 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerification-Guided Context Optimization for Tool Calling via Hierarchical LLMs-as-Editors
Dec 15, 2025



Tool calling enables large language models (LLMs) to interact with external environments through tool invocation, providing a practical way to overcome the limitations of pretraining. However, the effectiveness of tool use depends heavily on the quality of the associated documentation and knowledge base context. These materials are usually written for human users and are often misaligned with how LLMs interpret information. This problem is even more pronounced in industrial settings, where hundreds of tools with overlapping functionality create challenges in scalability, variability, and ambiguity. We propose Verification-Guided Context Optimization (VGCO), a framework that uses LLMs as editors to automatically refine tool-related documentation and knowledge base context. VGCO works in two stages. First, Evaluation collects real-world failure cases and identifies mismatches between tools and their context. Second, Optimization performs hierarchical editing through offline learning with structure-aware, in-context optimization. The novelty of our LLM editors has three main aspects. First, they use a hierarchical structure that naturally integrates into the tool-calling workflow. Second, they are state-aware, action-specific, and verification-guided, which constrains the search space and enables efficient, targeted improvements. Third, they enable cost-efficient sub-task specialization, either by prompt engineering large editor models or by post-training smaller editor models. Unlike prior work that emphasizes multi-turn reasoning, VGCO focuses on the single-turn, large-scale tool-calling problem and achieves significant improvements in accuracy, robustness, and generalization across LLMs.
Performance-Guided LLM Knowledge Distillation for Efficient Text Classification at Scale
Nov 07, 2024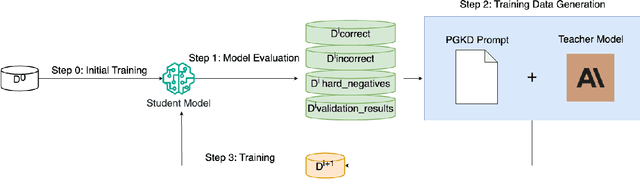
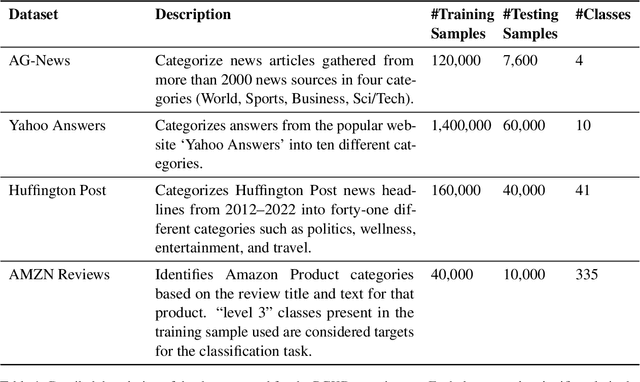
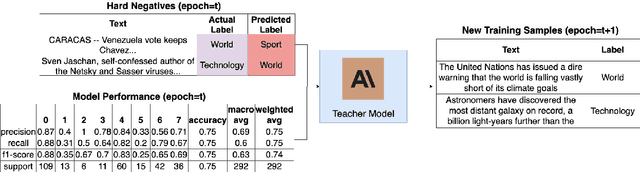
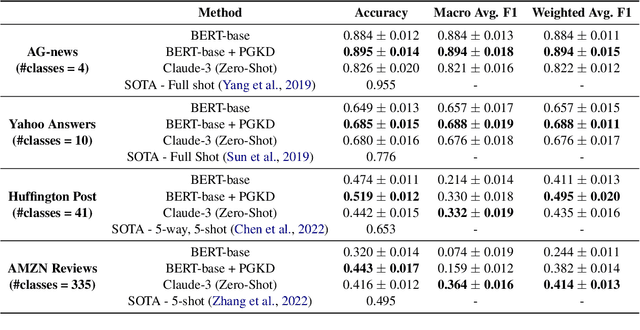
Large Language Models (LLMs) face significant challenges at inference time due to their high computational demands. To address this, we present Performance-Guided Knowledge Distillation (PGKD), a cost-effective and high-throughput solution for production text classification applications. PGKD utilizes teacher-student Knowledge Distillation to distill the knowledge of LLMs into smaller, task-specific models. PGKD establishes an active learning routine between the student model and the LLM; the LLM continuously generates new training data leveraging hard-negative mining, student model validation performance, and early-stopping protocols to inform the data generation. By employing a cyclical, performance-aware approach tailored for highly multi-class, sparsely annotated datasets prevalent in industrial text classification, PGKD effectively addresses training challenges and outperforms traditional BERT-base models and other knowledge distillation methods on several multi-class classification datasets. Additionally, cost and latency benchmarking reveals that models fine-tuned with PGKD are up to 130X faster and 25X less expensive than LLMs for inference on the same classification task. While PGKD is showcased for text classification tasks, its versatile framework can be extended to any LLM distillation task, including language generation, making it a powerful tool for optimizing performance across a wide range of AI applications.
Enriching Neural Models with Targeted Features for Dementia Detection
Jun 13, 2019
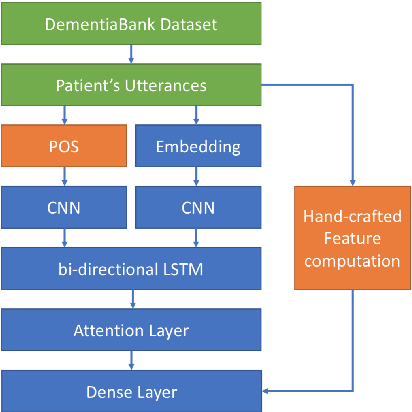

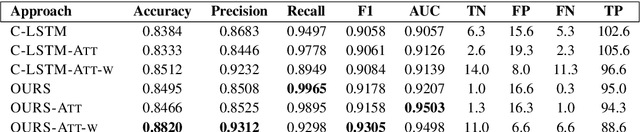
Alzheimer's disease (AD) is an irreversible brain disease that can dramatically reduce quality of life, most commonly manifesting in older adults and eventually leading to the need for full-time care. Early detection is fundamental to slowing its progression; however, diagnosis can be expensive, time-consuming, and invasive. In this work we develop a neural model based on a CNN-LSTM architecture that learns to detect AD and related dementias using targeted and implicitly-learned features from conversational transcripts. Our approach establishes the new state of the art on the DementiaBank dataset, achieving an F1 score of 0.929 when classifying participants into AD and control groups.