 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge1.x-Distill: Breaking the Diversity, Quality, and Efficiency Barrier in Distribution Matching Distillation
Apr 05, 2026Diffusion models produce high-quality text-to-image results, but their iterative denoising is computationally expensive.Distribution Matching Distillation (DMD) emerges as a promising path to few-step distillation, but suffers from diversity collapse and fidelity degradation when reduced to two steps or fewer. We present 1.x-Distill, the first fractional-step distillation framework that breaks the integer-step constraint of prior few-step methods and establishes 1.x-step generation as a practical regime for distilled diffusion models.Specifically, we first analyze the overlooked role of teacher CFG in DMD and introduce a simple yet effective modification to suppress mode collapse. Then, to improve performance under extreme steps, we introduce Stagewise Focused Distillation, a two-stage strategy that learns coarse structure through diversity-preserving distribution matching and refines details with inference-consistent adversarial distillation. Furthermore, we design a lightweight compensation module for Distill--Cache co-Training, which naturally incorporates block-level caching into our distillation pipeline.Experiments on SD3-Medium and SD3.5-Large show that 1.x-Distill surpasses prior few-step methods, achieving better quality and diversity at 1.67 and 1.74 effective NFEs, respectively, with up to 33x speedup over original 28x2 NFE sampling.
No Cache Left Idle: Accelerating diffusion model via Extreme-slimming Caching
Dec 14, 2025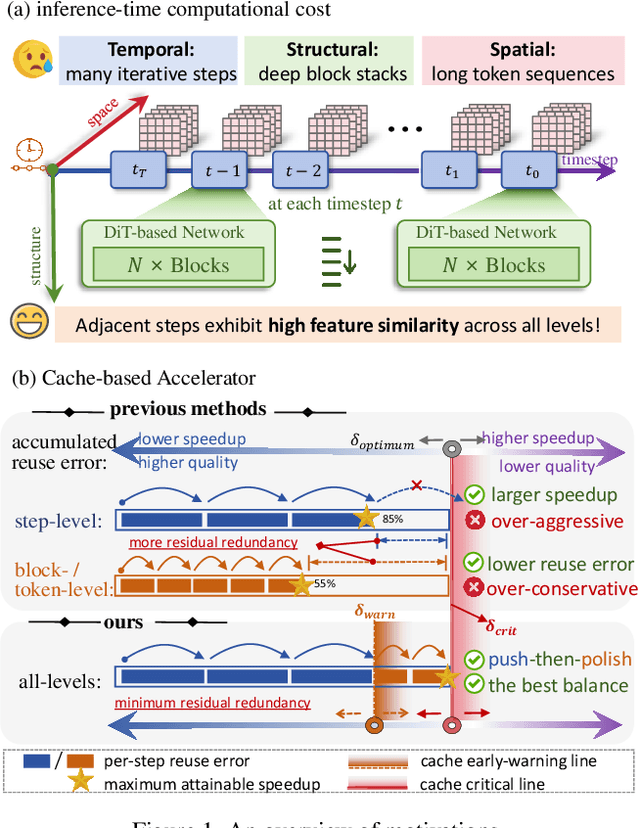
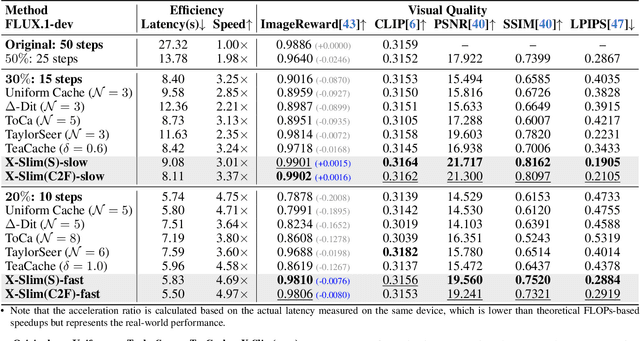
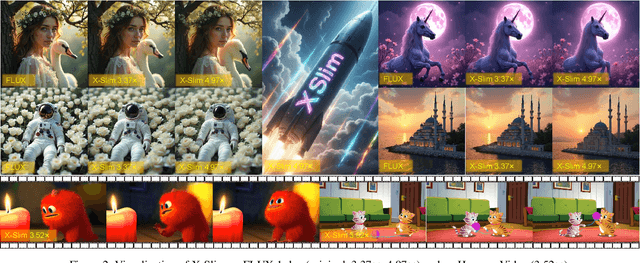
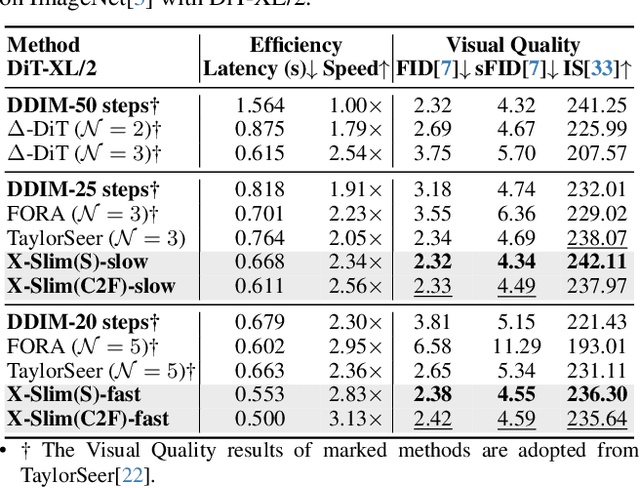
Diffusion models achieve remarkable generative quality, but computational overhead scales with step count, model depth, and sequence length. Feature caching is effective since adjacent timesteps yield highly similar features. However, an inherent trade-off remains: aggressive timestep reuse offers large speedups but can easily cross the critical line, hurting fidelity, while block- or token-level reuse is safer but yields limited computational savings. We present X-Slim (eXtreme-Slimming Caching), a training-free, cache-based accelerator that, to our knowledge, is the first unified framework to exploit cacheable redundancy across timesteps, structure (blocks), and space (tokens). Rather than simply mixing levels, X-Slim introduces a dual-threshold controller that turns caching into a push-then-polish process: it first pushes reuse at the timestep level up to an early-warning line, then switches to lightweight block- and token-level refresh to polish the remaining redundancy, and triggers full inference once the critical line is crossed to reset accumulated error. At each level, context-aware indicators decide when and where to cache. Across diverse tasks, X-Slim advances the speed-quality frontier. On FLUX.1-dev and HunyuanVideo, it reduces latency by up to 4.97x and 3.52x with minimal perceptual loss. On DiT-XL/2, it reaches 3.13x acceleration and improves FID by 2.42 over prior methods.