 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Guided Universum Learning in Generalized Eigenvalue Proximal SVMs for Alzheimer's Disease Classification
Jun 03, 2026Early and accurate detection of Alzheimer's disease (AD) is important for timely intervention and disease management. Generalized Eigenvalue Proximal Support Vector Machine (GEPSVM) and its Universum-based variants have shown promising results for AD classification. However, existing methods treat Universum samples as independent points and do not consider the geometric relationships among them. This paper proposes two graph-guided Universum learning models, namely UG-GEPSVM and IUG-GEPSVM, for AD versus cognitively normal (CN) classification using structural MRI data. In the proposed framework, mild cognitive impairment (MCI) subjects are used as Universum data to provide intermediate information between AD and CN classes. A graph is constructed over the Universum samples using Gaussian similarity, Minimum Spanning Tree connectivity, and multi-hop propagation. From this graph, a Laplacian matrix is derived that captures the geometric structure of the MCI samples. This Laplacian-based regularization is incorporated into the learning process in place of the conventional independent Universum penalty term. UG-GEPSVM integrates this regularization into the generalized eigenvalue formulation, while IUG-GEPSVM extends the numerically stable improved GEPSVM framework using a standard eigenvalue formulation. Experiments on ADNI MRI dataset variants using ICA- and PCA-based features at five different noise levels show that both proposed models consistently outperform existing GEPSVM and Universum-based methods. UG-GEPSVM achieves the highest average AUC of 88.07% and maintains stable performance under increasing noise levels. Statistical tests further confirm the significance of the observed improvements.
MINT: Multimodal Imaging-to-Speech Knowledge Transfer for Early Alzheimer's Screening
Feb 27, 2026Alzheimer's disease is a progressive neurodegenerative disorder in which mild cognitive impairment (MCI) marks a critical transition between aging and dementia. Neuroimaging modalities, such as structural MRI, provide biomarkers of this transition; however, their high costs and infrastructure needs limit their deployment at a population scale. Speech analysis offers a non-invasive alternative, but speech-only classifiers are developed independently of neuroimaging, leaving decision boundaries biologically ungrounded and limiting reliability on the subtle CN-versus-MCI distinction. We propose MINT (Multimodal Imaging-to-Speech Knowledge Transfer), a three-stage cross-modal framework that transfers biomarker structure from MRI into a speech encoder at training time. An MRI teacher, trained on 1,228 subjects, defines a compact neuroimaging embedding space for CN-versus-MCI classification. A residual projection head aligns speech representations to this frozen imaging manifold via a combined geometric loss, adapting speech to the learned biomarker space while preserving imaging encoder fidelity. The frozen MRI classifier, which is never exposed to speech, is applied to aligned embeddings at inference and requires no scanner. Evaluation on ADNI-4 shows aligned speech achieves performance comparable to speech-only baselines (AUC 0.720 vs 0.711) while requiring no imaging at inference, demonstrating that MRI-derived decision boundaries can ground speech representations. Multimodal fusion improves over MRI alone (0.973 vs 0.958). Ablation studies identify dropout regularization and self-supervised pretraining as critical design decisions. To our knowledge, this is the first demonstration of MRI-to-speech knowledge transfer for early Alzheimer's screening, establishing a biologically grounded pathway for population-level cognitive triage without neuroimaging at inference.
A Unified Framework for EEG Seizure Detection Using Universum-Integrated Generalized Eigenvalues Proximal Support Vector Machine
Dec 24, 2025The paper presents novel Universum-enhanced classifiers: the Universum Generalized Eigenvalue Proximal Support Vector Machine (U-GEPSVM) and the Improved U-GEPSVM (IU-GEPSVM) for EEG signal classification. Using the computational efficiency of generalized eigenvalue decomposition and the generalization benefits of Universum learning, the proposed models address critical challenges in EEG analysis: non-stationarity, low signal-to-noise ratio, and limited labeled data. U-GEPSVM extends the GEPSVM framework by incorporating Universum constraints through a ratio-based objective function, while IU-GEPSVM enhances stability through a weighted difference-based formulation that provides independent control over class separation and Universum alignment. The models are evaluated on the Bonn University EEG dataset across two binary classification tasks: (O vs S)-healthy (eyes closed) vs seizure, and (Z vs S)-healthy (eyes open) vs seizure. IU-GEPSVM achieves peak accuracies of 85% (O vs S) and 80% (Z vs S), with mean accuracies of 81.29% and 77.57% respectively, outperforming baseline methods.
Temporal Object-Aware Vision Transformer for Few-Shot Video Object Detection
Nov 16, 2025



Few-shot Video Object Detection (FSVOD) addresses the challenge of detecting novel objects in videos with limited labeled examples, overcoming the constraints of traditional detection methods that require extensive training data. This task presents key challenges, including maintaining temporal consistency across frames affected by occlusion and appearance variations, and achieving novel object generalization without relying on complex region proposals, which are often computationally expensive and require task-specific training. Our novel object-aware temporal modeling approach addresses these challenges by incorporating a filtering mechanism that selectively propagates high-confidence object features across frames. This enables efficient feature progression, reduces noise accumulation, and enhances detection accuracy in a few-shot setting. By utilizing few-shot trained detection and classification heads with focused feature propagation, we achieve robust temporal consistency without depending on explicit object tube proposals. Our approach achieves performance gains, with AP improvements of 3.7% (FSVOD-500), 5.3% (FSYTV-40), 4.3% (VidOR), and 4.5 (VidVRD) in the 5-shot setting. Further results demonstrate improvements in 1-shot, 3-shot, and 10-shot configurations. We make the code public at: https://github.com/yogesh-iitj/fs-video-vit
Language-Guided Temporal Token Pruning for Efficient VideoLLM Processing
Aug 25, 2025Vision Language Models (VLMs) struggle with long-form videos due to the quadratic complexity of attention mechanisms. We propose Language-Guided Temporal Token Pruning (LGTTP), which leverages temporal cues from queries to adaptively prune video tokens, preserving contextual continuity while reducing computational overhead. Unlike uniform pruning or keyframe selection, LGTTP retains higher token density in temporally relevant segments. Our model-agnostic framework integrates with TimeChat and LLaVA-Video, achieving a 65% reduction in computation while preserving 97-99% of the original performance. On QVHighlights, LGTTP improves HIT@1 by +9.5%, and on Charades-STA, it retains 99.6% of R@1. It excels on queries with explicit temporal markers and remains effective across general video understanding tasks.
VideoLLM Benchmarks and Evaluation: A Survey
May 03, 2025The rapid development of Large Language Models (LLMs) has catalyzed significant advancements in video understanding technologies. This survey provides a comprehensive analysis of benchmarks and evaluation methodologies specifically designed or used for Video Large Language Models (VideoLLMs). We examine the current landscape of video understanding benchmarks, discussing their characteristics, evaluation protocols, and limitations. The paper analyzes various evaluation methodologies, including closed-set, open-set, and specialized evaluations for temporal and spatiotemporal understanding tasks. We highlight the performance trends of state-of-the-art VideoLLMs across these benchmarks and identify key challenges in current evaluation frameworks. Additionally, we propose future research directions to enhance benchmark design, evaluation metrics, and protocols, including the need for more diverse, multimodal, and interpretability-focused benchmarks. This survey aims to equip researchers with a structured understanding of how to effectively evaluate VideoLLMs and identify promising avenues for advancing the field of video understanding with large language models.
Design, Contact Modeling, and Collision-inclusive Planning of a Dual-stiffness Aerial RoboT (DART)
Apr 26, 2025



Collision-resilient quadrotors have gained significant attention given their potential for operating in cluttered environments and leveraging impacts to perform agile maneuvers. However, existing designs are typically single-mode: either safeguarded by propeller guards that prevent deformation or deformable but lacking rigidity, which is crucial for stable flight in open environments. This paper introduces DART, a Dual-stiffness Aerial RoboT, that adapts its post-collision response by either engaging a locking mechanism for a rigid mode or disengaging it for a flexible mode, respectively. Comprehensive characterization tests highlight the significant difference in post collision responses between its rigid and flexible modes, with the rigid mode offering seven times higher stiffness compared to the flexible mode. To understand and harness the collision dynamics, we propose a novel collision response prediction model based on the linear complementarity system theory. We demonstrate the accuracy of predicting collision forces for both the rigid and flexible modes of DART. Experimental results confirm the accuracy of the model and underscore its potential to advance collision-inclusive trajectory planning in aerial robotics.
Towards Making Flowchart Images Machine Interpretable
Jan 29, 2025Computer programming textbooks and software documentations often contain flowcharts to illustrate the flow of an algorithm or procedure. Modern OCR engines often tag these flowcharts as graphics and ignore them in further processing. In this paper, we work towards making flowchart images machine-interpretable by converting them to executable Python codes. To this end, inspired by the recent success in natural language to code generation literature, we present a novel transformer-based framework, namely FloCo-T5. Our model is well-suited for this task,as it can effectively learn semantics, structure, and patterns of programming languages, which it leverages to generate syntactically correct code. We also used a task-specific pre-training objective to pre-train FloCo-T5 using a large number of logic-preserving augmented code samples. Further, to perform a rigorous study of this problem, we introduce theFloCo dataset that contains 11,884 flowchart images and their corresponding Python codes. Our experiments show promising results, and FloCo-T5 clearly outperforms related competitive baselines on code generation metrics. We make our dataset and implementation publicly available.
Improving Medical Multi-modal Contrastive Learning with Expert Annotations
Mar 15, 2024We introduce eCLIP, an enhanced version of the CLIP model that integrates expert annotations in the form of radiologist eye-gaze heatmaps. It tackles key challenges in contrastive multi-modal medical imaging analysis, notably data scarcity and the "modality gap" -- a significant disparity between image and text embeddings that diminishes the quality of representations and hampers cross-modal interoperability. eCLIP integrates a heatmap processor and leverages mixup augmentation to efficiently utilize the scarce expert annotations, thus boosting the model's learning effectiveness. eCLIP is designed to be generally applicable to any variant of CLIP without requiring any modifications of the core architecture. Through detailed evaluations across several tasks, including zero-shot inference, linear probing, cross-modal retrieval, and Retrieval Augmented Generation (RAG) of radiology reports using a frozen Large Language Model, eCLIP showcases consistent improvements in embedding quality. The outcomes reveal enhanced alignment and uniformity, affirming eCLIP's capability to harness high-quality annotations for enriched multi-modal analysis in the medical imaging domain.
Deconfounded Representation Similarity for Comparison of Neural Networks
Jan 31, 2022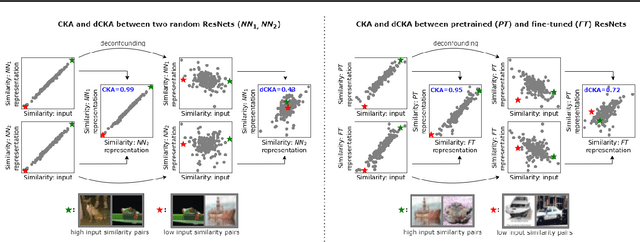
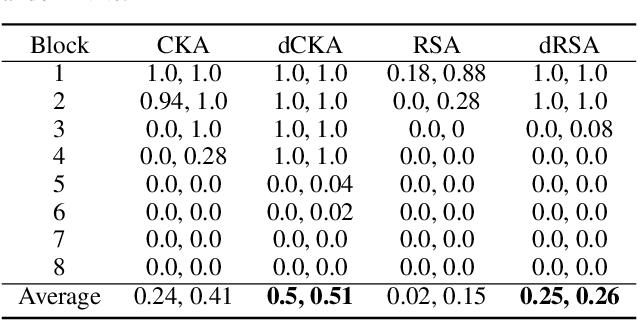
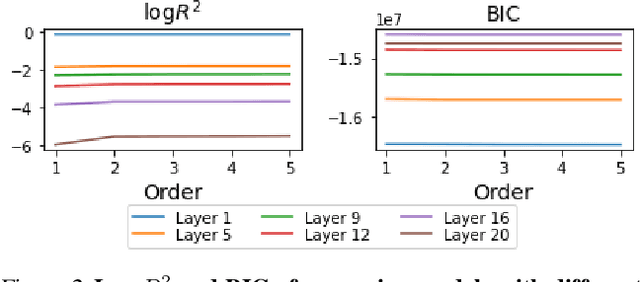
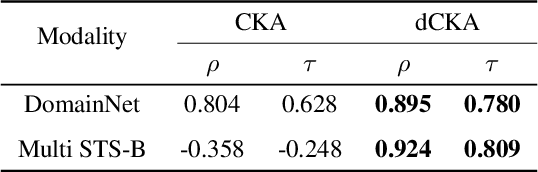
Similarity metrics such as representational similarity analysis (RSA) and centered kernel alignment (CKA) have been used to compare layer-wise representations between neural networks. However, these metrics are confounded by the population structure of data items in the input space, leading to spuriously high similarity for even completely random neural networks and inconsistent domain relations in transfer learning. We introduce a simple and generally applicable fix to adjust for the confounder with covariate adjustment regression, which retains the intuitive invariance properties of the original similarity measures. We show that deconfounding the similarity metrics increases the resolution of detecting semantically similar neural networks. Moreover, in real-world applications, deconfounding improves the consistency of representation similarities with domain similarities in transfer learning, and increases correlation with out-of-distribution accuracy.