 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperCLOVA X Technical Report
Apr 13, 2024We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
Ensemble-Based Deep Reinforcement Learning for Chatbots
Aug 27, 2019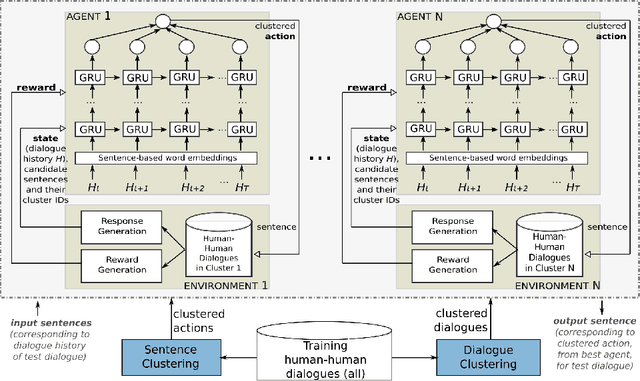



Trainable chatbots that exhibit fluent and human-like conversations remain a big challenge in artificial intelligence. Deep Reinforcement Learning (DRL) is promising for addressing this challenge, but its successful application remains an open question. This article describes a novel ensemble-based approach applied to value-based DRL chatbots, which use finite action sets as a form of meaning representation. In our approach, while dialogue actions are derived from sentence clustering, the training datasets in our ensemble are derived from dialogue clustering. The latter aim to induce specialised agents that learn to interact in a particular style. In order to facilitate neural chatbot training using our proposed approach, we assume dialogue data in raw text only -- without any manually-labelled data. Experimental results using chitchat data reveal that (1) near human-like dialogue policies can be induced, (2) generalisation to unseen data is a difficult problem, and (3) training an ensemble of chatbot agents is essential for improved performance over using a single agent. In addition to evaluations using held-out data, our results are further supported by a human evaluation that rated dialogues in terms of fluency, engagingness and consistency -- which revealed that our proposed dialogue rewards strongly correlate with human judgements.