 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniToolCall: Unifying Tool-Use Representation, Data, and Evaluation for LLM Agents
Apr 13, 2026Tool-use capability is a fundamental component of LLM agents, enabling them to interact with external systems through structured function calls. However, existing research exhibits inconsistent interaction representations, largely overlooks the structural distribution of tool-use trajectories, and relies on incompatible evaluation benchmarks. We present UniToolCall, a unified framework for tool learning that standardizes the entire pipeline from toolset construction and dataset generation to evaluation. The framework curates a large tool pool of 22k+ tools and constructs a hybrid training corpus of 390k+ instances by combining 10 standardized public datasets with structurally controlled synthetic trajectories. It explicitly models diverse interaction patterns, including single-hop vs. multi-hop and single-turn vs. multi-turn, while capturing both serial and parallel execution structures. To support coherent multi-turn reasoning, we further introduce an Anchor Linkage mechanism that enforces cross-turn dependencies. Furthermore, we convert 7 public benchmarks into a unified Query--Action--Observation--Answer (QAOA) representation with fine-grained evaluation at the function-call, turn, and conversation levels. Experiments show that fine-tuning Qwen3-8B on our dataset substantially improves tool-use performance. Under the distractor-heavy Hybrid-20 setting, achieves 93.0% single-turn Strict Precision, outperforming commercial models including GPT, Gemini, and Claude.
Friends and Foes in Learning from Noisy Labels
Mar 28, 2021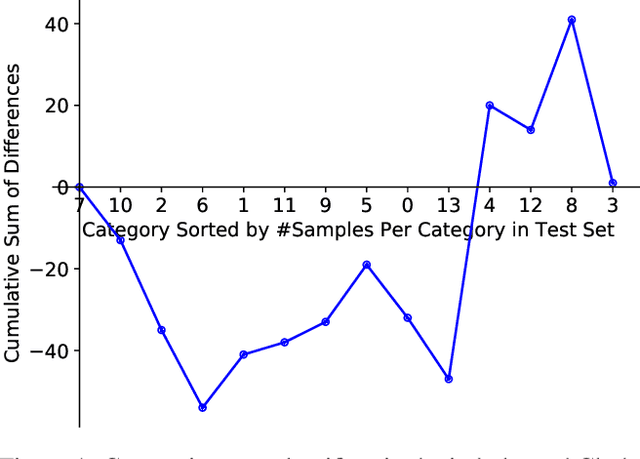
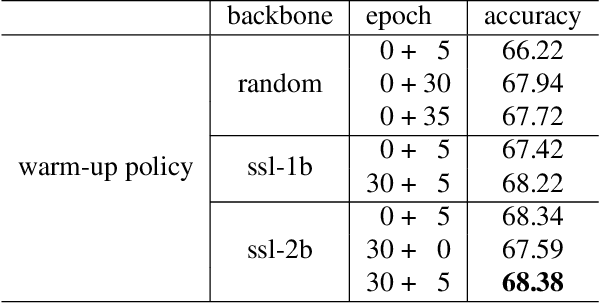
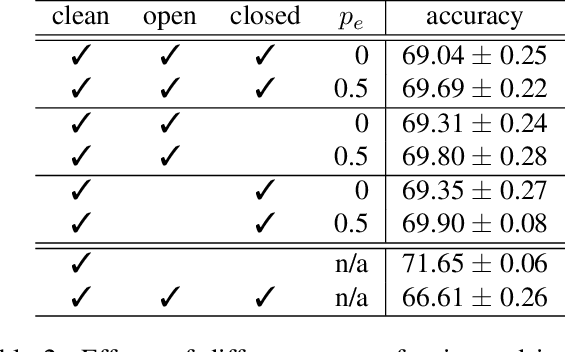
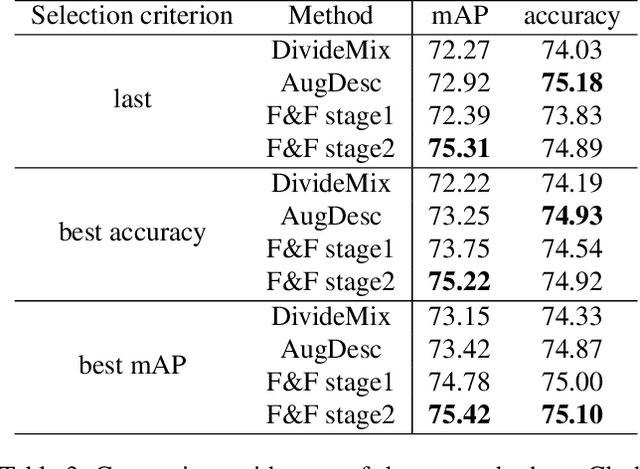
Learning from examples with noisy labels has attracted increasing attention recently. But, this paper will show that the commonly used CIFAR-based datasets and the accuracy evaluation metric used in the literature are both inappropriate in this context. An alternative valid evaluation metric and new datasets are proposed in this paper to promote proper research and evaluation in this area. Then, friends and foes are identified from existing methods as technical components that are either beneficial or detrimental to deep learning from noisy labeled examples, respectively, and this paper improves and combines technical components from the friends category, including self-supervised learning, new warmup strategy, instance filtering and label correction. The resulting F&F method significantly outperforms existing methods on the proposed nCIFAR datasets and the real-world Clothing1M dataset.
In Defense of Feature Mimicking for Knowledge Distillation
Nov 03, 2020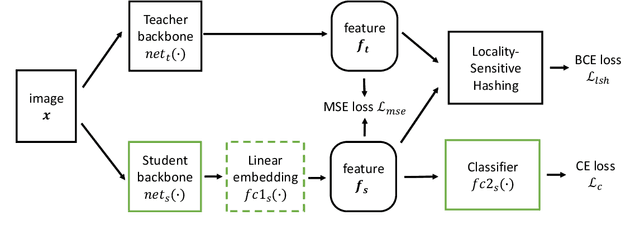
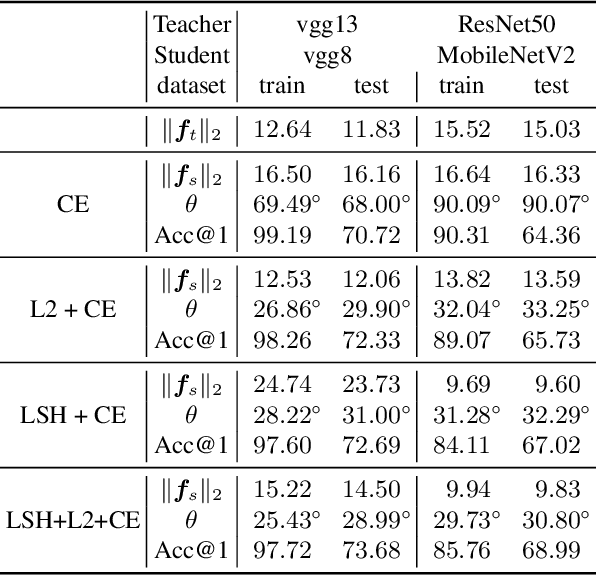
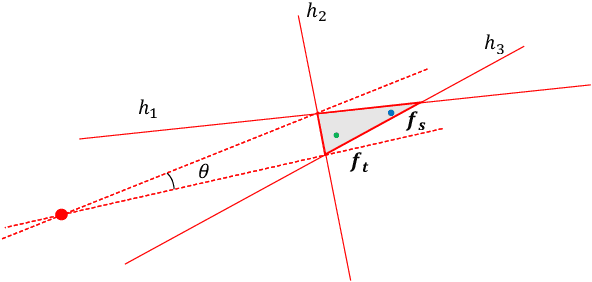
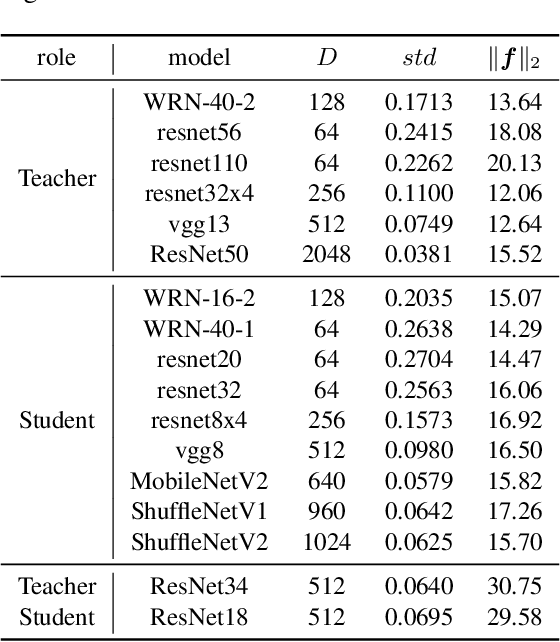
Knowledge distillation (KD) is a popular method to train efficient networks ("student") with the help of high-capacity networks ("teacher"). Traditional methods use the teacher's soft logit as extra supervision to train the student network. In this paper, we argue that it is more advantageous to make the student mimic the teacher's features in the penultimate layer. Not only the student can directly learn more effective information from the teacher feature, feature mimicking can also be applied for teachers trained without a softmax layer. Experiments show that it can achieve higher accuracy than traditional KD. To further facilitate feature mimicking, we decompose a feature vector into the magnitude and the direction. We argue that the teacher should give more freedom to the student feature's magnitude, and let the student pay more attention on mimicking the feature direction. To meet this requirement, we propose a loss term based on locality-sensitive hashing (LSH). With the help of this new loss, our method indeed mimics feature directions more accurately, relaxes constraints on feature magnitudes, and achieves state-of-the-art distillation accuracy.