 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvolving Three Dimension (3D) Abstract Art: Fitting Concepts by Language
Apr 24, 2023Computational creativity has contributed heavily to abstract art in modern era, allowing artists to create high quality, abstract two dimension (2D) arts with a high level of controllability and expressibility. However, even with computational approaches that have promising result in making concrete 3D art, computationally addressing abstract 3D art with high-quality and controllability remains an open question. To fill this gap, we propose to explore computational creativity in making abstract 3D art by bridging evolution strategies (ES) and 3D rendering through customizable parameterization of scenes. We demonstrate that our approach is capable of placing semi-transparent triangles in 3D scenes that, when viewed from specified angles, render into films that look like artists' specification expressed in natural language. This provides a new way for the artist to easily express creativity ideas for abstract 3D art. The supplementary material, which contains code, animation for all figures, and more examples, is here: https://es3dart.github.io/
DEIR: Efficient and Robust Exploration through Discriminative-Model-Based Episodic Intrinsic Rewards
Apr 21, 2023



Exploration is a fundamental aspect of reinforcement learning (RL), and its effectiveness crucially decides the performance of RL algorithms, especially when facing sparse extrinsic rewards. Recent studies showed the effectiveness of encouraging exploration with intrinsic rewards estimated from novelty in observations. However, there is a gap between the novelty of an observation and an exploration in general, because the stochasticity in the environment as well as the behavior of an agent may affect the observation. To estimate exploratory behaviors accurately, we propose DEIR, a novel method where we theoretically derive an intrinsic reward from a conditional mutual information term that principally scales with the novelty contributed by agent explorations, and materialize the reward with a discriminative forward model. We conduct extensive experiments in both standard and hardened exploration games in MiniGrid to show that DEIR quickly learns a better policy than baselines. Our evaluations in ProcGen demonstrate both generalization capabilities and the general applicability of our intrinsic reward.
Simultaneous Multiple-Prompt Guided Generation Using Differentiable Optimal Transport
Apr 18, 2022


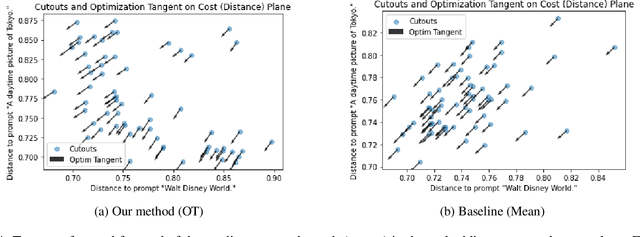
Recent advances in deep learning, such as powerful generative models and joint text-image embeddings, have provided the computational creativity community with new tools, opening new perspectives for artistic pursuits. Text-to-image synthesis approaches that operate by generating images from text cues provide a case in point. These images are generated with a latent vector that is progressively refined to agree with text cues. To do so, patches are sampled within the generated image, and compared with the text prompts in the common text-image embedding space; The latent vector is then updated, using gradient descent, to reduce the mean (average) distance between these patches and text cues. While this approach provides artists with ample freedom to customize the overall appearance of images, through their choice in generative models, the reliance on a simple criterion (mean of distances) often causes mode collapse: The entire image is drawn to the average of all text cues, thereby losing their diversity. To address this issue, we propose using matching techniques found in the optimal transport (OT) literature, resulting in images that are able to reflect faithfully a wide diversity of prompts. We provide numerous illustrations showing that OT avoids some of the pitfalls arising from estimating vectors with mean distances, and demonstrate the capacity of our proposed method to perform better in experiments, qualitatively and quantitatively.
EvoJAX: Hardware-Accelerated Neuroevolution
Feb 10, 2022

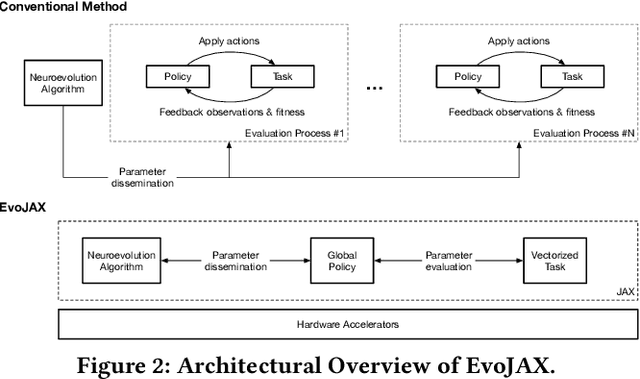
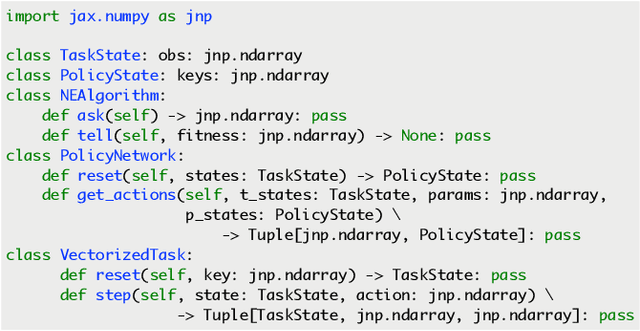
Evolutionary computation has been shown to be a highly effective method for training neural networks, particularly when employed at scale on CPU clusters. Recent work have also showcased their effectiveness on hardware accelerators, such as GPUs, but so far such demonstrations are tailored for very specific tasks, limiting applicability to other domains. We present EvoJAX, a scalable, general purpose, hardware-accelerated neuroevolution toolkit. Building on top of the JAX library, our toolkit enables neuroevolution algorithms to work with neural networks running in parallel across multiple TPU/GPUs. EvoJAX achieves very high performance by implementing the evolution algorithm, neural network and task all in NumPy, which is compiled just-in-time to run on accelerators. We provide extensible examples of EvoJAX for a wide range of tasks, including supervised learning, reinforcement learning and generative art. Since EvoJAX can find solutions to most of these tasks within minutes on a single accelerator, compared to hours or days when using CPUs, we believe our toolkit can significantly shorten the iteration time of conducting experiments for researchers working with evolutionary computation. Our project is available at https://github.com/google/evojax
Optimal Transport Tools : A JAX Toolbox for all things Wasserstein
Jan 28, 2022
Optimal transport tools (OTT-JAX) is a Python toolbox that can solve optimal transport problems between point clouds and histograms. The toolbox builds on various JAX features, such as automatic and custom reverse mode differentiation, vectorization, just-in-time compilation and accelerators support. The toolbox covers elementary computations, such as the resolution of the regularized OT problem, and more advanced extensions, such as barycenters, Gromov-Wasserstein, low-rank solvers, estimation of convex maps, differentiable generalizations of quantiles and ranks, and approximate OT between Gaussian mixtures. The toolbox code is available at \texttt{https://github.com/ott-jax/ott}
Modern Evolution Strategies for Creativity: Fitting Concrete Images and Abstract Concepts
Sep 18, 2021
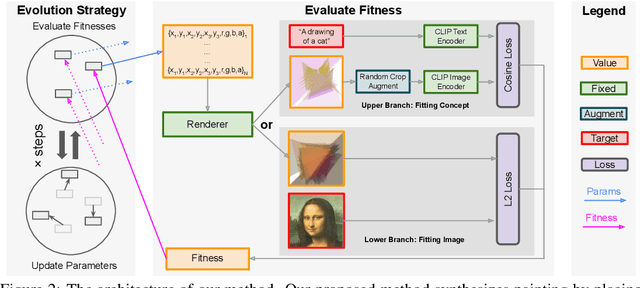


Evolutionary algorithms have been used in the digital art scene since the 1970s. A popular application of genetic algorithms is to optimize the procedural placement of vector graphic primitives to resemble a given painting. In recent years, deep learning-based approaches have also been proposed to generate procedural drawings, which can be optimized using gradient descent. In this work, we revisit the use of evolutionary algorithms for computational creativity. We find that modern evolution strategies (ES) algorithms, when tasked with the placement of shapes, offer large improvements in both quality and efficiency compared to traditional genetic algorithms, and even comparable to gradient-based methods. We demonstrate that ES is also well suited at optimizing the placement of shapes to fit the CLIP model, and can produce diverse, distinct geometric abstractions that are aligned with human interpretation of language. Videos and demo: https://es-clip.github.io/
Ukiyo-e Analysis and Creativity with Attribute and Geometry Annotation
Jun 04, 2021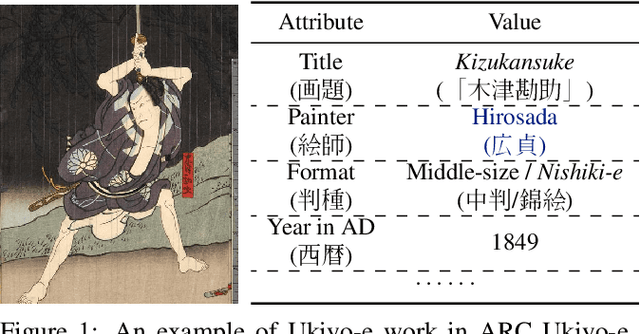


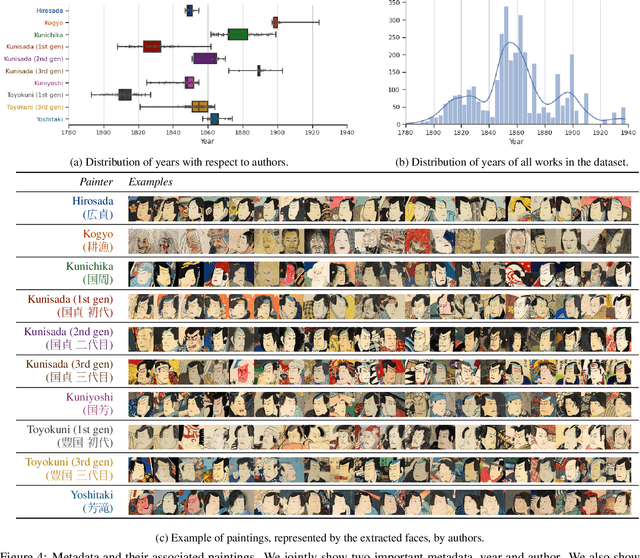
The study of Ukiyo-e, an important genre of pre-modern Japanese art, focuses on the object and style like other artwork researches. Such study has benefited from the renewed interest by the machine learning community in culturally important topics, leading to interdisciplinary works including collections of images, quantitative approaches, and machine learning-based creativities. They, however, have several drawbacks, and it remains challenging to integrate these works into a comprehensive view. To bridge this gap, we propose a holistic approach We first present a large-scale Ukiyo-e dataset with coherent semantic labels and geometric annotations, then show its value in a quantitative study of Ukiyo-e paintings' object using these labels and annotations. We further demonstrate the machine learning methods could help style study through soft color decomposition of Ukiyo-e, and finally provides joint insights into object and style by composing sketches and colors using colorization. Dataset available at https://github.com/rois-codh/arc-ukiyoe-faces
InstantEmbedding: Efficient Local Node Representations
Oct 14, 2020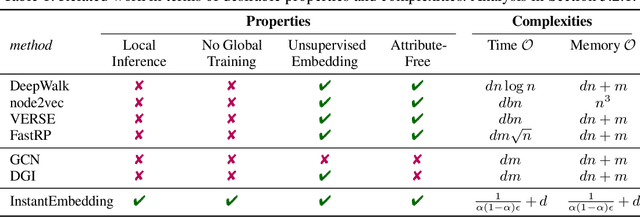
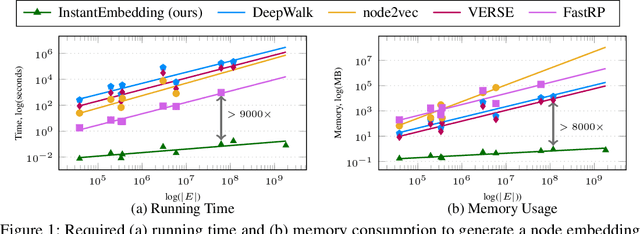
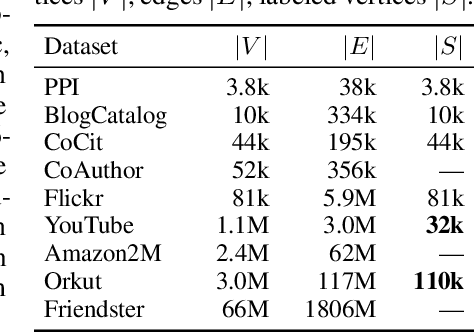
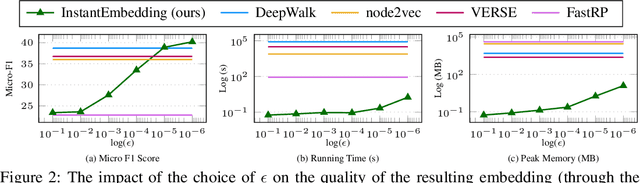
In this paper, we introduce InstantEmbedding, an efficient method for generating single-node representations using local PageRank computations. We theoretically prove that our approach produces globally consistent representations in sublinear time. We demonstrate this empirically by conducting extensive experiments on real-world datasets with over a billion edges. Our experiments confirm that InstantEmbedding requires drastically less computation time (over 9,000 times faster) and less memory (by over 8,000 times) to produce a single node's embedding than traditional methods including DeepWalk, node2vec, VERSE, and FastRP. We also show that our method produces high quality representations, demonstrating results that meet or exceed the state of the art for unsupervised representation learning on tasks like node classification and link prediction.
KaoKore: A Pre-modern Japanese Art Facial Expression Dataset
Feb 20, 2020
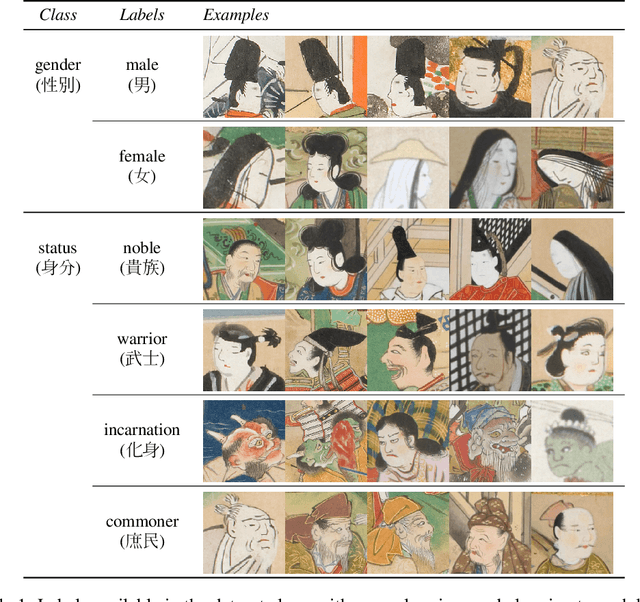

From classifying handwritten digits to generating strings of text, the datasets which have received long-time focus from the machine learning community vary greatly in their subject matter. This has motivated a renewed interest in building datasets which are socially and culturally relevant, so that algorithmic research may have a more direct and immediate impact on society. One such area is in history and the humanities, where better and relevant machine learning models can accelerate research across various fields. To this end, newly released benchmarks and models have been proposed for transcribing historical Japanese cursive writing, yet for the field as a whole using machine learning for historical Japanese artworks still remains largely uncharted. To bridge this gap, in this work we propose a new dataset KaoKore which consists of faces extracted from pre-modern Japanese artwork. We demonstrate its value as both a dataset for image classification as well as a creative and artistic dataset, which we explore using generative models. Dataset available at https://github.com/rois-codh/kaokore
Fast and Accurate Network Embeddings via Very Sparse Random Projection
Aug 30, 2019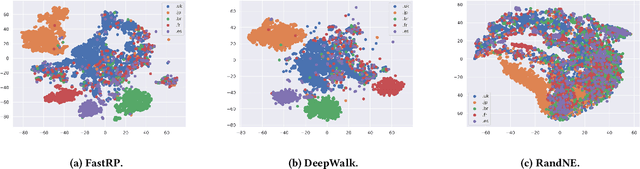

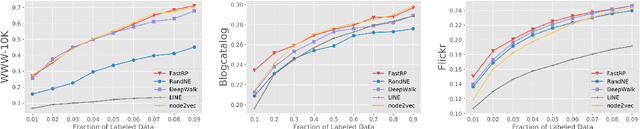
We present FastRP, a scalable and performant algorithm for learning distributed node representations in a graph. FastRP is over 4,000 times faster than state-of-the-art methods such as DeepWalk and node2vec, while achieving comparable or even better performance as evaluated on several real-world networks on various downstream tasks. We observe that most network embedding methods consist of two components: construct a node similarity matrix and then apply dimension reduction techniques to this matrix. We show that the success of these methods should be attributed to the proper construction of this similarity matrix, rather than the dimension reduction method employed. FastRP is proposed as a scalable algorithm for network embeddings. Two key features of FastRP are: 1) it explicitly constructs a node similarity matrix that captures transitive relationships in a graph and normalizes matrix entries based on node degrees; 2) it utilizes very sparse random projection, which is a scalable optimization-free method for dimension reduction. An extra benefit from combining these two design choices is that it allows the iterative computation of node embeddings so that the similarity matrix need not be explicitly constructed, which further speeds up FastRP. FastRP is also advantageous for its ease of implementation, parallelization and hyperparameter tuning. The source code is available at https://github.com/GTmac/FastRP.