 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThree Approaches for Personalization with Applications to Federated Learning
Feb 25, 2020


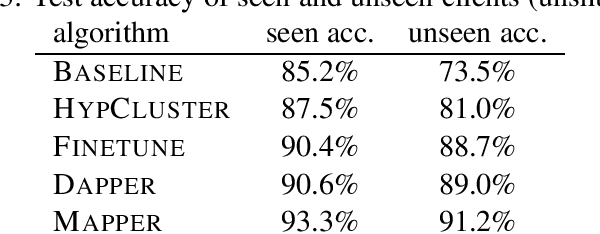
The standard objective in machine learning is to train a single model for all users. However, in many learning scenarios, such as cloud computing and federated learning, it is possible to learn one personalized model per user. In this work, we present a systematic learning-theoretic study of personalization. We propose and analyze three approaches: user clustering, data interpolation, and model interpolation. For all three approaches, we provide learning-theoretic guarantees and efficient algorithms for which we also demonstrate the performance empirically. All of our algorithms are model agnostic and work for any hypothesis class.
Prediction with Corrupted Expert Advice
Feb 24, 2020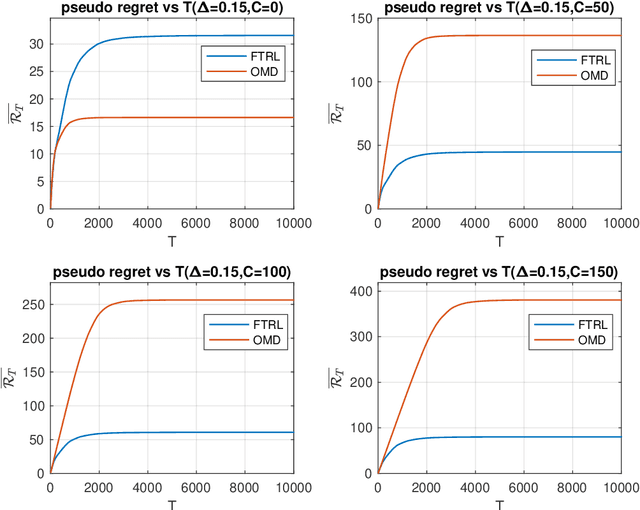
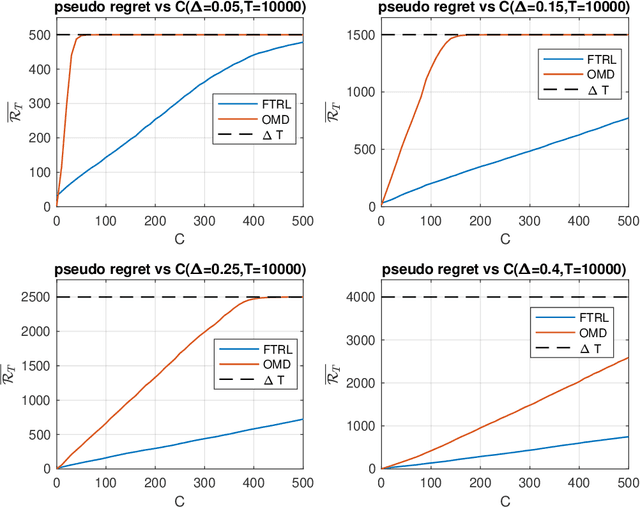
We revisit the fundamental problem of prediction with expert advice, in a setting where the environment is benign and generates losses stochastically, but the feedback observed by the learner is subject to a moderate adversarial corruption. We prove that a variant of the classical Multiplicative Weights algorithm with decreasing step sizes achieves constant regret in this setting and performs optimally in a wide range of environments, regardless of the magnitude of the injected corruption. Our results reveal a surprising disparity between the often comparable Follow the Regularized Leader (FTRL) and Online Mirror Descent (OMD) frameworks: we show that for experts in the corrupted stochastic regime, the regret performance of OMD is in fact strictly inferior to that of FTRL.
Near-optimal Regret Bounds for Stochastic Shortest Path
Feb 23, 2020Stochastic shortest path (SSP) is a well-known problem in planning and control, in which an agent has to reach a goal state in minimum total expected cost. In the learning formulation of the problem, the agent is unaware of the environment dynamics (i.e., the transition function) and has to repeatedly play for a given number of episodes while reasoning about the problem's optimal solution. Unlike other well-studied models in reinforcement learning (RL), the length of an episode is not predetermined (or bounded) and is influenced by the agent's actions. Recently, Tarbouriech et al. (2019) studied this problem in the context of regret minimization and provided an algorithm whose regret bound is inversely proportional to the square root of the minimum instantaneous cost. In this work we remove this dependence on the minimum cost---we give an algorithm that guarantees a regret bound of $\widetilde{O}(B_\star |S| \sqrt{|A| K})$, where $B_\star$ is an upper bound on the expected cost of the optimal policy, $S$ is the set of states, $A$ is the set of actions and $K$ is the number of episodes. We additionally show that any learning algorithm must have at least $\Omega(B_\star \sqrt{|S| |A| K})$ regret in the worst case.
Privately Learning Thresholds: Closing the Exponential Gap
Nov 22, 2019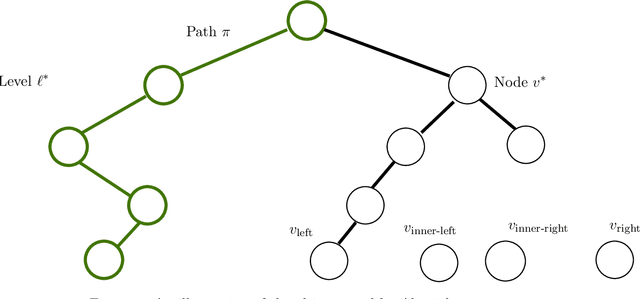
We study the sample complexity of learning threshold functions under the constraint of differential privacy. It is assumed that each labeled example in the training data is the information of one individual and we would like to come up with a generalizing hypothesis $h$ while guaranteeing differential privacy for the individuals. Intuitively, this means that any single labeled example in the training data should not have a significant effect on the choice of the hypothesis. This problem has received much attention recently; unlike the non-private case, where the sample complexity is independent of the domain size and just depends on the desired accuracy and confidence, for private learning the sample complexity must depend on the domain size $X$ (even for approximate differential privacy). Alon et al. (STOC 2019) showed a lower bound of $\Omega(\log^*|X|)$ on the sample complexity and Bun et al. (FOCS 2015) presented an approximate-private learner with sample complexity $\tilde{O}\left(2^{\log^*|X|}\right)$. In this work we reduce this gap significantly, almost settling the sample complexity. We first present a new upper bound (algorithm) of $\tilde{O}\left(\left(\log^*|X|\right)^2\right)$ on the sample complexity and then present an improved version with sample complexity $\tilde{O}\left(\left(\log^*|X|\right)^{1.5}\right)$. Our algorithm is constructed for the related interior point problem, where the goal is to find a point between the largest and smallest input elements. It is based on selecting an input-dependent hash function and using it to embed the database into a domain whose size is reduced logarithmically; this results in a new database, an interior point of which can be used to generate an interior point in the original database in a differentially private manner.
Apprenticeship Learning via Frank-Wolfe
Nov 20, 2019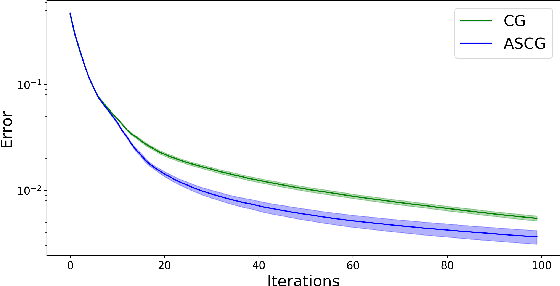
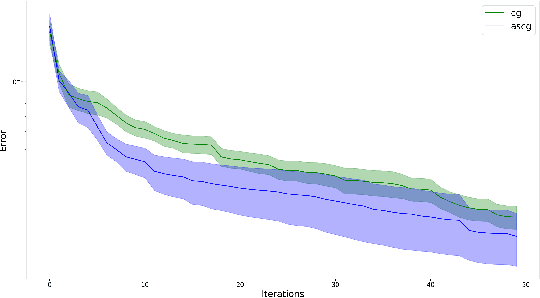
We consider the applications of the Frank-Wolfe (FW) algorithm for Apprenticeship Learning (AL). In this setting, we are given a Markov Decision Process (MDP) without an explicit reward function. Instead, we observe an expert that acts according to some policy, and the goal is to find a policy whose feature expectations are closest to those of the expert policy. We formulate this problem as finding the projection of the feature expectations of the expert on the feature expectations polytope -- the convex hull of the feature expectations of all the deterministic policies in the MDP. We show that this formulation is equivalent to the AL objective and that solving this problem using the FW algorithm is equivalent well-known Projection method of Abbeel and Ng (2004). This insight allows us to analyze AL with tools from convex optimization literature and derive tighter convergence bounds on AL. Specifically, we show that a variation of the FW method that is based on taking "away steps" achieves a linear rate of convergence when applied to AL and that a stochastic version of the FW algorithm can be used to avoid precise estimation of feature expectations. We also experimentally show that this version outperforms the FW baseline. To the best of our knowledge, this is the first work that shows linear convergence rates for AL.
Individual Regret in Cooperative Nonstochastic Multi-Armed Bandits
Jul 07, 2019We study agents communicating over an underlying network by exchanging messages, in order to optimize their individual regret in a common nonstochastic multi-armed bandit problem. We derive regret minimization algorithms that guarantee for each agent $v$ an individual expected regret of \[ \widetilde{O}\left(\sqrt{\left(1+\frac{K}{\left|\mathcal{N}\left(v\right)\right|}\right)T}\right), \] where $T$ is the number of time steps, $K$ is the number of actions and $\mathcal{N}\left(v\right)$ is the set of neighbors of agent $v$ in the communication graph. We present algorithms both for the case that the communication graph is known to all the agents, and for the case that the graph is unknown. When the graph is unknown, each agent knows only the set of its neighbors and an upper bound on the total number of agents. The individual regret between the models differs only by a logarithmic factor. Our work resolves an open problem from [Cesa-Bianchi et al., 2019b].
Thompson Sampling for Adversarial Bit Prediction
Jun 21, 2019We study the Thompson sampling algorithm in an adversarial setting, specifically, for adversarial bit prediction. We characterize the bit sequences with the smallest and largest expected regret. Among sequences of length $T$ with $k < \frac{T}{2}$ zeros, the sequences of largest regret consist of alternating zeros and ones followed by the remaining ones, and the sequence of smallest regret consists of ones followed by zeros. We also bound the regret of those sequences, the worse case sequences have regret $O(\sqrt{T})$ and the best case sequence have regret $O(1)$. We extend our results to a model where false positive and false negative errors have different weights. We characterize the sequences with largest expected regret in this generalized setting, and derive their regret bounds. We also show that there are sequences with $O(1)$ regret.
Graph-based Discriminators: Sample Complexity and Expressiveness
Jun 01, 2019A basic question in learning theory is to identify if two distributions are identical when we have access only to examples sampled from the distributions. This basic task is considered, for example, in the context of Generative Adversarial Networks (GANs), where a discriminator is trained to distinguish between a real-life distribution and a synthetic distribution. % Classically, we use a hypothesis class $H$ and claim that the two distributions are distinct if for some $h\in H$ the expected value on the two distributions is (significantly) different. Our starting point is the following fundamental problem: "is having the hypothesis dependent on more than a single random example beneficial". To address this challenge we define $k$-ary based discriminators, which have a family of Boolean $k$-ary functions $\mathcal{G}$. Each function $g\in \mathcal{G}$ naturally defines a hyper-graph, indicating whether a given hyper-edge exists. A function $g\in \mathcal{G}$ distinguishes between two distributions, if the expected value of $g$, on a $k$-tuple of i.i.d examples, on the two distributions is (significantly) different. We study the expressiveness of families of $k$-ary functions, compared to the classical hypothesis class $H$, which is $k=1$. We show a separation in expressiveness of $k+1$-ary versus $k$-ary functions. This demonstrate the great benefit of having $k\geq 2$ as distinguishers. For $k\geq 2$ we introduce a notion similar to the VC-dimension, and show that it controls the sample complexity. We proceed and provide upper and lower bounds as a function of our extended notion of VC-dimension.
Combinatorial Bandits with Full-Bandit Feedback: Sample Complexity and Regret Minimization
May 28, 2019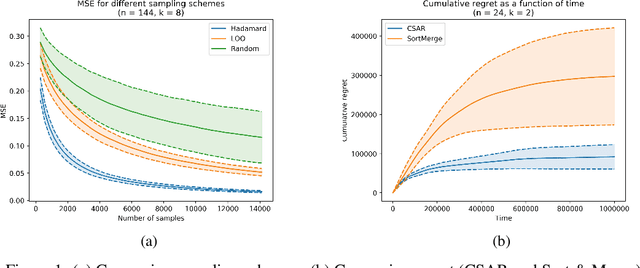
Combinatorial Bandits generalize multi-armed bandits, where k out of n arms are chosen at each round and the sum of the rewards is gained. We address the full-bandit feedback, in which the agent observes only the sum of rewards, in contrast to the semi-bandit feedback, in which the agent observes also the individual arms' rewards. We present the Combinatorial Successive Accepts and Rejects (CSAR) algorithm, which is a generalization of the SAR algorithm (Bubeck et al. 2013) for the combinatorial setting. Our main contribution is an efficient sampling scheme that uses Hadamard matrices in order to estimate accurately the individual arms' expected rewards. We discuss two variants of the algorithm, the first minimizes the sample complexity and the second minimizes the regret. For the sample complexity we also prove a matching lower bound that shows it is optimal. For the regret minimization, we prove a lower bound which is tight up to a factor of k. Finally, we run experiments and show that our algorithm outperforms other methods.
Repeated A/B Testing
May 28, 2019We study a setting in which a learner faces a sequence of A/B tests and has to make as many good decisions as possible within a given amount of time. Each A/B test $n$ is associated with an unknown (and potentially negative) reward $\mu_n \in [-1,1]$, drawn i.i.d. from an unknown and fixed distribution. For each A/B test $n$, the learner sequentially draws i.i.d. samples of a $\{-1,1\}$-valued random variable with mean $\mu_n$ until a halting criterion is met. The learner then decides to either accept the reward $\mu_n$ or to reject it and get zero instead. We measure the learner's performance as the sum of the expected rewards of the accepted $\mu_n$ divided by the total expected number of used time steps (which is different from the expected ratio between the total reward and the total number of used time steps). We design an algorithm and prove a data-dependent regret bound against any set of policies based on an arbitrary halting criterion and decision rule. Though our algorithm borrows ideas from multiarmed bandits, the two settings are significantly different and not directly comparable. In fact, the value of $\mu_n$ is never observed directly in our setting---unlike rewards in stochastic bandits. Moreover, the particular structure of our problem allows our regret bounds to be independent of the number of policies.