 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Homophily Disparity in Graph Anomaly Detection: A Scalable and Adaptive Approach
Mar 09, 2026Graph anomaly detection (GAD) aims to identify nodes that deviate from normal patterns in structure or features. While recent GNN-based approaches have advanced this task, they struggle with two major challenges: 1) homophily disparity, where nodes exhibit varying homophily at both class and node levels; and 2) limited scalability, as many methods rely on costly whole-graph operations. To address them, we propose SAGAD, a Scalable and Adaptive framework for GAD. SAGAD precomputes multi-hop embeddings and applies reparameterized Chebyshev filters to extract low- and high-frequency information, enabling efficient training and capturing both homophilic and heterophilic patterns. To mitigate node-level homophily disparity, we introduce an Anomaly Context-Aware Adaptive Fusion, which adaptively fuses low- and high-pass embeddings using fusion coefficients conditioned on Rayleigh Quotient-guided anomalous subgraph structures for each node. To alleviate class-level disparity, we design a Frequency Preference Guidance Loss, which encourages anomalies to preserve more high-frequency information than normal nodes. SAGAD supports mini-batch training, achieves linear time and space complexity, and drastically reduces memory usage on large-scale graphs. Theoretically, SAGAD ensures asymptotic linear separability between normal and abnormal nodes under mild conditions. Extensive experiments on 10 benchmarks confirm SAGAD's superior accuracy and scalability over state-of-the-art methods.
Learning Hierarchical Knowledge in Text-Rich Networks with Taxonomy-Informed Representation Learning
Mar 09, 2026Hierarchical knowledge structures are ubiquitous across real-world domains and play a vital role in organizing information from coarse to fine semantic levels. While such structures have been widely used in taxonomy systems, biomedical ontologies, and retrieval-augmented generation, their potential remains underexplored in the context of Text-Rich Networks (TRNs), where each node contains rich textual content and edges encode semantic relationships. Existing methods for learning on TRNs often focus on flat semantic modeling, overlooking the inherent hierarchical semantics embedded in textual documents. To this end, we propose TIER (Hierarchical \textbf{T}axonomy-\textbf{I}nformed R\textbf{E}presentation Learning on Text-\textbf{R}ich Networks), which first constructs an implicit hierarchical taxonomy and then integrates it into the learned node representations. Specifically, TIER employs similarity-guided contrastive learning to build a clustering-friendly embedding space, upon which it performs hierarchical K-Means followed by LLM-powered clustering refinement to enable semantically coherent taxonomy construction. Leveraging the resulting taxonomy, TIER introduces a cophenetic correlation coefficient-based regularization loss to align the learned embeddings with the hierarchical structure. By learning representations that respect both fine-grained and coarse-grained semantics, TIER enables more interpretable and structured modeling of real-world TRNs. We demonstrate that our approach significantly outperforms existing methods on multiple datasets across diverse domains, highlighting the importance of hierarchical knowledge learning for TRNs.
Diverse Behavior Is What Game AI Needs: Generating Varied Human-Like Playing Styles Using Evolutionary Multi-Objective Deep Reinforcement Learning
Oct 20, 2019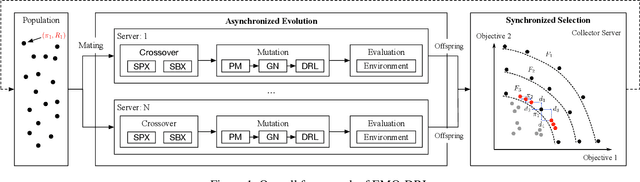
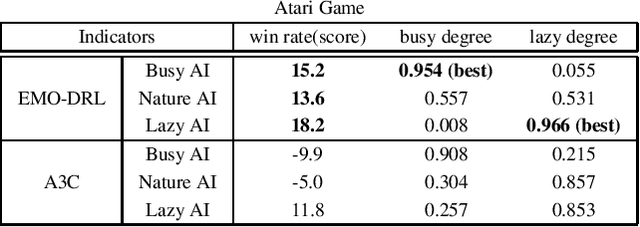
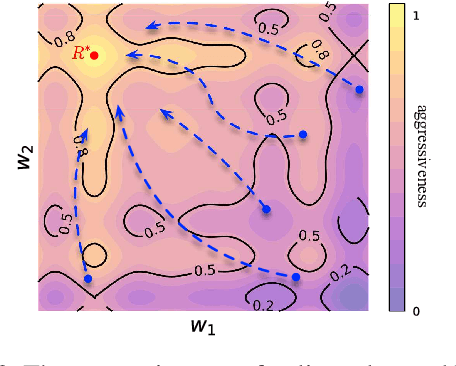
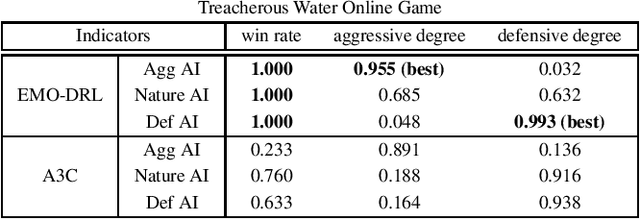
Designing artificial intelligence for games (Game AI) has been long recognized as a notoriously challenging task in the game industry, as it mainly relies on manual design, requiring plenty of domain knowledge. More frustratingly, even spending a lot of effort, a satisfying Game AI is still hard to achieve by manual design due to the almost infinite search space. The recent success of deep reinforcement learning (DRL) sheds light on advancing automated game designing, significantly relaxing human competitive intelligent support. However, existing DRL algorithms mostly focus on training a Game AI to win the game rather than the way it wins (style). To bridge the gap, we introduce EMO-DRL, an end-to-end game design framework, leveraging evolutionary algorithm, DRL and multi-objective optimization (MOO) to perform intelligent and automatic game design. Firstly, EMO-DRL proposes style-oriented learning to bypass manual reward shaping in DRL and directly learns a Game AI with an expected style in an end-to-end fashion. On this basis, the prioritized multi-objective optimization is introduced to achieve more diverse, nature and human-like Game AI. Large-scale evaluations on an Atari game and a commercial massively multiplayer online game are conducted. The results demonstrate that EMO-DRL, compared to existing algorithms, achieve better game designs in an intelligent and automatic way.