 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Challenges and Opportunities in Generative AI
Feb 28, 2024The field of deep generative modeling has grown rapidly and consistently over the years. With the availability of massive amounts of training data coupled with advances in scalable unsupervised learning paradigms, recent large-scale generative models show tremendous promise in synthesizing high-resolution images and text, as well as structured data such as videos and molecules. However, we argue that current large-scale generative AI models do not sufficiently address several fundamental issues that hinder their widespread adoption across domains. In this work, we aim to identify key unresolved challenges in modern generative AI paradigms that should be tackled to further enhance their capabilities, versatility, and reliability. By identifying these challenges, we aim to provide researchers with valuable insights for exploring fruitful research directions, thereby fostering the development of more robust and accessible generative AI solutions.
Position Paper: Bayesian Deep Learning in the Age of Large-Scale AI
Feb 06, 2024

In the current landscape of deep learning research, there is a predominant emphasis on achieving high predictive accuracy in supervised tasks involving large image and language datasets. However, a broader perspective reveals a multitude of overlooked metrics, tasks, and data types, such as uncertainty, active and continual learning, and scientific data, that demand attention. Bayesian deep learning (BDL) constitutes a promising avenue, offering advantages across these diverse settings. This paper posits that BDL can elevate the capabilities of deep learning. It revisits the strengths of BDL, acknowledges existing challenges, and highlights some exciting research avenues aimed at addressing these obstacles. Looking ahead, the discussion focuses on possible ways to combine large-scale foundation models with BDL to unlock their full potential.
Training Discrete Energy-Based Models with Energy Discrepancy
Jul 14, 2023



Training energy-based models (EBMs) on discrete spaces is challenging because sampling over such spaces can be difficult. We propose to train discrete EBMs with energy discrepancy (ED), a novel type of contrastive loss functional which only requires the evaluation of the energy function at data points and their perturbed counter parts, thus not relying on sampling strategies like Markov chain Monte Carlo (MCMC). Energy discrepancy offers theoretical guarantees for a broad class of perturbation processes of which we investigate three types: perturbations based on Bernoulli noise, based on deterministic transforms, and based on neighbourhood structures. We demonstrate their relative performance on lattice Ising models, binary synthetic data, and discrete image data sets.
Energy Discrepancies: A Score-Independent Loss for Energy-Based Models
Jul 12, 2023



Energy-based models are a simple yet powerful class of probabilistic models, but their widespread adoption has been limited by the computational burden of training them. We propose a novel loss function called Energy Discrepancy (ED) which does not rely on the computation of scores or expensive Markov chain Monte Carlo. We show that ED approaches the explicit score matching and negative log-likelihood loss under different limits, effectively interpolating between both. Consequently, minimum ED estimation overcomes the problem of nearsightedness encountered in score-based estimation methods, while also enjoying theoretical guarantees. Through numerical experiments, we demonstrate that ED learns low-dimensional data distributions faster and more accurately than explicit score matching or contrastive divergence. For high-dimensional image data, we describe how the manifold hypothesis puts limitations on our approach and demonstrate the effectiveness of energy discrepancy by training the energy-based model as a prior of a variational decoder model.
On the Identifiability of Markov Switching Models
May 26, 2023Identifiability of latent variable models has recently gained interest in terms of its applications to interpretability or out of distribution generalisation. In this work, we study identifiability of Markov Switching Models as a first step towards extending recent results to sequential latent variable models. We present identifiability conditions within first-order Markov dependency structures, and parametrise the transition distribution via non-linear Gaussians. Our experiments showcase the applicability of our approach for regime-dependent causal discovery and high-dimensional time series segmentation.
ESD: Expected Squared Difference as a Tuning-Free Trainable Calibration Measure
Mar 04, 2023



Studies have shown that modern neural networks tend to be poorly calibrated due to over-confident predictions. Traditionally, post-processing methods have been used to calibrate the model after training. In recent years, various trainable calibration measures have been proposed to incorporate them directly into the training process. However, these methods all incorporate internal hyperparameters, and the performance of these calibration objectives relies on tuning these hyperparameters, incurring more computational costs as the size of neural networks and datasets become larger. As such, we present Expected Squared Difference (ESD), a tuning-free (i.e., hyperparameter-free) trainable calibration objective loss, where we view the calibration error from the perspective of the squared difference between the two expectations. With extensive experiments on several architectures (CNNs, Transformers) and datasets, we demonstrate that (1) incorporating ESD into the training improves model calibration in various batch size settings without the need for internal hyperparameter tuning, (2) ESD yields the best-calibrated results compared with previous approaches, and (3) ESD drastically improves the computational costs required for calibration during training due to the absence of internal hyperparameter. The code is publicly accessible at https://github.com/hee-suk-yoon/ESD.
Calibrating Transformers via Sparse Gaussian Processes
Mar 04, 2023Transformer models have achieved profound success in prediction tasks in a wide range of applications in natural language processing, speech recognition and computer vision. Extending Transformer's success to safety-critical domains requires calibrated uncertainty estimation which remains under-explored. To address this, we propose Sparse Gaussian Process attention (SGPA), which performs Bayesian inference directly in the output space of multi-head attention blocks (MHAs) in transformer to calibrate its uncertainty. It replaces the scaled dot-product operation with a valid symmetric kernel and uses sparse Gaussian processes (SGP) techniques to approximate the posterior processes of MHA outputs. Empirically, on a suite of prediction tasks on text, images and graphs, SGPA-based Transformers achieve competitive predictive accuracy, while noticeably improving both in-distribution calibration and out-of-distribution robustness and detection.
Scalable Infomin Learning
Feb 21, 2023The task of infomin learning aims to learn a representation with high utility while being uninformative about a specified target, with the latter achieved by minimising the mutual information between the representation and the target. It has broad applications, ranging from training fair prediction models against protected attributes, to unsupervised learning with disentangled representations. Recent works on infomin learning mainly use adversarial training, which involves training a neural network to estimate mutual information or its proxy and thus is slow and difficult to optimise. Drawing on recent advances in slicing techniques, we propose a new infomin learning approach, which uses a novel proxy metric to mutual information. We further derive an accurate and analytically computable approximation to this proxy metric, thereby removing the need of constructing neural network-based mutual information estimators. Experiments on algorithmic fairness, disentangled representation learning and domain adaptation verify that our method can effectively remove unwanted information with limited time budget.
Markovian Gaussian Process Variational Autoencoders
Jul 12, 2022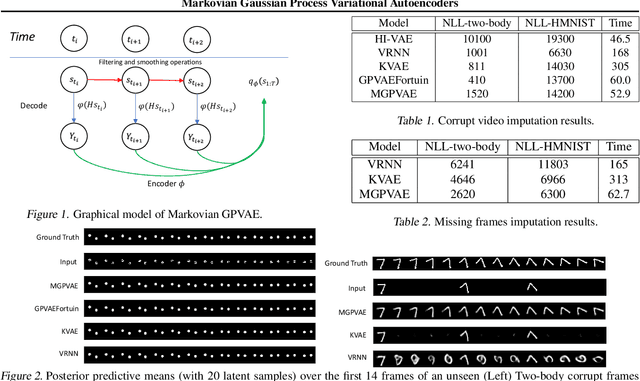
Deep generative models are widely used for modelling high-dimensional time series, such as video animations, audio and climate data. Sequential variational autoencoders have been successfully considered for many applications, with many variant models relying on discrete-time methods and recurrent neural networks (RNNs). On the other hand, continuous-time methods have recently gained attraction, especially in the context of irregularly-sampled time series, where they can better handle the data than discrete-time methods. One such class are Gaussian process variational autoencoders (GPVAEs), where the VAE prior is set as a Gaussian process (GPs), allowing inductive biases to be explicitly encoded via the kernel function and interpretability of the latent space. However, a major limitation of GPVAEs is that it inherits the same cubic computational cost as GPs. In this work, we leverage the equivalent discrete state space representation of Markovian GPs to enable a linear-time GP solver via Kalman filtering and smoothing. We show via corrupt and missing frames tasks that our method performs favourably, especially on the latter where it outperforms RNN-based models.
Repairing Neural Networks by Leaving the Right Past Behind
Jul 11, 2022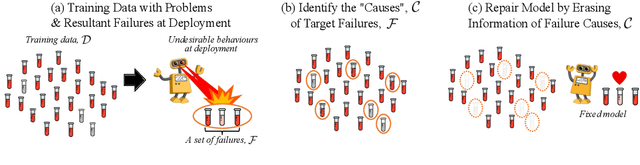
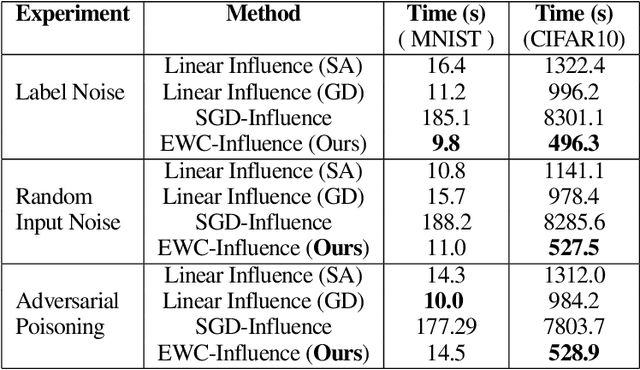
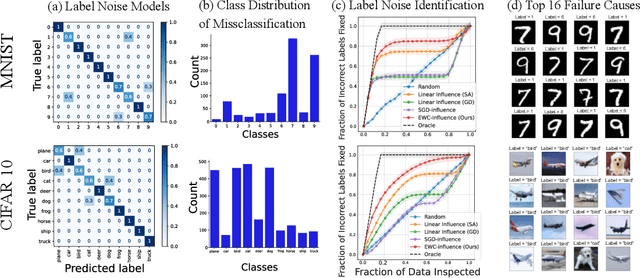
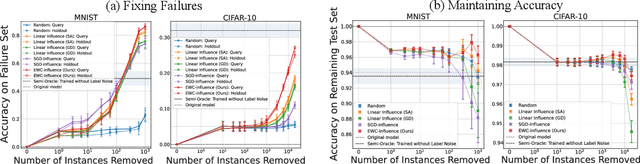
Prediction failures of machine learning models often arise from deficiencies in training data, such as incorrect labels, outliers, and selection biases. However, such data points that are responsible for a given failure mode are generally not known a priori, let alone a mechanism for repairing the failure. This work draws on the Bayesian view of continual learning, and develops a generic framework for both, identifying training examples that have given rise to the target failure, and fixing the model through erasing information about them. This framework naturally allows leveraging recent advances in continual learning to this new problem of model repairment, while subsuming the existing works on influence functions and data deletion as specific instances. Experimentally, the proposed approach outperforms the baselines for both identification of detrimental training data and fixing model failures in a generalisable manner.