 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInhomogeneous graph trend filtering via a l2,0 cardinality penalty
Apr 11, 2023



We study estimation of piecewise smooth signals over a graph. We propose a $\ell_{2,0}$-norm penalized Graph Trend Filtering (GTF) model to estimate piecewise smooth graph signals that exhibits inhomogeneous levels of smoothness across the nodes. We prove that the proposed GTF model is simultaneously a k-means clustering on the signal over the nodes and a minimum graph cut on the edges of the graph, where the clustering and the cut share the same assignment matrix. We propose two methods to solve the proposed GTF model: a spectral decomposition method and a method based on simulated annealing. In the experiment on synthetic and real-world datasets, we show that the proposed GTF model has a better performances compared with existing approaches on the tasks of denoising, support recovery and semi-supervised classification. We also show that the proposed GTF model can be solved more efficiently than existing models for the dataset with a large edge set.
Calibrated One-class Classification for Unsupervised Time Series Anomaly Detection
Jul 25, 2022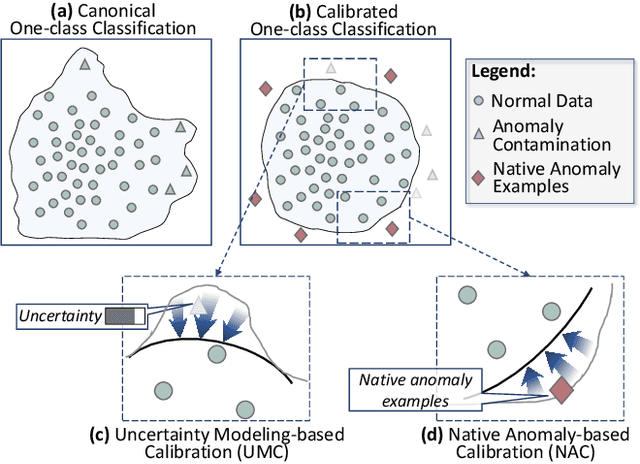
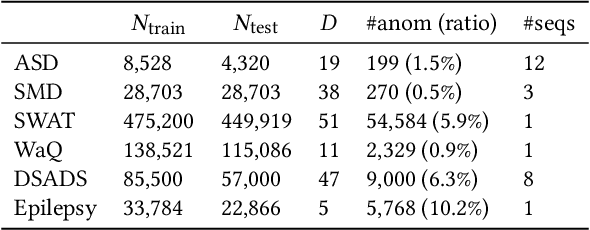
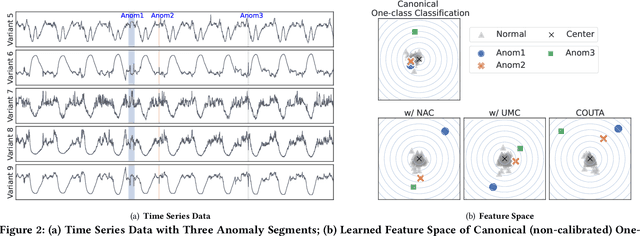
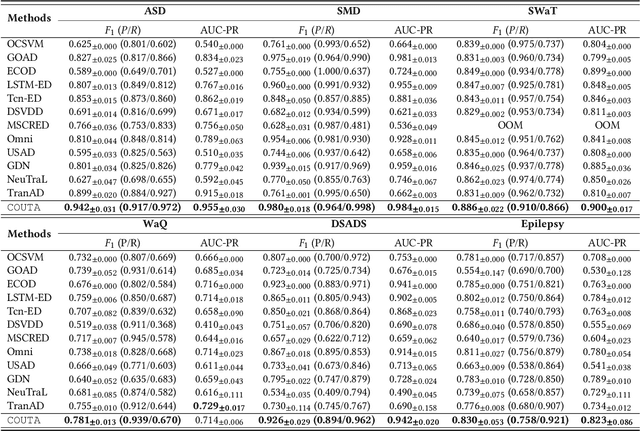
Unsupervised time series anomaly detection is instrumental in monitoring and alarming potential faults of target systems in various domains. Current state-of-the-art time series anomaly detectors mainly focus on devising advanced neural network structures and new reconstruction/prediction learning objectives to learn data normality (normal patterns and behaviors) as accurately as possible. However, these one-class learning methods can be deceived by unknown anomalies in the training data (i.e., anomaly contamination). Further, their normality learning also lacks knowledge about the anomalies of interest. Consequently, they often learn a biased, inaccurate normality boundary. This paper proposes a novel one-class learning approach, named calibrated one-class classification, to tackle this problem. Our one-class classifier is calibrated in two ways: (1) by adaptively penalizing uncertain predictions, which helps eliminate the impact of anomaly contamination while accentuating the predictions that the one-class model is confident in, and (2) by discriminating the normal samples from native anomaly examples that are generated to simulate genuine time series abnormal behaviors on the basis of original data. These two calibrations result in contamination-tolerant, anomaly-informed one-class learning, yielding a significantly improved normality modeling. Extensive experiments on six real-world datasets show that our model substantially outperforms twelve state-of-the-art competitors and obtains 6% - 31% F1 score improvement. The source code is available at \url{https://github.com/xuhongzuo/couta}.
CDNet: Contrastive Disentangled Network for Fine-Grained Image Categorization of Ocular B-Scan Ultrasound
Jun 17, 2022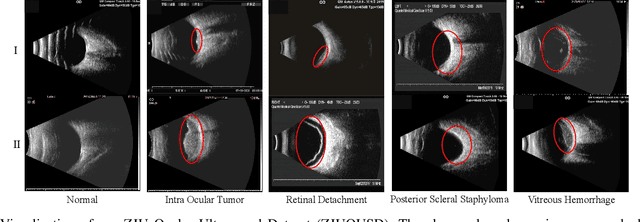
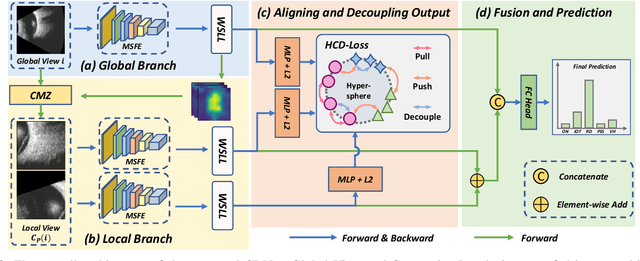

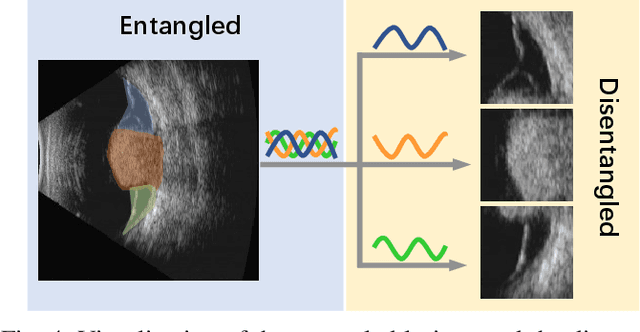
Precise and rapid categorization of images in the B-scan ultrasound modality is vital for diagnosing ocular diseases. Nevertheless, distinguishing various diseases in ultrasound still challenges experienced ophthalmologists. Thus a novel contrastive disentangled network (CDNet) is developed in this work, aiming to tackle the fine-grained image categorization (FGIC) challenges of ocular abnormalities in ultrasound images, including intraocular tumor (IOT), retinal detachment (RD), posterior scleral staphyloma (PSS), and vitreous hemorrhage (VH). Three essential components of CDNet are the weakly-supervised lesion localization module (WSLL), contrastive multi-zoom (CMZ) strategy, and hyperspherical contrastive disentangled loss (HCD-Loss), respectively. These components facilitate feature disentanglement for fine-grained recognition in both the input and output aspects. The proposed CDNet is validated on our ZJU Ocular Ultrasound Dataset (ZJUOUSD), consisting of 5213 samples. Furthermore, the generalization ability of CDNet is validated on two public and widely-used chest X-ray FGIC benchmarks. Quantitative and qualitative results demonstrate the efficacy of our proposed CDNet, which achieves state-of-the-art performance in the FGIC task. Code is available at: https://github.com/ZeroOneGame/CDNet-for-OUS-FGIC .
Deep Isolation Forest for Anomaly Detection
Jun 14, 2022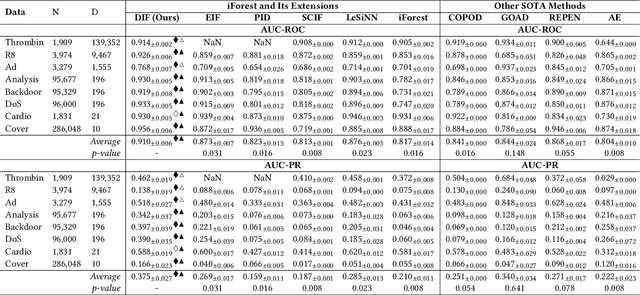
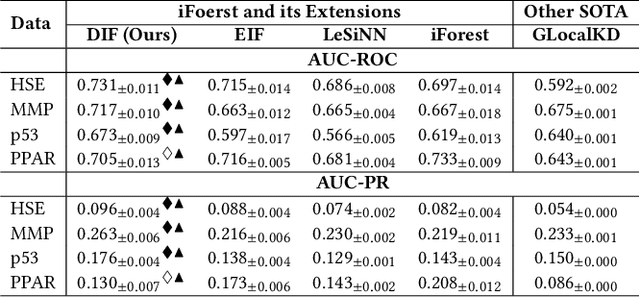
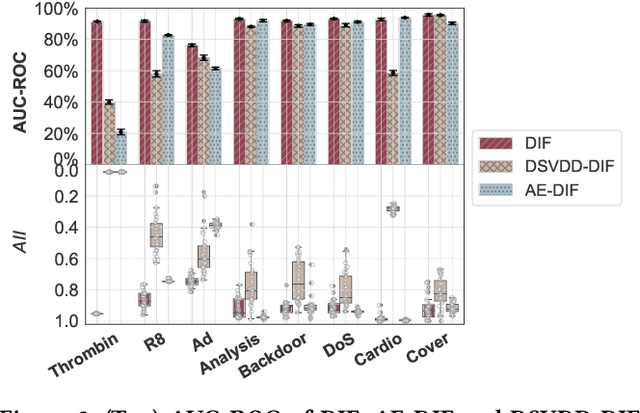
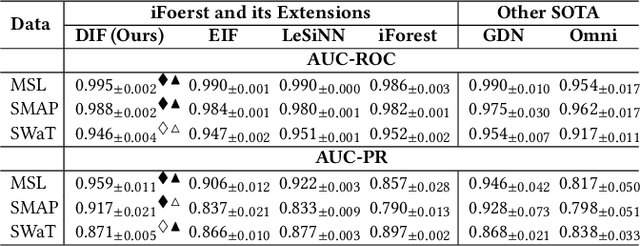
Isolation forest (iForest) has been emerging as arguably the most popular anomaly detector in recent years. It iteratively performs axis-parallel data space partition in a tree structure to isolate deviated data objects from the other data, with the isolation difficulty of the objects defined as anomaly scores. iForest shows effective performance across popular dataset benchmarks, but its axis-parallel-based linear data partition is ineffective in handling hard anomalies in high-dimensional/non-linear-separable data space, and even worse, it leads to a notorious algorithmic bias that assigns unexpectedly large anomaly scores to artefact regions. There have been several extensions of iForest, but they still focus on linear data partition, failing to effectively isolate those hard anomalies. This paper introduces a novel extension of iForest, deep isolation forest. Our method offers a comprehensive isolation method that can arbitrarily partition the data at any random direction and angle on subspaces of any size, effectively avoiding the algorithmic bias in the linear partition. Further, it requires only randomly initialised neural networks (i.e., no optimisation is required in our method) to ensure the freedom of the partition. In doing so, desired randomness and diversity in both random network-based representations and random partition-based isolation can be fully leveraged to significantly enhance the isolation ensemble-based anomaly detection. Also, our approach offers a data-type-agnostic anomaly detection solution. It is versatile to detect anomalies in different types of data by simply plugging in corresponding randomly initialised neural networks in the feature mapping. Extensive empirical results on a large collection of real-world datasets show that our model achieves substantial improvement over state-of-the-art isolation-based and non-isolation-based anomaly detection models.
RayMVSNet: Learning Ray-based 1D Implicit Fields for Accurate Multi-View Stereo
Apr 04, 2022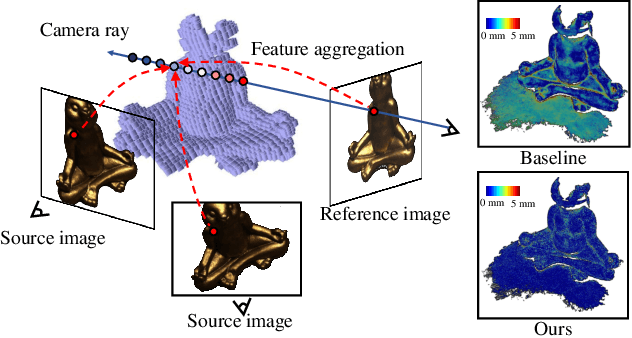
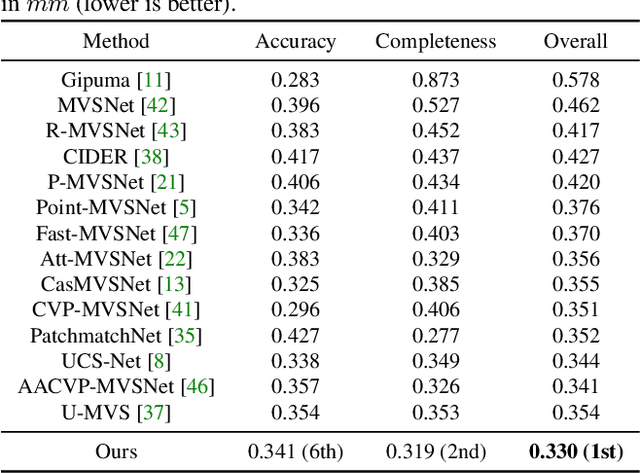
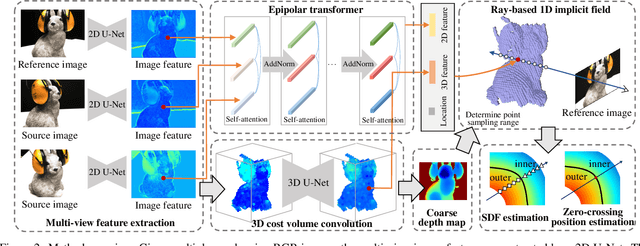
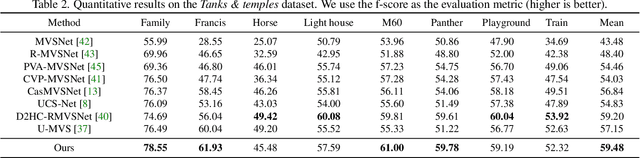
Learning-based multi-view stereo (MVS) has by far centered around 3D convolution on cost volumes. Due to the high computation and memory consumption of 3D CNN, the resolution of output depth is often considerably limited. Different from most existing works dedicated to adaptive refinement of cost volumes, we opt to directly optimize the depth value along each camera ray, mimicking the range (depth) finding of a laser scanner. This reduces the MVS problem to ray-based depth optimization which is much more light-weight than full cost volume optimization. In particular, we propose RayMVSNet which learns sequential prediction of a 1D implicit field along each camera ray with the zero-crossing point indicating scene depth. This sequential modeling, conducted based on transformer features, essentially learns the epipolar line search in traditional multi-view stereo. We also devise a multi-task learning for better optimization convergence and depth accuracy. Our method ranks top on both the DTU and the Tanks \& Temples datasets over all previous learning-based methods, achieving overall reconstruction score of 0.33mm on DTU and f-score of 59.48% on Tanks & Temples.
Provable Constrained Stochastic Convex Optimization with XOR-Projected Gradient Descent
Mar 22, 2022
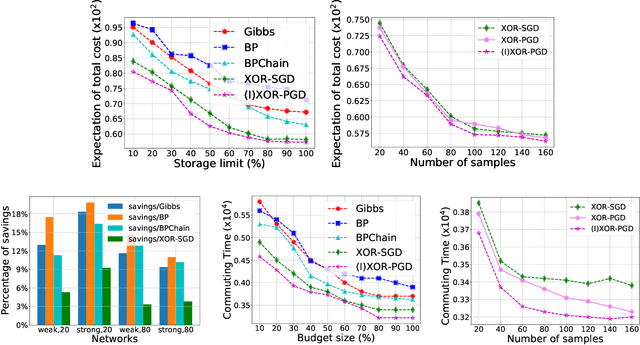

Provably solving stochastic convex optimization problems with constraints is essential for various problems in science, business, and statistics. Recently proposed XOR-Stochastic Gradient Descent (XOR-SGD) provides a convergence rate guarantee solving the constraints-free version of the problem by leveraging XOR-Sampling. However, the task becomes more difficult when additional equality and inequality constraints are needed to be satisfied. Here we propose XOR-PGD, a novel algorithm based on Projected Gradient Descent (PGD) coupled with the XOR sampler, which is guaranteed to solve the constrained stochastic convex optimization problem still in linear convergence rate by choosing proper step size. We show on both synthetic stochastic inventory management and real-world road network design problems that the rate of constraints satisfaction of the solutions optimized by XOR-PGD is $10\%$ more than the competing approaches in a very large searching space. The improved XOR-PGD algorithm is demonstrated to be more accurate and efficient than both XOR-SGD and SGD coupled with MCMC based samplers. It is also shown to be more scalable with respect to the number of samples and processor cores via experiments with large dimensions.
Fast Projection onto the Capped Simplex with Applications to Sparse Regression in Bioinformatics
Oct 26, 2021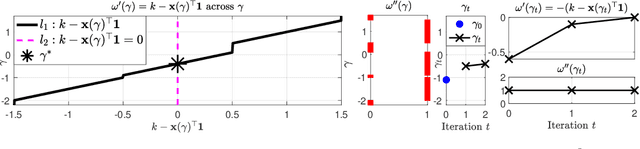
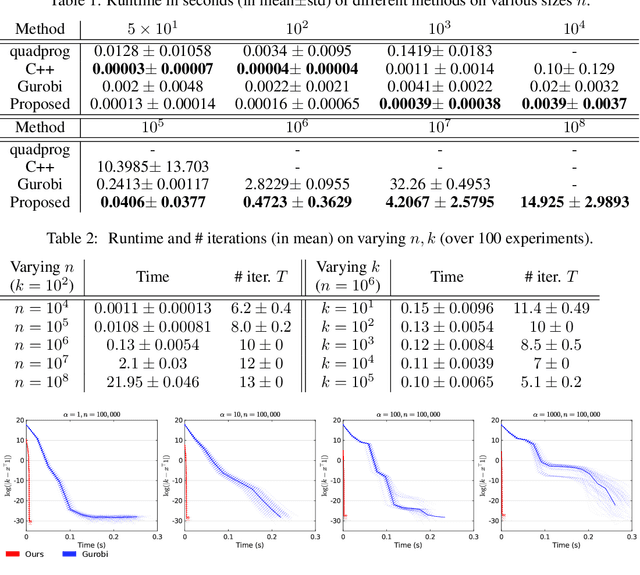
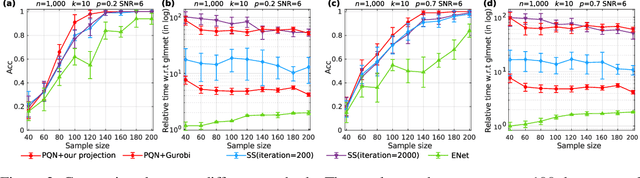
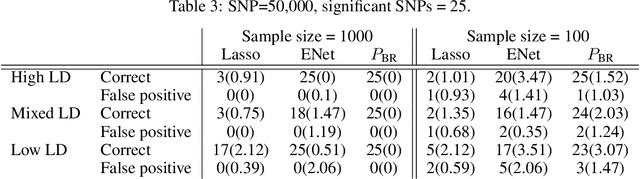
We consider the problem of projecting a vector onto the so-called k-capped simplex, which is a hyper-cube cut by a hyperplane. For an n-dimensional input vector with bounded elements, we found that a simple algorithm based on Newton's method is able to solve the projection problem to high precision with a complexity roughly about O(n), which has a much lower computational cost compared with the existing sorting-based methods proposed in the literature. We provide a theory for partial explanation and justification of the method. We demonstrate that the proposed algorithm can produce a solution of the projection problem with high precision on large scale datasets, and the algorithm is able to significantly outperform the state-of-the-art methods in terms of runtime (about 6-8 times faster than a commercial software with respect to CPU time for input vector with 1 million variables or more). We further illustrate the effectiveness of the proposed algorithm on solving sparse regression in a bioinformatics problem. Empirical results on the GWAS dataset (with 1,500,000 single-nucleotide polymorphisms) show that, when using the proposed method to accelerate the Projected Quasi-Newton (PQN) method, the accelerated PQN algorithm is able to handle huge-scale regression problem and it is more efficient (about 3-6 times faster) than the current state-of-the-art methods.
DRAM Failure Prediction in AIOps: Empirical Evaluation, Challenges and Opportunities
May 04, 2021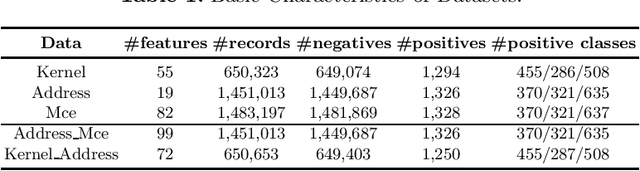
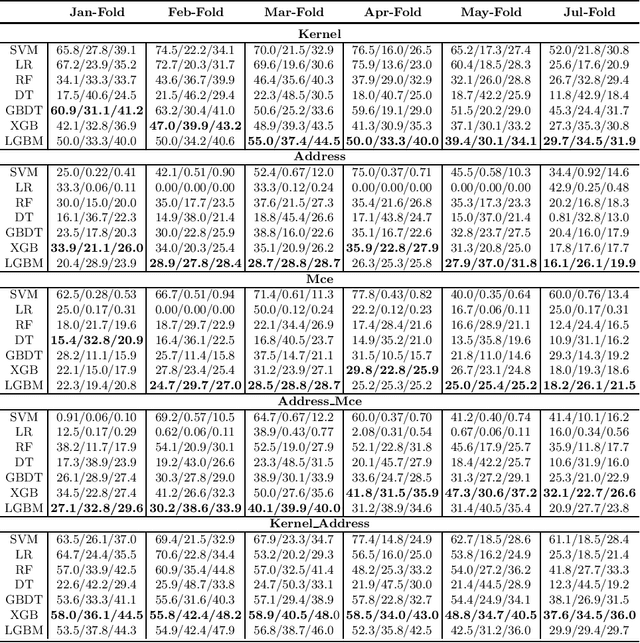
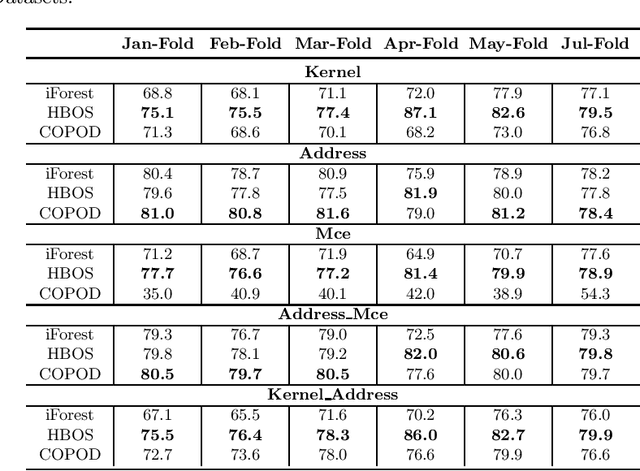
DRAM failure prediction is a vital task in AIOps, which is crucial to maintain the reliability and sustainable service of large-scale data centers. However, limited work has been done on DRAM failure prediction mainly due to the lack of public available datasets. This paper presents a comprehensive empirical evaluation of diverse machine learning techniques for DRAM failure prediction using a large-scale multi-source dataset, including more than three millions of records of kernel, address, and mcelog data, provided by Alibaba Cloud through PAKDD 2021 competition. Particularly, we first formulate the problem as a multi-class classification task and exhaustively evaluate seven popular/state-of-the-art classifiers on both the individual and multiple data sources. We then formulate the problem as an unsupervised anomaly detection task and evaluate three state-of-the-art anomaly detectors. Further, based on the empirical results and our experience of attending this competition, we discuss major challenges and present future research opportunities in this task.
Wasserstein Robust Support Vector Machines with Fairness Constraints
Mar 11, 2021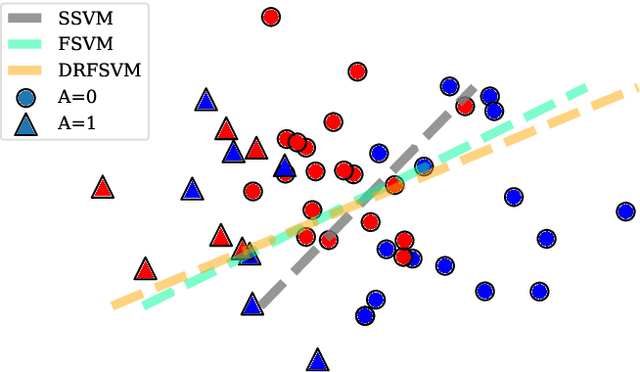

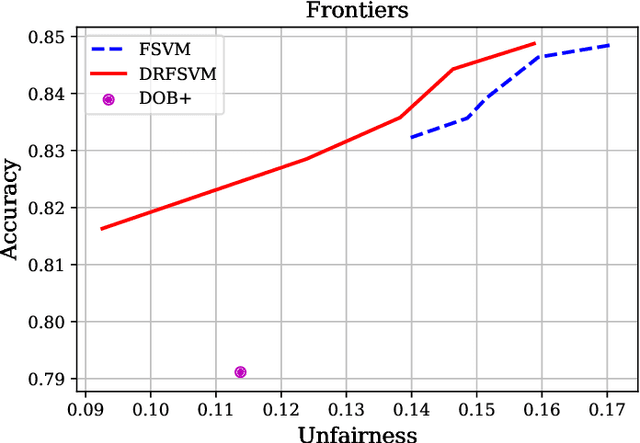
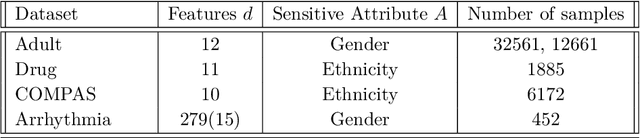
We propose a distributionally robust support vector machine with a fairness constraint that encourages the classifier to be fair in view of the equality of opportunity criterion. We use a type-$\infty$ Wasserstein ambiguity set centered at the empirical distribution to model distributional uncertainty and derive an exact reformulation for worst-case unfairness measure. We establish that the model is equivalent to a mixed-binary optimization problem, which can be solved by standard off-the-shelf solvers. We further prove that the expectation of the hinge loss objective function constitutes an upper bound on the misclassification probability. Finally, we numerically demonstrate that our proposed approach improves fairness with negligible loss of predictive accuracy.
Outlier Detection Ensemble with Embedded Feature Selection
Jan 15, 2020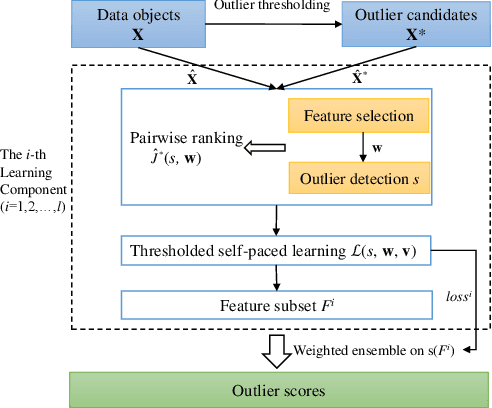
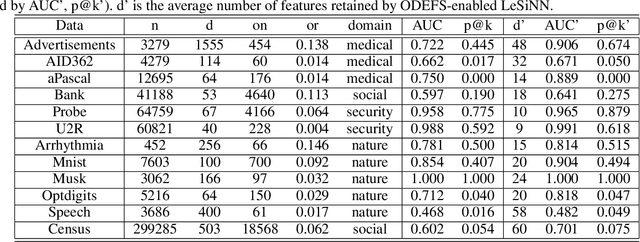
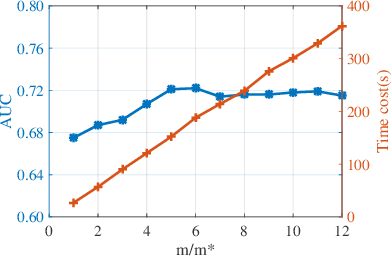
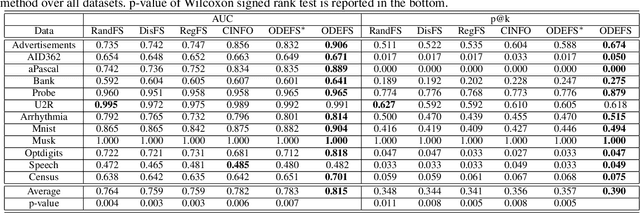
Feature selection places an important role in improving the performance of outlier detection, especially for noisy data. Existing methods usually perform feature selection and outlier scoring separately, which would select feature subsets that may not optimally serve for outlier detection, leading to unsatisfying performance. In this paper, we propose an outlier detection ensemble framework with embedded feature selection (ODEFS), to address this issue. Specifically, for each random sub-sampling based learning component, ODEFS unifies feature selection and outlier detection into a pairwise ranking formulation to learn feature subsets that are tailored for the outlier detection method. Moreover, we adopt the thresholded self-paced learning to simultaneously optimize feature selection and example selection, which is helpful to improve the reliability of the training set. After that, we design an alternate algorithm with proved convergence to solve the resultant optimization problem. In addition, we analyze the generalization error bound of the proposed framework, which provides theoretical guarantee on the method and insightful practical guidance. Comprehensive experimental results on 12 real-world datasets from diverse domains validate the superiority of the proposed ODEFS.