 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCLeaf-Net: a transformer-convolution framework with global-local attention for robust in-field lesion-level plant leaf disease detection
Dec 13, 2025Timely and accurate detection of foliar diseases is vital for safeguarding crop growth and reducing yield losses. Yet, in real-field conditions, cluttered backgrounds, domain shifts, and limited lesion-level datasets hinder robust modeling. To address these challenges, we release Daylily-Leaf, a paired lesion-level dataset comprising 1,746 RGB images and 7,839 lesions captured under both ideal and in-field conditions, and propose TCLeaf-Net, a transformer-convolution hybrid detector optimized for real-field use. TCLeaf-Net is designed to tackle three major challenges. To mitigate interference from complex backgrounds, the transformer-convolution module (TCM) couples global context with locality-preserving convolution to suppress non-leaf regions. To reduce information loss during downsampling, the raw-scale feature recalling and sampling (RSFRS) block combines bilinear resampling and convolution to preserve fine spatial detail. To handle variations in lesion scale and feature shifts, the deformable alignment block with FPN (DFPN) employs offset-based alignment and multi-receptive-field perception to strengthen multi-scale fusion. Experimental results show that on the in-field split of the Daylily-Leaf dataset, TCLeaf-Net improves mAP@50 by 5.4 percentage points over the baseline model, reaching 78.2\%, while reducing computation by 7.5 GFLOPs and GPU memory usage by 8.7\%. Moreover, the model outperforms recent YOLO and RT-DETR series in both precision and recall, and demonstrates strong performance on the PlantDoc, Tomato-Leaf, and Rice-Leaf datasets, validating its robustness and generalizability to other plant disease detection scenarios.
Data-Driven Dynamics Modeling of Miniature Robotic Blimps Using Neural ODEs With Parameter Auto-Tuning
Apr 29, 2024Miniature robotic blimps, as one type of lighter-than-air aerial vehicles, have attracted increasing attention in the science and engineering community for their enhanced safety, extended endurance, and quieter operation compared to quadrotors. Accurately modeling the dynamics of these robotic blimps poses a significant challenge due to the complex aerodynamics stemming from their large lifting bodies. Traditional first-principle models have difficulty obtaining accurate aerodynamic parameters and often overlook high-order nonlinearities, thus coming to its limit in modeling the motion dynamics of miniature robotic blimps. To tackle this challenge, this letter proposes the Auto-tuning Blimp-oriented Neural Ordinary Differential Equation method (ABNODE), a data-driven approach that integrates first-principle and neural network modeling. Spiraling motion experiments of robotic blimps are conducted, comparing the ABNODE with first-principle and other data-driven benchmark models, the results of which demonstrate the effectiveness of the proposed method.
RGBlimp: Robotic Gliding Blimp -- Design, Modeling, Development, and Aerodynamics Analysis
Jun 07, 2023A miniature robotic blimp, as one type of lighter-than-air aerial vehicle, has attracted increasing attention in the science and engineering field for its long flight duration and safe aerial locomotion. While a variety of miniature robotic blimps have been developed over the past decade, most of them utilize the buoyant lift and neglect the aerodynamic lift in their design, thus leading to a mediocre aerodynamic performance. This letter proposes a new design of miniature robotic blimp that combines desirable features of both a robotic blimp and a fixed-wing glider, named the Robotic Gliding Blimp, or RGBlimp. This robot, equipped with an envelope filled with helium and a pair of wings, uses an internal moving mass and a pair of propellers for its locomotion control. This letter presents the design, dynamic modeling, prototyping, and system identification of the RGBlimp. To the best of the authors' knowledge, this is the first effort to systematically design and develop such a miniature robotic blimp with hybrid lifts and moving mass control. Experimental results are presented to validate the design and the dynamic model of the RGBlimp. Analysis of the RGBlimp aerodynamics is conducted which confirms the performance improvement of the proposed RGBlimp in aerodynamic efficiency and flight stability.
GraspARL: Dynamic Grasping via Adversarial Reinforcement Learning
Mar 14, 2022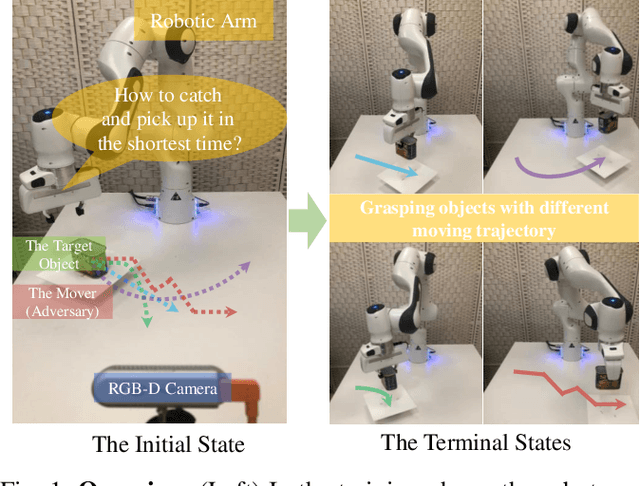
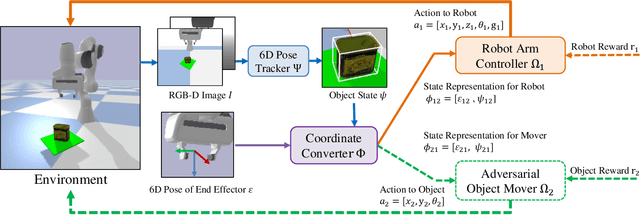
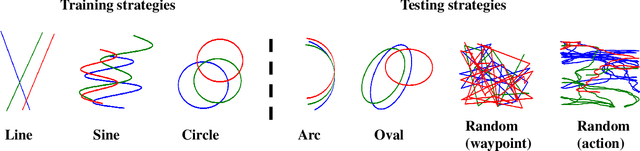

Grasping moving objects, such as goods on a belt or living animals, is an important but challenging task in robotics. Conventional approaches rely on a set of manually defined object motion patterns for training, resulting in poor generalization to unseen object trajectories. In this work, we introduce an adversarial reinforcement learning framework for dynamic grasping, namely GraspARL. To be specific. we formulate the dynamic grasping problem as a 'move-and-grasp' game, where the robot is to pick up the object on the mover and the adversarial mover is to find a path to escape it. Hence, the two agents play a min-max game and are trained by reinforcement learning. In this way, the mover can auto-generate diverse moving trajectories while training. And the robot trained with the adversarial trajectories can generalize to various motion patterns. Empirical results on the simulator and real-world scenario demonstrate the effectiveness of each and good generalization of our method.