 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleTextGen: Style-Conditioned Multilingual Scene Text Generation
May 14, 2026Style-conditioned scene text generation faces unique challenges in extracting precise text styles from complex backgrounds and maintaining fine-grained style consistency across characters, especially for multilingual scripts. We propose StyleTextGen, a novel framework that learns to perceive and replicate visual text styles across different languages and writing systems. Our approach features three key contributions: First, we introduce a dual-branch style encoder dedicated to style modeling, yielding robust multilingual text style representations in complex real-world scenes. Second, we design a text style consistency loss that enhances style coherence and improves overall visual quality. Third, we develop a mask-guided inference strategy that ensures precise style alignment between generated and reference text. To facilitate systematic evaluation, we construct StyleText-CE, a bilingual scene text style benchmark covering both monolingual and cross-lingual settings. Extensive experiments demonstrate that StyleTextGen significantly outperforms existing methods in style consistency and cross-lingual generalization, establishing new state-of-the-art performance in multilingual style-conditioned text generation.
Progressive $\mathcal{J}$-Invariant Self-supervised Learning for Low-Dose CT Denoising
Jan 28, 2026Self-supervised learning has been increasingly investigated for low-dose computed tomography (LDCT) image denoising, as it alleviates the dependence on paired normal-dose CT (NDCT) data, which are often difficult to collect. However, many existing self-supervised blind-spot denoising methods suffer from training inefficiencies and suboptimal performance due to restricted receptive fields. To mitigate this issue, we propose a novel Progressive $\mathcal{J}$-invariant Learning that maximizes the use of $\mathcal{J}$-invariant to enhance LDCT denoising performance. We introduce a step-wise blind-spot denoising mechanism that enforces conditional independence in a progressive manner, enabling more fine-grained learning for denoising. Furthermore, we explicitly inject a combination of controlled Gaussian and Poisson noise during training to regularize the denoising process and mitigate overfitting. Extensive experiments on the Mayo LDCT dataset demonstrate that the proposed method consistently outperforms existing self-supervised approaches and achieves performance comparable to, or better than, several representative supervised denoising methods.
Progressive self-supervised blind-spot denoising method for LDCT denoising
Jan 20, 2026Self-supervised learning is increasingly investigated for low-dose computed tomography (LDCT) image denoising, as it alleviates the dependence on paired normal-dose CT (NDCT) data, which are often difficult to acquire in clinical practice. In this paper, we propose a novel self-supervised training strategy that relies exclusively on LDCT images. We introduce a step-wise blind-spot denoising mechanism that enforces conditional independence in a progressive manner, enabling more fine-grained denoising learning. In addition, we add Gaussian noise to LDCT images, which acts as a regularization and mitigates overfitting. Extensive experiments on the Mayo LDCT dataset demonstrate that the proposed method consistently outperforms existing self-supervised approaches and achieves performance comparable to, or better than, several representative supervised denoising methods.
Learning to Discover Generalized Facial Expressions
Sep 30, 2024



We introduce Facial Expression Category Discovery (FECD), a novel task in the domain of open-world facial expression recognition (O-FER). While Generalized Category Discovery (GCD) has been explored in natural image datasets, applying it to facial expressions presents unique challenges. Specifically, we identify two key biases to better understand these challenges: Theoretical Bias-arising from the introduction of new categories in unlabeled training data, and Practical Bias-stemming from the imbalanced and fine-grained nature of facial expression data. To address these challenges, we propose FER-GCD, an adversarial approach that integrates both implicit and explicit debiasing components. In the implicit debiasing process, we devise F-discrepancy, a novel metric used to estimate the upper bound of Theoretical Bias, helping the model minimize this upper bound through adversarial training. The explicit debiasing process further optimizes the feature generator and classifier to reduce Practical Bias. Extensive experiments on GCD-based FER datasets demonstrate that our FER-GCD framework significantly improves accuracy on both old and new categories, achieving an average improvement of 9.8% over the baseline and outperforming state-of-the-art methods.
Exploring Large Language Models for Human Mobility Prediction under Public Events
Nov 29, 2023Public events, such as concerts and sports games, can be major attractors for large crowds, leading to irregular surges in travel demand. Accurate human mobility prediction for public events is thus crucial for event planning as well as traffic or crowd management. While rich textual descriptions about public events are commonly available from online sources, it is challenging to encode such information in statistical or machine learning models. Existing methods are generally limited in incorporating textual information, handling data sparsity, or providing rationales for their predictions. To address these challenges, we introduce a framework for human mobility prediction under public events (LLM-MPE) based on Large Language Models (LLMs), leveraging their unprecedented ability to process textual data, learn from minimal examples, and generate human-readable explanations. Specifically, LLM-MPE first transforms raw, unstructured event descriptions from online sources into a standardized format, and then segments historical mobility data into regular and event-related components. A prompting strategy is designed to direct LLMs in making and rationalizing demand predictions considering historical mobility and event features. A case study is conducted for Barclays Center in New York City, based on publicly available event information and taxi trip data. Results show that LLM-MPE surpasses traditional models, particularly on event days, with textual data significantly enhancing its accuracy. Furthermore, LLM-MPE offers interpretable insights into its predictions. Despite the great potential of LLMs, we also identify key challenges including misinformation and high costs that remain barriers to their broader adoption in large-scale human mobility analysis.
Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions
Dec 10, 2021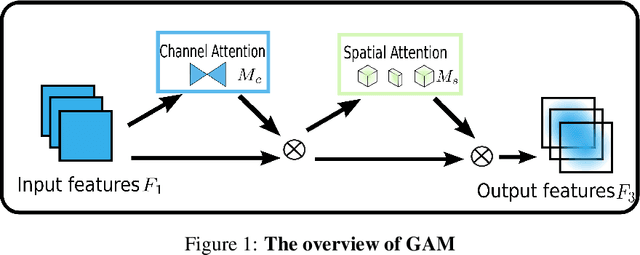
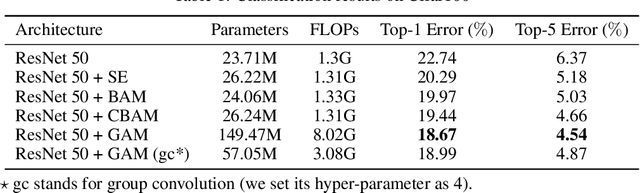
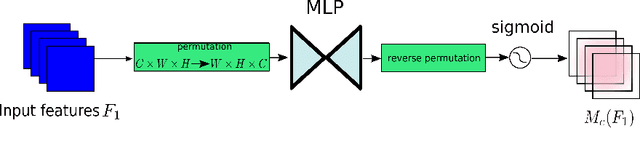
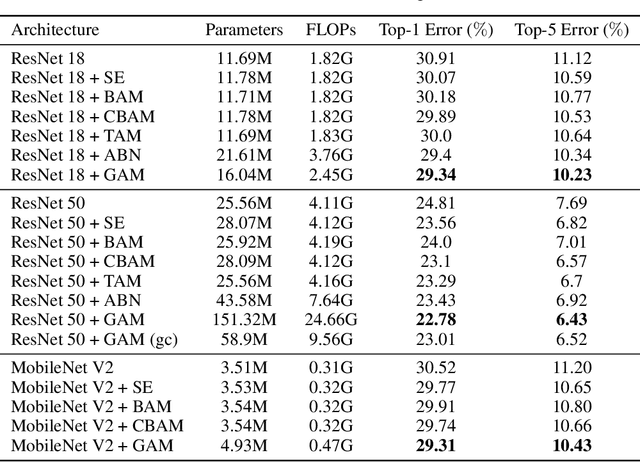
A variety of attention mechanisms have been studied to improve the performance of various computer vision tasks. However, the prior methods overlooked the significance of retaining the information on both channel and spatial aspects to enhance the cross-dimension interactions. Therefore, we propose a global attention mechanism that boosts the performance of deep neural networks by reducing information reduction and magnifying the global interactive representations. We introduce 3D-permutation with multilayer-perceptron for channel attention alongside a convolutional spatial attention submodule. The evaluation of the proposed mechanism for the image classification task on CIFAR-100 and ImageNet-1K indicates that our method stably outperforms several recent attention mechanisms with both ResNet and lightweight MobileNet.
NAM: Normalization-based Attention Module
Nov 24, 2021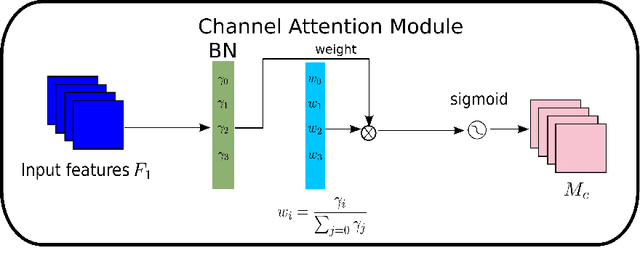
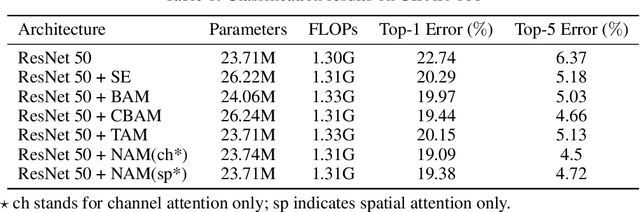
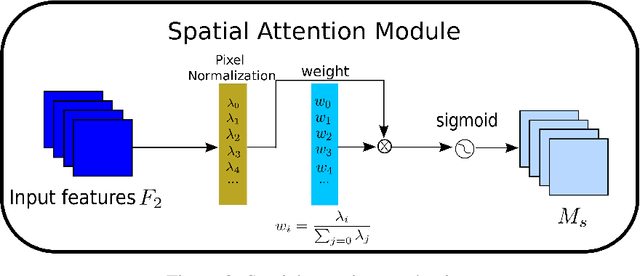
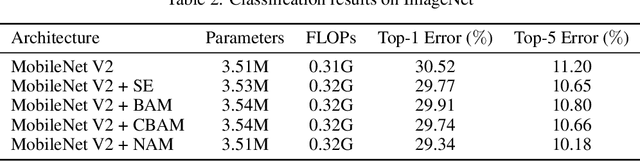
Recognizing less salient features is the key for model compression. However, it has not been investigated in the revolutionary attention mechanisms. In this work, we propose a novel normalization-based attention module (NAM), which suppresses less salient weights. It applies a weight sparsity penalty to the attention modules, thus, making them more computational efficient while retaining similar performance. A comparison with three other attention mechanisms on both Resnet and Mobilenet indicates that our method results in higher accuracy. Code for this paper can be publicly accessed at https://github.com/Christian-lyc/NAM.