 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBrick-DICL: Dynamic In-Context Learning for Automated Brick Schema Classification
Jun 16, 2026Building Management Systems (BMS) are essential for optimizing energy efficiency and operational performance in modern buildings. However, the lack of standardization across BMS points from different manufacturers creates significant barriers to integration and data utilization. While the Brick schema offers a standardized ontology for building systems, mapping BMS points to appropriate Brick classes presents three critical challenges: (i) the extensive number of Brick classes (936 in the latest version), (ii) limited domain-specific knowledge in large language models (LLMs), and (iii) substantial manual effort required for verification. To address these challenges, we propose Brick-DICL, a two-stage dynamic in-context learning framework for automated Brick schema classification. Brick-DICL consists of two primary components: metadata-RAG, which retrieves relevant examples to enhance LLMs' domain knowledge, and class-RAG, which narrows down potential Brick classes to address the large classification space. Additionally, we implement a multi-LLM filtering mechanism that compares predictions across multiple models, flagging low-confidence classifications for human review. As a result: (i) General: Brick-DICL is applicable to any building management system regardless of manufacturer or metadata format; (ii) Novel and Powerful: as the first dynamic in-context learning approach for Brick schema classification, Brick-DICL achieves significant classification accuracy improvements on building datasets, outperforming existing methods; (iii) Efficient: our multi-LLM filtering strategy reduces manual verification effort, enabling rapid digital building onboarding. Extensive experiments demonstrate Brick-DICL's effectiveness across diverse building datasets, accelerating the path toward standardized, interoperable building management systems.
CollabEval: Enhancing LLM-as-a-Judge via Multi-Agent Collaboration
Mar 01, 2026Large Language Models (LLMs) have revolutionized AI-generated content evaluation, with the LLM-as-a-Judge paradigm becoming increasingly popular. However, current single-LLM evaluation approaches face significant challenges, including inconsistent judgments and inherent biases from pre-training data. To address these limitations, we propose CollabEval, a novel multi-agent evaluation framework that implements a three-phase Collaborative Evaluation process: initial evaluation, multi-round discussion, and final judgment. Unlike existing approaches that rely on competitive debate or single-model evaluation, CollabEval emphasizes collaboration among multiple agents with strategic consensus checking for efficiency. Our extensive experiments demonstrate that CollabEval consistently outperforms single-LLM approaches across multiple dimensions while maintaining robust performance even when individual models struggle. The framework provides comprehensive support for various evaluation criteria while ensuring efficiency through its collaborative design.
Agentic generative AI for media content discovery at the national football league
Oct 08, 2025Generative AI has unlocked new possibilities in content discovery and management. Through collaboration with the National Football League (NFL), we demonstrate how a generative-AI based workflow enables media researchers and analysts to query relevant historical plays using natural language rather than traditional filter-and-click interfaces. The agentic workflow takes a user query as input, breaks it into elements, and translates them into the underlying database query language. Accuracy and latency are further improved through carefully designed semantic caching. The solution achieves over 95 percent accuracy and reduces the average time to find relevant videos from 10 minutes to 30 seconds, significantly increasing the NFL's operational efficiency and allowing users to focus on producing creative content and engaging storylines.
AutoData: A Multi-Agent System for Open Web Data Collection
May 21, 2025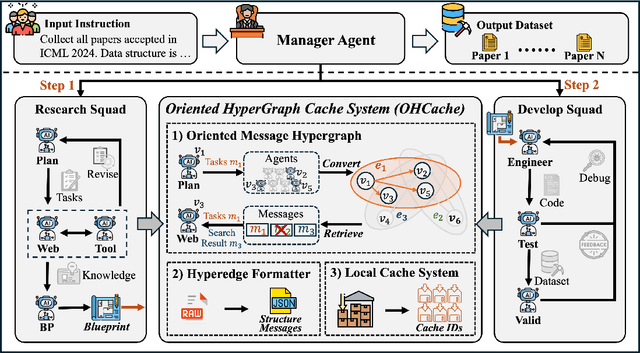
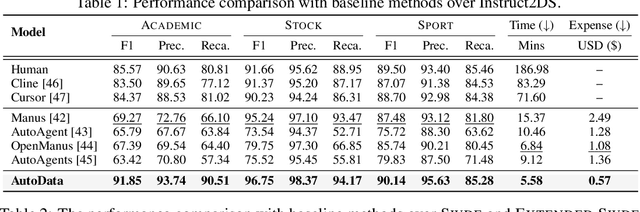
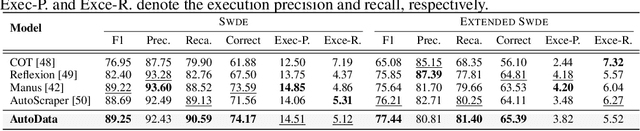

The exponential growth of data-driven systems and AI technologies has intensified the demand for high-quality web-sourced datasets. While existing datasets have proven valuable, conventional web data collection approaches face significant limitations in terms of human effort and scalability. Current data-collecting solutions fall into two categories: wrapper-based methods that struggle with adaptability and reproducibility, and large language model (LLM)-based approaches that incur substantial computational and financial costs. To address these challenges, we propose AutoData, a novel multi-agent system for Automated web Data collection, that requires minimal human intervention, i.e., only necessitating a natural language instruction specifying the desired dataset. In addition, AutoData is designed with a robust multi-agent architecture, featuring a novel oriented message hypergraph coordinated by a central task manager, to efficiently organize agents across research and development squads. Besides, we introduce a novel hypergraph cache system to advance the multi-agent collaboration process that enables efficient automated data collection and mitigates the token cost issues prevalent in existing LLM-based systems. Moreover, we introduce Instruct2DS, a new benchmark dataset supporting live data collection from web sources across three domains: academic, finance, and sports. Comprehensive evaluations over Instruct2DS and three existing benchmark datasets demonstrate AutoData's superior performance compared to baseline methods. Case studies on challenging tasks such as picture book collection and paper extraction from surveys further validate its applicability. Our source code and dataset are available at https://github.com/GraphResearcher/AutoData.
Domain Adaptation of VLM for Soccer Video Understanding
May 20, 2025



Vision Language Models (VLMs) have demonstrated strong performance in multi-modal tasks by effectively aligning visual and textual representations. However, most video understanding VLM research has been domain-agnostic, leaving the understanding of their transfer learning capability to specialized domains under-explored. In this work, we address this by exploring the adaptability of open-source VLMs to specific domains, and focusing on soccer as an initial case study. Our approach uses large-scale soccer datasets and LLM to create instruction-following data, and use them to iteratively fine-tune the general-domain VLM in a curriculum learning fashion (first teaching the model key soccer concepts to then question answering tasks). The final adapted model, trained using a curated dataset of 20k video clips, exhibits significant improvement in soccer-specific tasks compared to the base model, with a 37.5% relative improvement for the visual question-answering task and an accuracy improvement from 11.8% to 63.5% for the downstream soccer action classification task.