 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Seer: Online Context Learning for Fast Synchronous LLM Reinforcement Learning
Nov 18, 2025



Reinforcement Learning (RL) has become critical for advancing modern Large Language Models (LLMs), yet existing synchronous RL systems face severe performance bottlenecks. The rollout phase, which dominates end-to-end iteration time, suffers from substantial long-tail latency and poor resource utilization due to inherent workload imbalance. We present Seer, a novel online context learning system that addresses these challenges by exploiting previously overlooked similarities in output lengths and generation patterns among requests sharing the same prompt. Seer introduces three key techniques: divided rollout for dynamic load balancing, context-aware scheduling, and adaptive grouped speculative decoding. Together, these mechanisms substantially reduce long-tail latency and improve resource efficiency during rollout. Evaluations on production-grade RL workloads demonstrate that Seer improves end-to-end rollout throughput by 74% to 97% and reduces long-tail latency by 75% to 93% compared to state-of-the-art synchronous RL systems, significantly accelerating RL training iterations.
MergeMoE: Efficient Compression of MoE Models via Expert Output Merging
Oct 16, 2025The Mixture-of-Experts (MoE) technique has proven to be a promising solution to efficiently scale the model size, which has been widely applied in recent LLM advancements. However, the substantial memory overhead of MoE models has made their compression an important research direction. In this work, we provide a theoretical analysis of expert merging, a recently proposed technique for compressing MoE models. Rather than interpreting expert merging from the conventional perspective of parameter aggregation, we approach it from the perspective of merging experts' outputs. Our key insight is that the merging process can be interpreted as inserting additional matrices into the forward computation, which naturally leads to an optimization formulation. Building on this analysis, we introduce MergeMoE, a method that leverages mathematical optimization to construct the compression matrices. We evaluate MergeMoE on multiple MoE models and show that our algorithm consistently outperforms the baselines with the same compression ratios.
Kimi K2: Open Agentic Intelligence
Jul 28, 2025



We introduce Kimi K2, a Mixture-of-Experts (MoE) large language model with 32 billion activated parameters and 1 trillion total parameters. We propose the MuonClip optimizer, which improves upon Muon with a novel QK-clip technique to address training instability while enjoying the advanced token efficiency of Muon. Based on MuonClip, K2 was pre-trained on 15.5 trillion tokens with zero loss spike. During post-training, K2 undergoes a multi-stage post-training process, highlighted by a large-scale agentic data synthesis pipeline and a joint reinforcement learning (RL) stage, where the model improves its capabilities through interactions with real and synthetic environments. Kimi K2 achieves state-of-the-art performance among open-source non-thinking models, with strengths in agentic capabilities. Notably, K2 obtains 66.1 on Tau2-Bench, 76.5 on ACEBench (En), 65.8 on SWE-Bench Verified, and 47.3 on SWE-Bench Multilingual -- surpassing most open and closed-sourced baselines in non-thinking settings. It also exhibits strong capabilities in coding, mathematics, and reasoning tasks, with a score of 53.7 on LiveCodeBench v6, 49.5 on AIME 2025, 75.1 on GPQA-Diamond, and 27.1 on OJBench, all without extended thinking. These results position Kimi K2 as one of the most capable open-source large language models to date, particularly in software engineering and agentic tasks. We release our base and post-trained model checkpoints to facilitate future research and applications of agentic intelligence.
CAFE: Towards Compact, Adaptive, and Fast Embedding for Large-scale Recommendation Models
Dec 06, 2023



Recently, the growing memory demands of embedding tables in Deep Learning Recommendation Models (DLRMs) pose great challenges for model training and deployment. Existing embedding compression solutions cannot simultaneously meet three key design requirements: memory efficiency, low latency, and adaptability to dynamic data distribution. This paper presents CAFE, a Compact, Adaptive, and Fast Embedding compression framework that addresses the above requirements. The design philosophy of CAFE is to dynamically allocate more memory resources to important features (called hot features), and allocate less memory to unimportant ones. In CAFE, we propose a fast and lightweight sketch data structure, named HotSketch, to capture feature importance and report hot features in real time. For each reported hot feature, we assign it a unique embedding. For the non-hot features, we allow multiple features to share one embedding by using hash embedding technique. Guided by our design philosophy, we further propose a multi-level hash embedding framework to optimize the embedding tables of non-hot features. We theoretically analyze the accuracy of HotSketch, and analyze the model convergence against deviation. Extensive experiments show that CAFE significantly outperforms existing embedding compression methods, yielding 3.92% and 3.68% superior testing AUC on Criteo Kaggle dataset and CriteoTB dataset at a compression ratio of 10000x. The source codes of CAFE are available at GitHub.
Novel tile segmentation scheme for omnidirectional video
Mar 10, 2021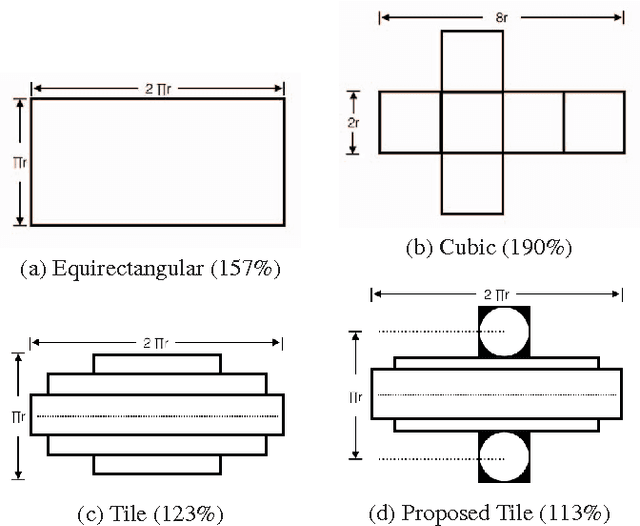
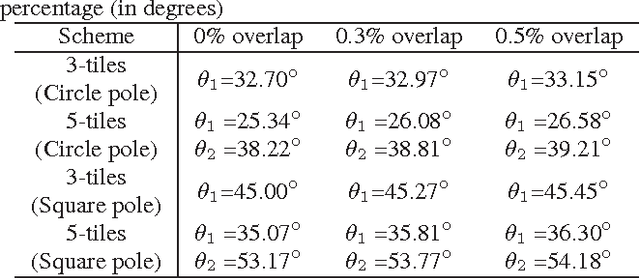
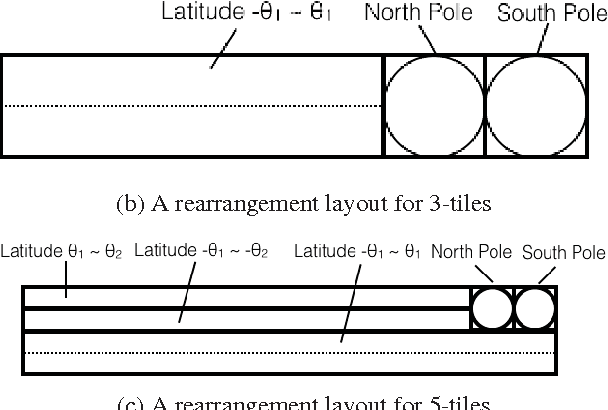
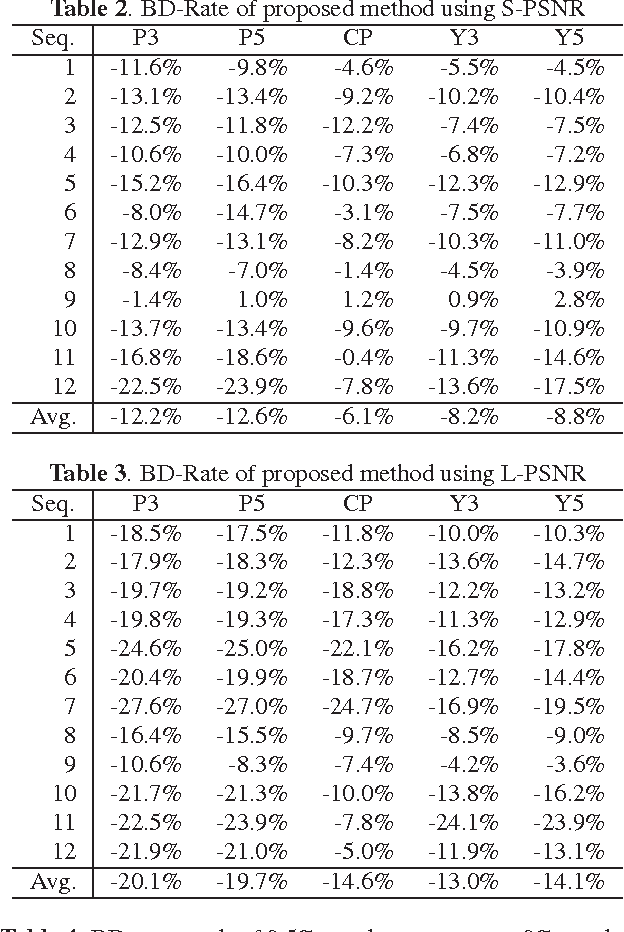
Regular omnidirectional video encoding technics use map projection to flatten a scene from a spherical shape into one or several 2D shapes. Common projection methods including equirectangular and cubic projection have varying levels of interpolation that create a large number of non-information-carrying pixels that lead to wasted bitrate. In this paper, we propose a tile based omnidirectional video segmentation scheme which can save up to 28% of pixel area and 20% of BD-rate averagely compared to the traditional equirectangular projection based approach.