 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 100-GHz CMOS-Compatible RIS-on-Chip Based on Phase-Delay Lines for 6G Applications
Dec 21, 2025



On-chip reconfigurable intelligent surfaces (RIS) are expected to play a vital role in future 6G communication systems. This work proposed a CMOS-compatible on-chip RIS capable of achieving beam steering for the first time. The proposed unit cell design is a combination of a slot, a phase-delay line with VO2, and a ground. Under the two states of the VO2, the unit cell has a 180 deg phase difference at the center frequency, while maintaining reflection magnitudes better than -1.2 dB. Moreover, a 60by60 RIS array based on the present novel unit is designed, demonstrating the beam-steering capability. Finally, to validate the design concept, a prototype is fabricated, and the detailed fabrication process is presented. The measurement result demonstrates a 27.1 dB enhancement between ON and OFF states. The proposed RIS has the advantages of low loss, CMOS-compatibility, providing a foundation for future 6G applications.
DeepMath-Creative: A Benchmark for Evaluating Mathematical Creativity of Large Language Models
May 13, 2025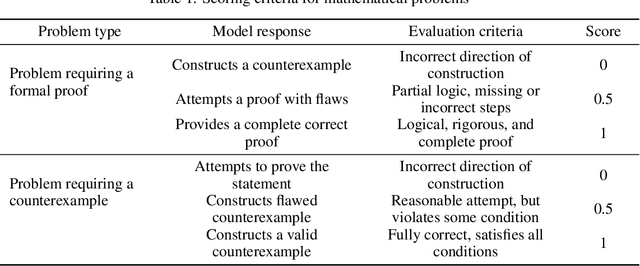
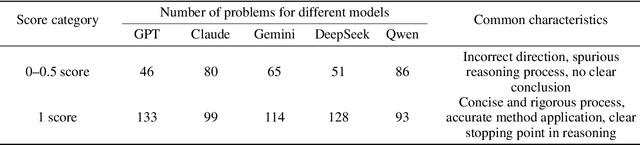
To advance the mathematical proficiency of large language models (LLMs), the DeepMath team has launched an open-source initiative aimed at developing an open mathematical LLM and systematically evaluating its mathematical creativity. This paper represents the initial contribution of this initiative. While recent developments in mathematical LLMs have predominantly emphasized reasoning skills, as evidenced by benchmarks on elementary to undergraduate-level mathematical tasks, the creative capabilities of these models have received comparatively little attention, and evaluation datasets remain scarce. To address this gap, we propose an evaluation criteria for mathematical creativity and introduce DeepMath-Creative, a novel, high-quality benchmark comprising constructive problems across algebra, geometry, analysis, and other domains. We conduct a systematic evaluation of mainstream LLMs' creative problem-solving abilities using this dataset. Experimental results show that even under lenient scoring criteria -- emphasizing core solution components and disregarding minor inaccuracies, such as small logical gaps, incomplete justifications, or redundant explanations -- the best-performing model, O3 Mini, achieves merely 70% accuracy, primarily on basic undergraduate-level constructive tasks. Performance declines sharply on more complex problems, with models failing to provide substantive strategies for open problems. These findings suggest that, although current LLMs display a degree of constructive proficiency on familiar and lower-difficulty problems, such performance is likely attributable to the recombination of memorized patterns rather than authentic creative insight or novel synthesis.
WildWood: a new Random Forest algorithm
Sep 16, 2021
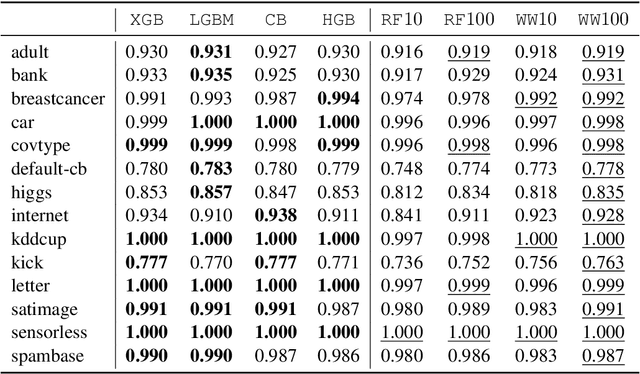
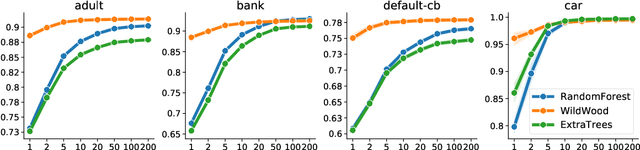
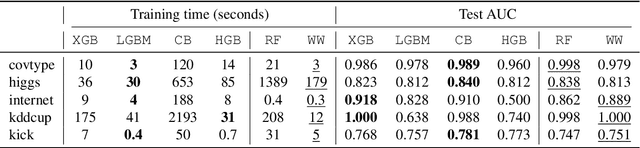
We introduce WildWood (WW), a new ensemble algorithm for supervised learning of Random Forest (RF) type. While standard RF algorithms use bootstrap out-of-bag samples to compute out-of-bag scores, WW uses these samples to produce improved predictions given by an aggregation of the predictions of all possible subtrees of each fully grown tree in the forest. This is achieved by aggregation with exponential weights computed over out-of-bag samples, that are computed exactly and very efficiently thanks to an algorithm called context tree weighting. This improvement, combined with a histogram strategy to accelerate split finding, makes WW fast and competitive compared with other well-established ensemble methods, such as standard RF and extreme gradient boosting algorithms.
About contrastive unsupervised representation learning for classification and its convergence
Dec 02, 2020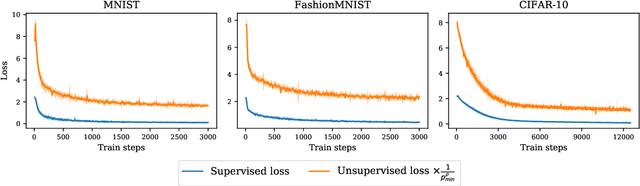
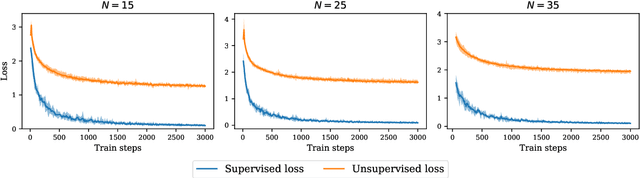
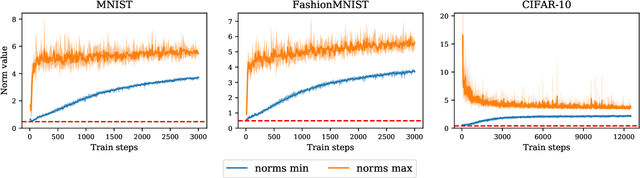
Contrastive representation learning has been recently proved to be very efficient for self-supervised training. These methods have been successfully used to train encoders which perform comparably to supervised training on downstream classification tasks. A few works have started to build a theoretical framework around contrastive learning in which guarantees for its performance can be proven. We provide extensions of these results to training with multiple negative samples and for multiway classification. Furthermore, we provide convergence guarantees for the minimization of the contrastive training error with gradient descent of an overparametrized deep neural encoder, and provide some numerical experiments that complement our theoretical findings
ZiMM: a deep learning model for long term adverse events with non-clinical claims data
Nov 13, 2019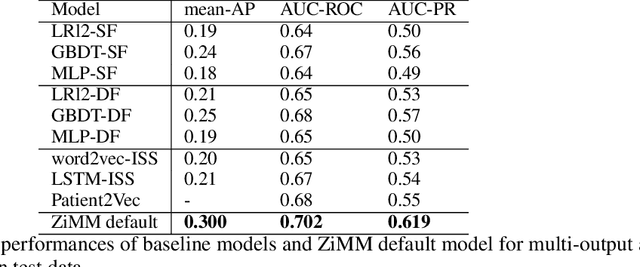
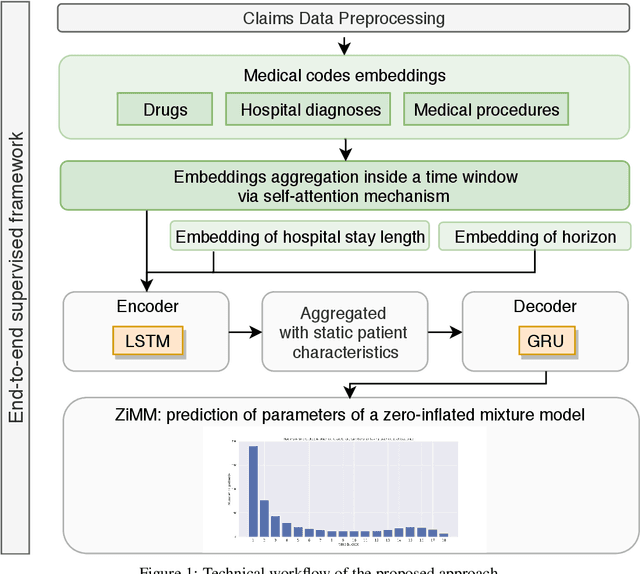
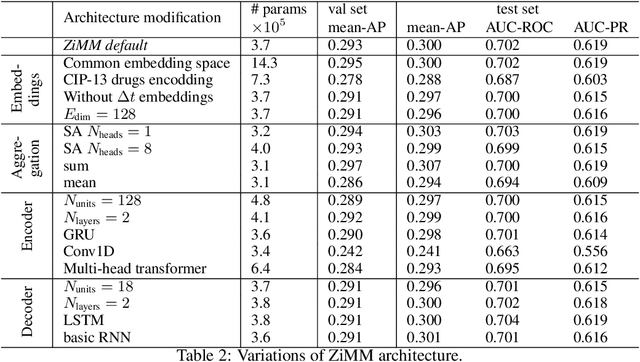
This paper considers the problem of modeling long-term adverse events following prostatic surgery performed on patients with urination problems, using the French national health insurance database (SNIIRAM), which is a non-clinical claims database built around healthcare reimbursements of more than 65 million people. This makes the problem particularly challenging compared to what could be done using clinical hospital data, albeit a much smaller sample, while we exploit here the claims of almost all French citizens diagnosed with prostatic problems (with between 1.5 and 5 years of history). We introduce a new model, called ZiMM (Zero-inflated Mixture of Multinomial distributions) to capture such long-term adverse events, and we build a deep-learning architecture on top of it to deal with the complex, highly heterogeneous and sparse patterns observable in such a large claims database. This architecture combines several ingredients: embedding layers for drugs, medical procedures, and diagnosis codes; embeddings aggregation through a self-attention mechanism; recurrent layers to encode the health pathways of patients before their surgery and a final decoder layer which outputs the ZiMM's parameters.