning algorithms particularly on high-dimensional Grassmann manifold always involve with significantly high computational cost, which seriously limits the applicability of learning on Grassmann manifold in more wide areas. In this research, we propose an unsupervised dimensionality reduction algorithm on Grassmann manifold based on the Locality Preserving Projections (LPP) criterion. LPP is a commonly used dimensionality reduction algorithm for vector-valued data, aiming to preserve local structure of data in the dimension-reduced space. The strategy is to construct a mapping from higher dimensional Grassmann manifold into the one in a relative low-dimensional with more discriminative capability. The proposed method can be optimized as a basic eigenvalue problem. The performance of our proposed method is assessed on several classification and clustering tasks and the experimental results show its clear advantages over other Grassmann based algorithms.
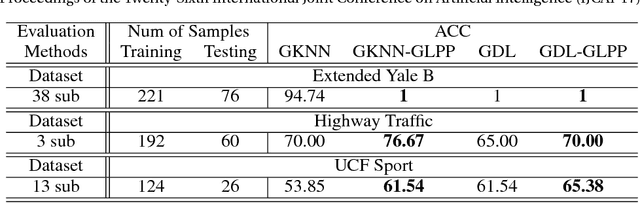
Block-Diagonal Sparse Representation by Learning a Linear Combination Dictionary for Recognition
Nov 28, 2016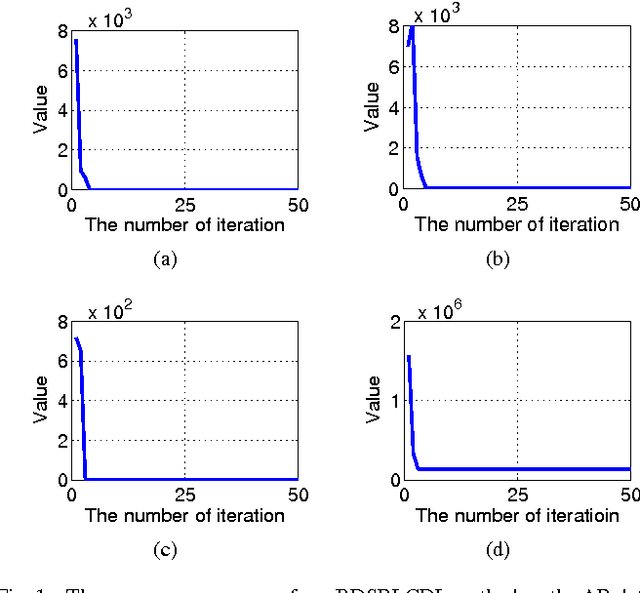

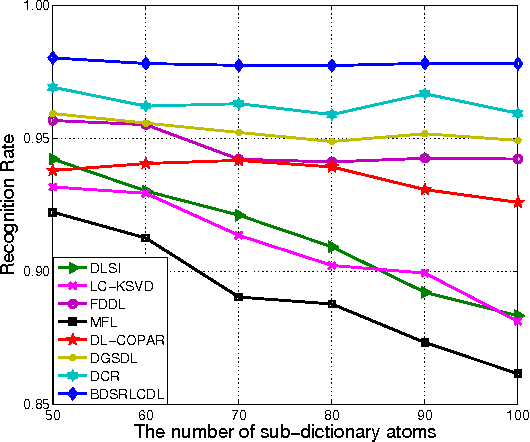

In a sparse representation based recognition scheme, it is critical to learn a desired dictionary, aiming both good representational power and discriminative performance. In this paper, we propose a new dictionary learning model for recognition applications, in which three strategies are adopted to achieve these two objectives simultaneously. First, a block-diagonal constraint is introduced into the model to eliminate the correlation between classes and enhance the discriminative performance. Second, a low-rank term is adopted to model the coherence within classes for refining the sparse representation of each class. Finally, instead of using the conventional over-complete dictionary, a specific dictionary constructed from the linear combination of the training samples is proposed to enhance the representational power of the dictionary and to improve the robustness of the sparse representation model. The proposed method is tested on several public datasets. The experimental results show the method outperforms most state-of-the-art methods.
Tensor Sparse and Low-Rank based Submodule Clustering Method for Multi-way Data
Sep 28, 2016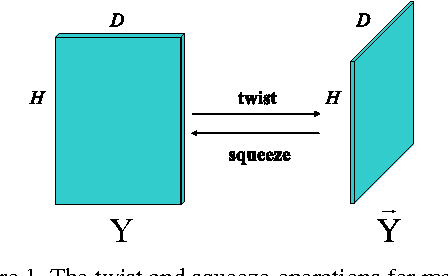
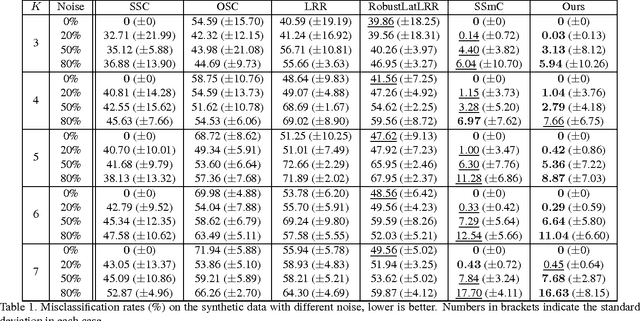
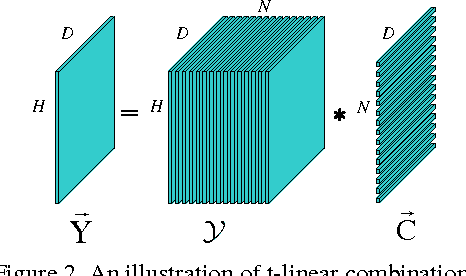
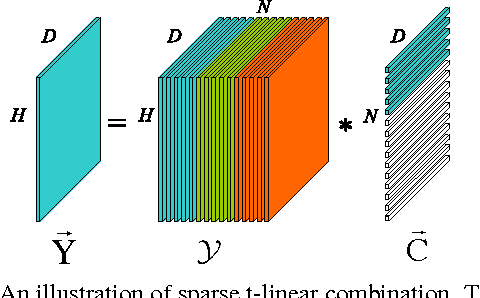
A new submodule clustering method via sparse and low-rank representation for multi-way data is proposed in this paper. Instead of reshaping multi-way data into vectors, this method maintains their natural orders to preserve data intrinsic structures, e.g., image data kept as matrices. To implement clustering, the multi-way data, viewed as tensors, are represented by the proposed tensor sparse and low-rank model to obtain its submodule representation, called a free module, which is finally used for spectral clustering. The proposed method extends the conventional subspace clustering method based on sparse and low-rank representation to multi-way data submodule clustering by combining t-product operator. The new method is tested on several public datasets, including synthetical data, video sequences and toy images. The experiments show that the new method outperforms the state-of-the-art methods, such as Sparse Subspace Clustering (SSC), Low-Rank Representation (LRR), Ordered Subspace Clustering (OSC), Robust Latent Low Rank Representation (RobustLatLRR) and Sparse Submodule Clustering method (SSmC).
Matrix Variate RBM Model with Gaussian Distributions
Sep 27, 2016
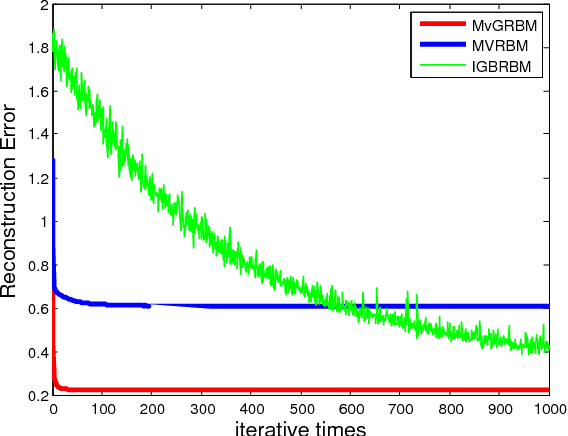


Restricted Boltzmann Machine (RBM) is a particular type of random neural network models modeling vector data based on the assumption of Bernoulli distribution. For multi-dimensional and non-binary data, it is necessary to vectorize and discretize the information in order to apply the conventional RBM. It is well-known that vectorization would destroy internal structure of data, and the binary units will limit the applying performance due to fickle real data. To address the issue, this paper proposes a Matrix variate Gaussian Restricted Boltzmann Machine (MVGRBM) model for matrix data whose entries follow Gaussian distributions. Compared with some other RBM algorithm, MVGRBM can model real value data better and it has good performance in image classification.
Partial Least Squares Regression on Riemannian Manifolds and Its Application in Classifications
Sep 21, 2016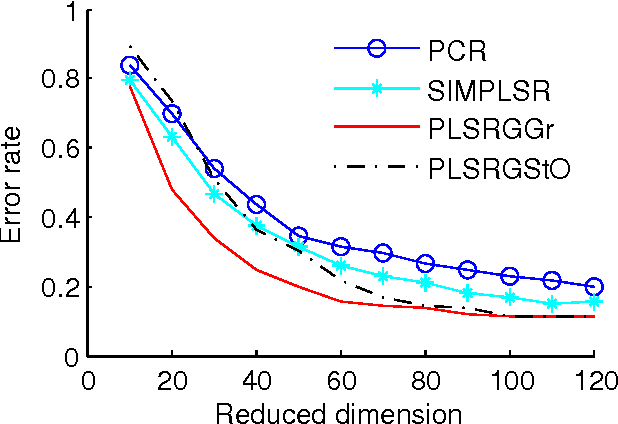
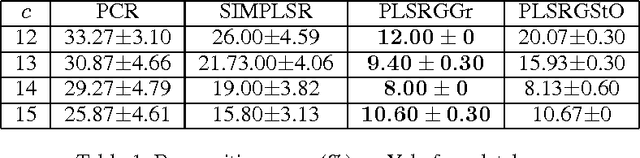
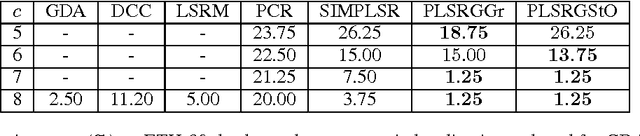
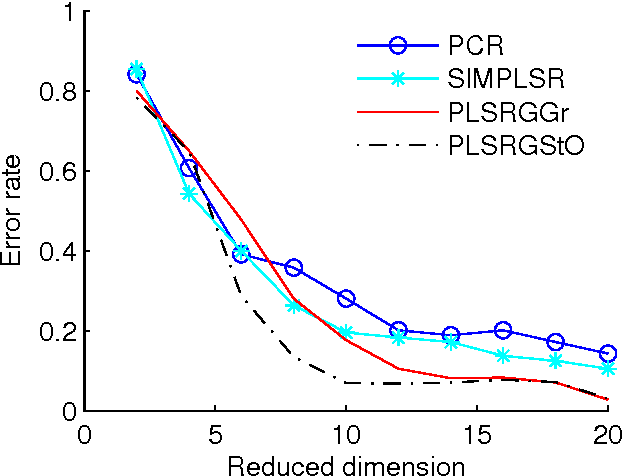
Partial least squares regression (PLSR) has been a popular technique to explore the linear relationship between two datasets. However, most of algorithm implementations of PLSR may only achieve a suboptimal solution through an optimization on the Euclidean space. In this paper, we propose several novel PLSR models on Riemannian manifolds and develop optimization algorithms based on Riemannian geometry of manifolds. This algorithm can calculate all the factors of PLSR globally to avoid suboptimal solutions. In a number of experiments, we have demonstrated the benefits of applying the proposed model and algorithm to a variety of learning tasks in pattern recognition and object classification.