 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusionBERT: Multi-View Image-3D Retrieval via Cross-Attention Visual Fusion and Normal-Aware 3D Encoder
Apr 02, 2026We propose FusionBERT, a novel multi-view visual fusion framework for image-3D multimodal retrieval. Existing image-3D representation learning methods predominantly focus on feature alignment of a single object image and its 3D model, limiting their applicability in realistic scenarios where an object is typically observed and captured from multiple viewpoints. Although multi-view observations naturally provide complementary geometric and appearance cues, existing multimodal large models rarely explore how to effectively fuse such multi-view visual information for better cross-modal retrieval. To address this limitation, we introduce a multi-view image-3D retrieval framework named FusionBERT, which innovatively utilizes a cross-attention-based multi-view visual aggregator to adaptively integrate features from multi-view images of an object. The proposed multi-view visual encoder fuses inter-view complementary relationships and selectively emphasizes informative visual cues across multiple views to get a more robustly fused visual feature for better 3D model matching. Furthermore, FusionBERT proposes a normal-aware 3D model encoder that can further enhance the 3D geometric feature of an object model by jointly encoding point normals and 3D positions, enabling a more robust representation learning for textureless or color-degraded 3D models. Extensive image-3D retrieval experiments demonstrate that FusionBERT achieves significantly higher retrieval accuracy than SOTA multimodal large models under both single-view and multi-view settings, establishing a strong baseline for multi-view multimodal retrieval.
From Sparse to Dense: Camera Relocalization with Scene-Specific Detector from Feature Gaussian Splatting
Mar 25, 2025


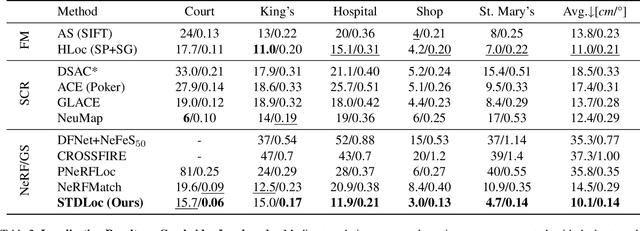
This paper presents a novel camera relocalization method, STDLoc, which leverages Feature Gaussian as scene representation. STDLoc is a full relocalization pipeline that can achieve accurate relocalization without relying on any pose prior. Unlike previous coarse-to-fine localization methods that require image retrieval first and then feature matching, we propose a novel sparse-to-dense localization paradigm. Based on this scene representation, we introduce a novel matching-oriented Gaussian sampling strategy and a scene-specific detector to achieve efficient and robust initial pose estimation. Furthermore, based on the initial localization results, we align the query feature map to the Gaussian feature field by dense feature matching to enable accurate localization. The experiments on indoor and outdoor datasets show that STDLoc outperforms current state-of-the-art localization methods in terms of localization accuracy and recall.