 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangled Sequence Clustering for Human Intention Inference
Jan 23, 2021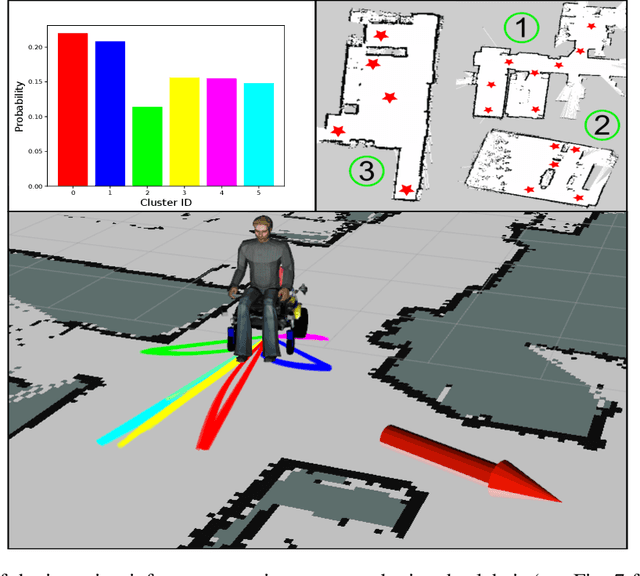
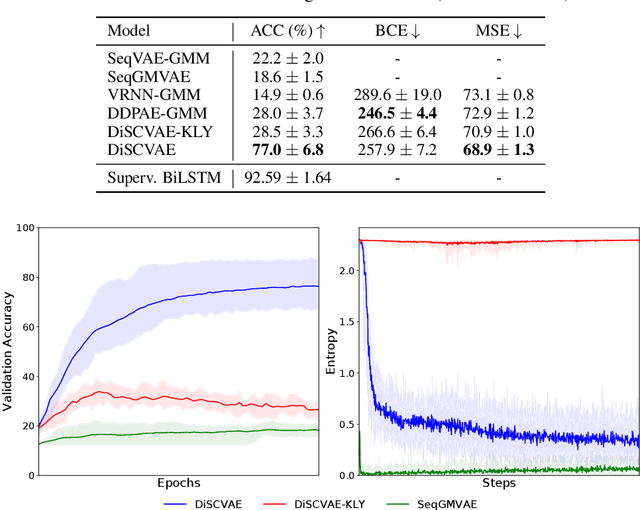
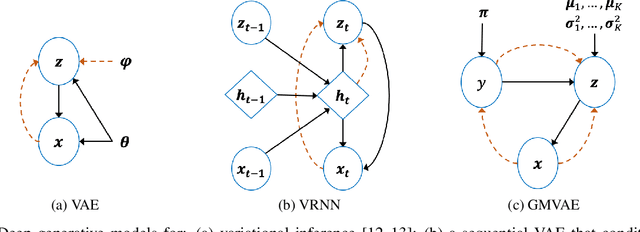

Equipping robots with the ability to infer human intent is a vital precondition for effective collaboration. Most computational approaches towards this objective employ probabilistic reasoning to recover a distribution of "intent" conditioned on the robot's perceived sensory state. However, these approaches typically assume task-specific notions of human intent (e.g. labelled goals) are known a priori. To overcome this constraint, we propose the Disentangled Sequence Clustering Variational Autoencoder (DiSCVAE), a clustering framework that can be used to learn such a distribution of intent in an unsupervised manner. The DiSCVAE leverages recent advances in unsupervised learning to derive a disentangled latent representation of sequential data, separating time-varying local features from time-invariant global aspects. Though unlike previous frameworks for disentanglement, the proposed variant also infers a discrete variable to form a latent mixture model and enable clustering of global sequence concepts, e.g. intentions from observed human behaviour. To evaluate the DiSCVAE, we first validate its capacity to discover classes from unlabelled sequences using video datasets of bouncing digits and 2D animations. We then report results from a real-world human-robot interaction experiment conducted on a robotic wheelchair. Our findings glean insights into how the inferred discrete variable coincides with human intent and thus serves to improve assistance in collaborative settings, such as shared control.
D2D: Keypoint Extraction with Describe to Detect Approach
May 27, 2020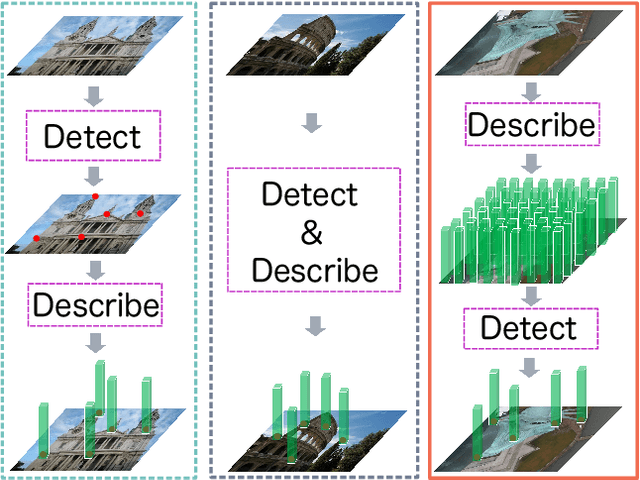
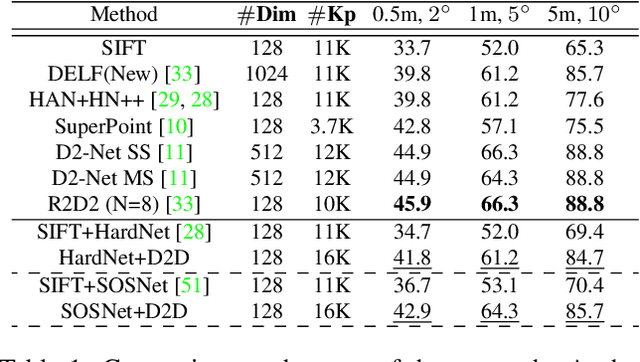
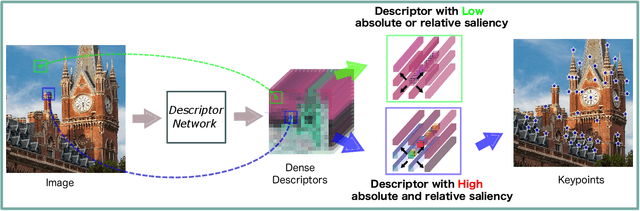
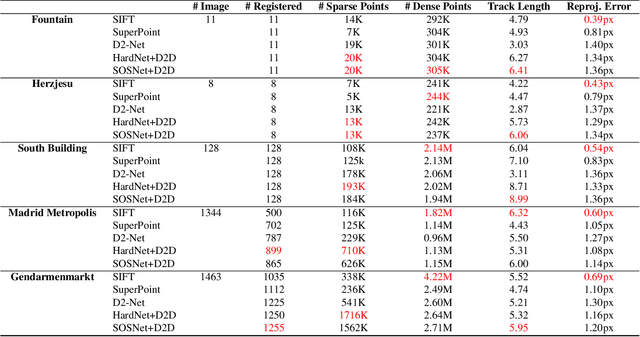
In this paper, we present a novel approach that exploits the information within the descriptor space to propose keypoint locations. Detect then describe, or detect and describe jointly are two typical strategies for extracting local descriptors. In contrast, we propose an approach that inverts this process by first describing and then detecting the keypoint locations. % Describe-to-Detect (D2D) leverages successful descriptor models without the need for any additional training. Our method selects keypoints as salient locations with high information content which is defined by the descriptors rather than some independent operators. We perform experiments on multiple benchmarks including image matching, camera localisation, and 3D reconstruction. The results indicate that our method improves the matching performance of various descriptors and that it generalises across methods and tasks.
Support-weighted Adversarial Imitation Learning
Feb 20, 2020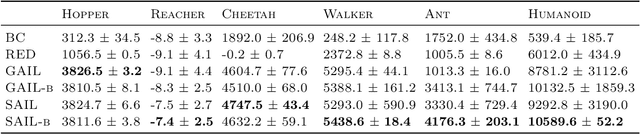
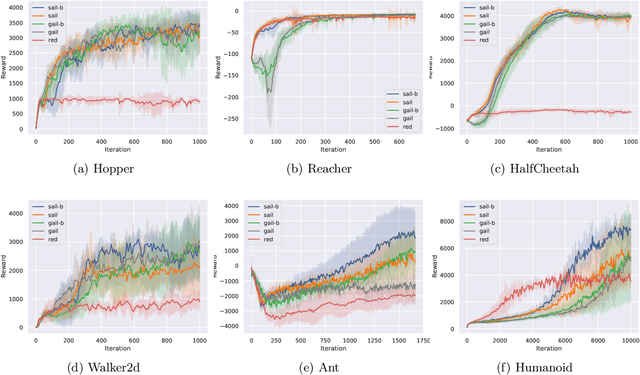


Adversarial Imitation Learning (AIL) is a broad family of imitation learning methods designed to mimic expert behaviors from demonstrations. While AIL has shown state-of-the-art performance on imitation learning with only small number of demonstrations, it faces several practical challenges such as potential training instability and implicit reward bias. To address the challenges, we propose Support-weighted Adversarial Imitation Learning (SAIL), a general framework that extends a given AIL algorithm with information derived from support estimation of the expert policies. SAIL improves the quality of the reinforcement signals by weighing the adversarial reward with a confidence score from support estimation of the expert policy. We also show that SAIL is always at least as efficient as the underlying AIL algorithm that SAIL uses for learning the adversarial reward. Empirically, we show that the proposed method achieves better performance and training stability than baseline methods on a wide range of benchmark control tasks.
A Structured Prediction Approach for Conditional Meta-Learning
Feb 20, 2020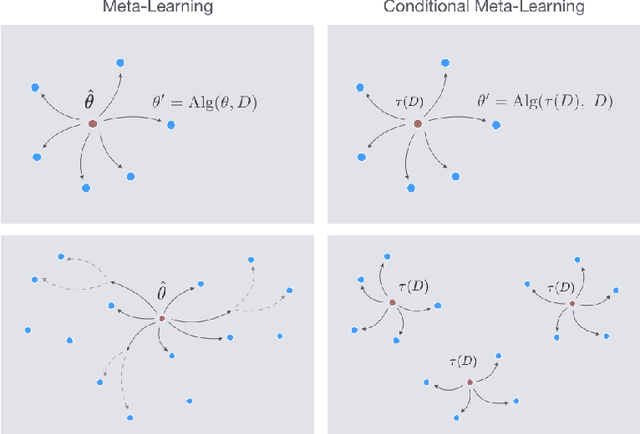
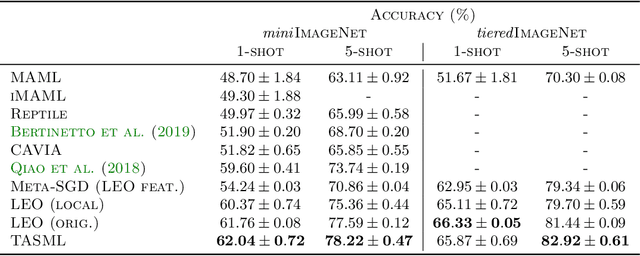
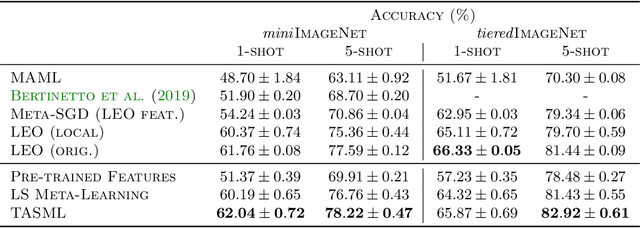
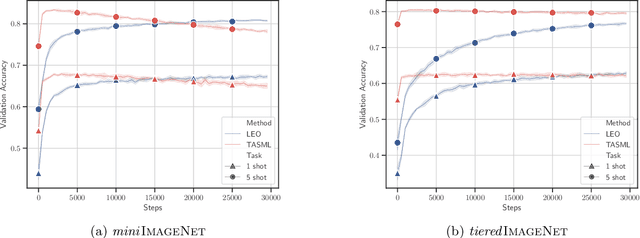
Optimization-based meta-learning algorithms are a powerful class of methods for learning-to-learn applications such as few-shot learning. They tackle the limited availability of training data by leveraging the experience gained from previously observed tasks. However, when the complexity of the tasks distribution cannot be captured by a single set of shared meta-parameters, existing methods may fail to fully adapt to a target task. We address this issue with a novel perspective on conditional meta-learning based on structured prediction. We propose task-adaptive structured meta-learning (TASML), a principled estimator that weighs meta-training data conditioned on the target task to design tailored meta-learning objectives. In addition, we introduce algorithmic improvements to tackle key computational limitations of existing methods. Experimentally, we show that TASML outperforms state-of-the-art methods on benchmark datasets both in terms of accuracy and efficiency. An ablation study quantifies the individual contribution of model components and suggests useful practices for meta-learning.
Multimodal representation models for prediction and control from partial information
Oct 09, 2019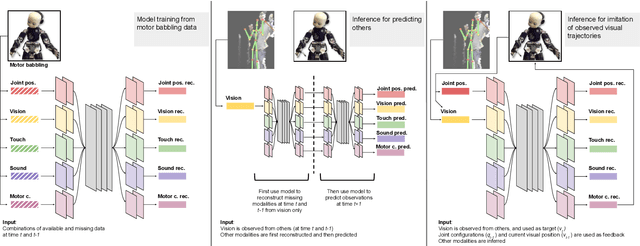

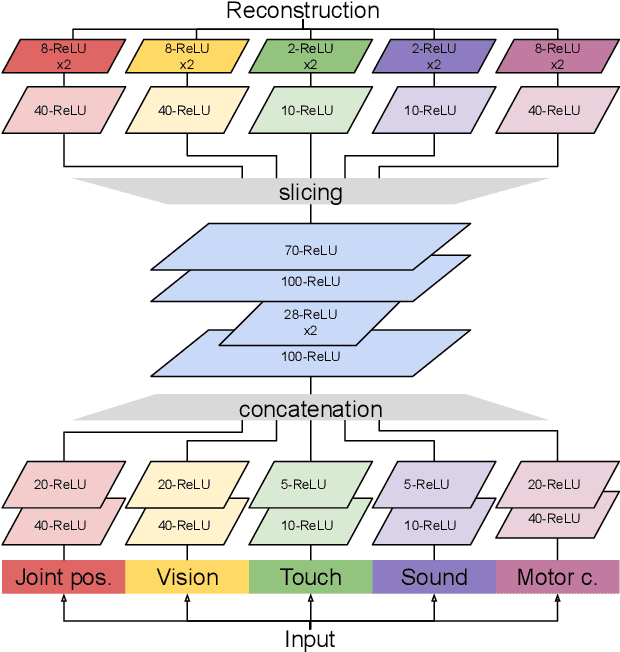
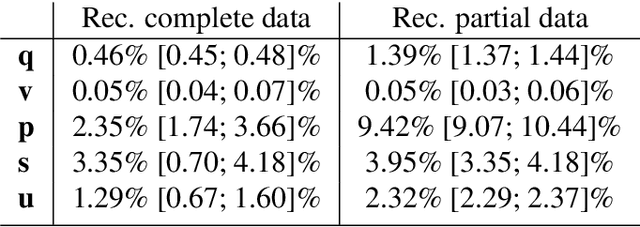
Similar to humans, robots benefit from interacting with their environment through a number of different sensor modalities, such as vision, touch, sound. However, learning from different sensor modalities is difficult, because the learning model must be able to handle diverse types of signals, and learn a coherent representation even when parts of the sensor inputs are missing. In this paper, a multimodal variational autoencoder is proposed to enable an iCub humanoid robot to learn representations of its sensorimotor capabilities from different sensor modalities. The proposed model is able to (1) reconstruct missing sensory modalities, (2) predict the sensorimotor state of self and the visual trajectories of other agents actions, and (3) control the agent to imitate an observed visual trajectory. Also, the proposed multimodal variational autoencoder can capture the kinematic redundancy of the robot motion through the learned probability distribution. Training multimodal models is not trivial due to the combinatorial complexity given by the possibility of missing modalities. We propose a strategy to train multimodal models, which successfully achieves improved performance of different reconstruction models. Finally, extensive experiments have been carried out using an iCub humanoid robot, showing high performance in multiple reconstruction, prediction and imitation tasks.
Variational Autoencoded Regression: High Dimensional Regression of Visual Data on Complex Manifold
Aug 12, 2019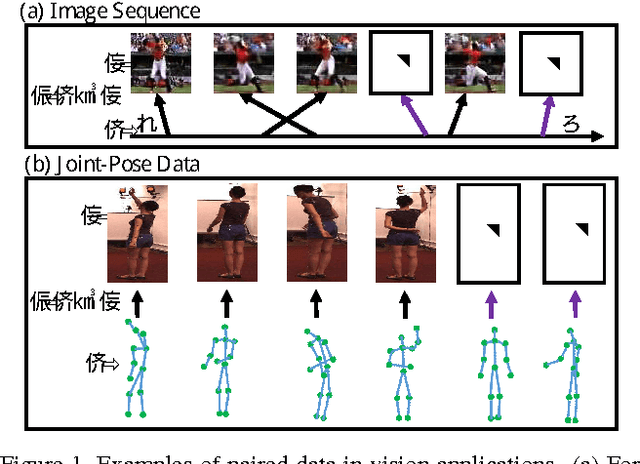

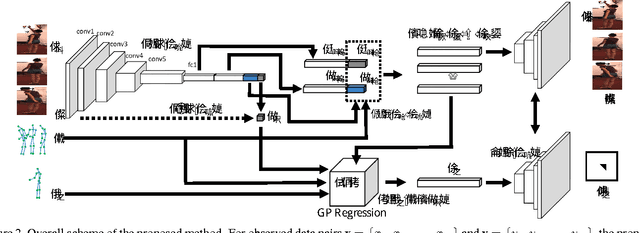
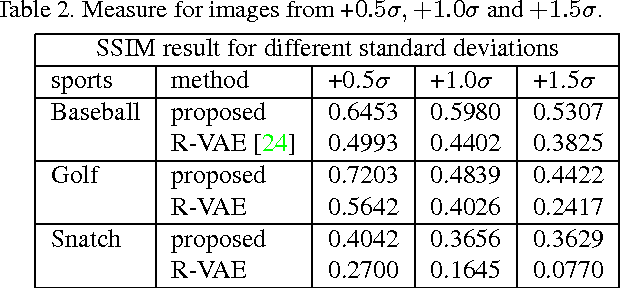
This paper proposes a new high dimensional regression method by merging Gaussian process regression into a variational autoencoder framework. In contrast to other regression methods, the proposed method focuses on the case where output responses are on a complex high dimensional manifold, such as images. Our contributions are summarized as follows: (i) A new regression method estimating high dimensional image responses, which is not handled by existing regression algorithms, is proposed. (ii) The proposed regression method introduces a strategy to learn the latent space as well as the encoder and decoder so that the result of the regressed response in the latent space coincide with the corresponding response in the data space. (iii) The proposed regression is embedded into a generative model, and the whole procedure is developed by the variational autoencoder framework. We demonstrate the robustness and effectiveness of our method through a number of experiments on various visual data regression problems.
Random Expert Distillation: Imitation Learning via Expert Policy Support Estimation
May 16, 2019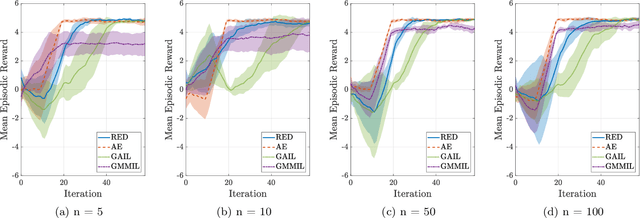

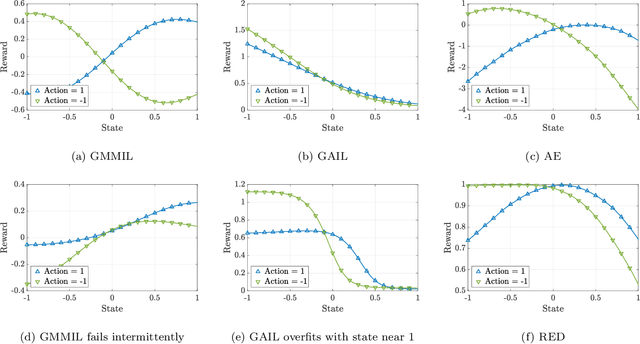
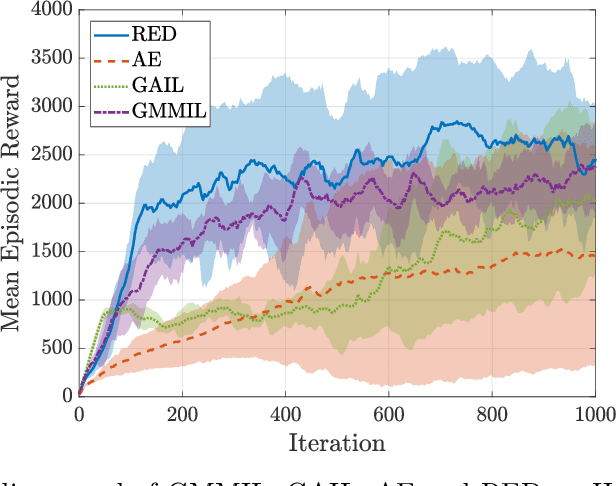
We consider the problem of imitation learning from a finite set of expert trajectories, without access to reinforcement signals. The classical approach of extracting the expert's reward function via inverse reinforcement learning, followed by reinforcement learning is indirect and may be computationally expensive. Recent generative adversarial methods based on matching the policy distribution between the expert and the agent could be unstable during training. We propose a new framework for imitation learning by estimating the support of the expert policy to compute a fixed reward function, which allows us to re-frame imitation learning within the standard reinforcement learning setting. We demonstrate the efficacy of our reward function on both discrete and continuous domains, achieving comparable or better performance than the state of the art under different reinforcement learning algorithms.
Real-Time Workload Classification during Driving using HyperNetworks
Oct 07, 2018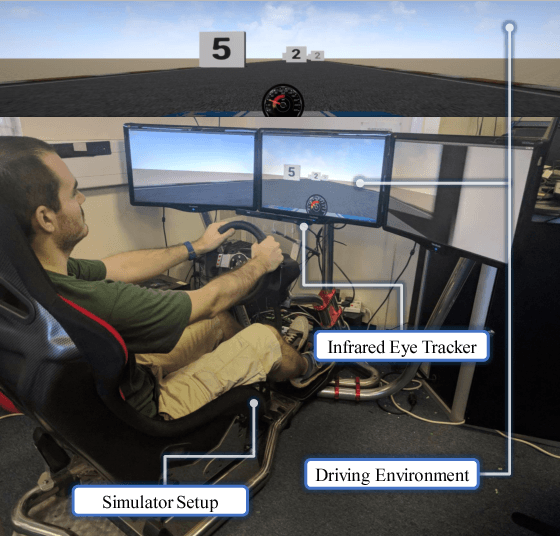
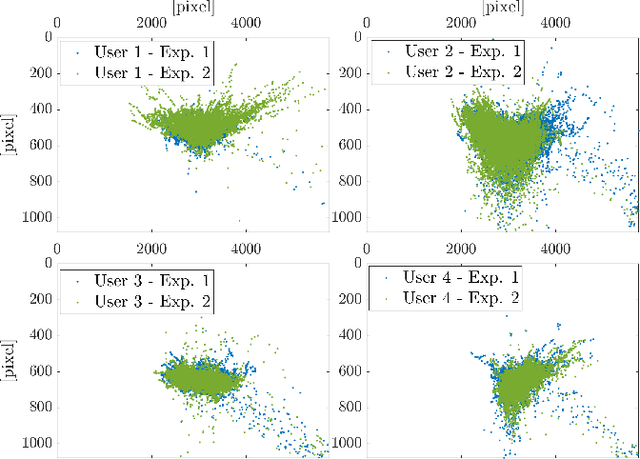
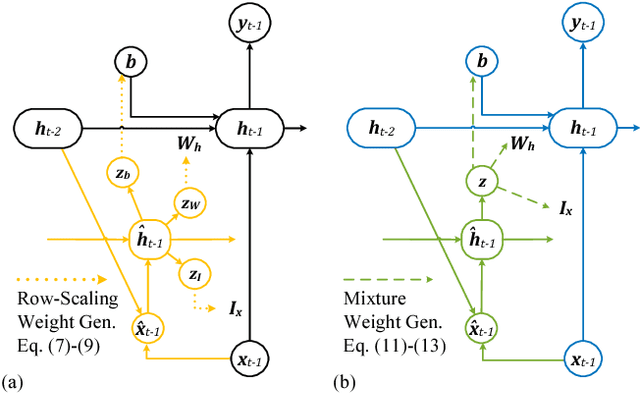
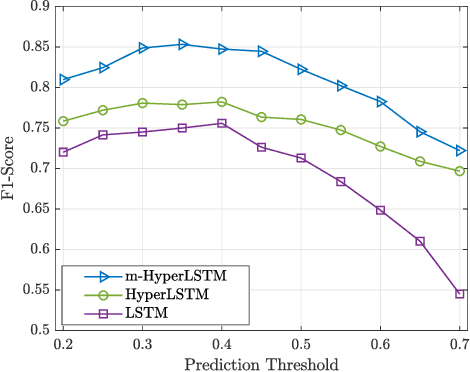
Classifying human cognitive states from behavioral and physiological signals is a challenging problem with important applications in robotics. The problem is challenging due to the data variability among individual users, and sensor artefacts. In this work, we propose an end-to-end framework for real-time cognitive workload classification with mixture Hyper Long Short Term Memory Networks, a novel variant of HyperNetworks. Evaluating the proposed approach on an eye-gaze pattern dataset collected from simulated driving scenarios of different cognitive demands, we show that the proposed framework outperforms previous baseline methods and achieves 83.9\% precision and 87.8\% recall during test. We also demonstrate the merit of our proposed architecture by showing improved performance over other LSTM-based methods.
Hierarchical Behavioral Repertoires with Unsupervised Descriptors
Apr 19, 2018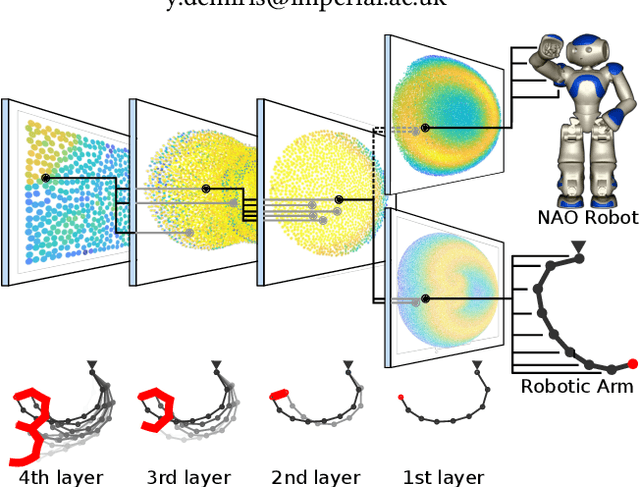
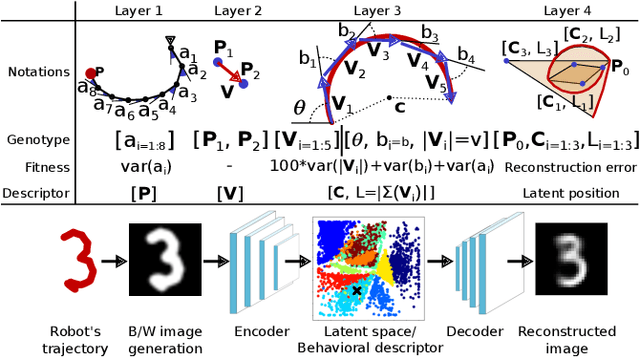
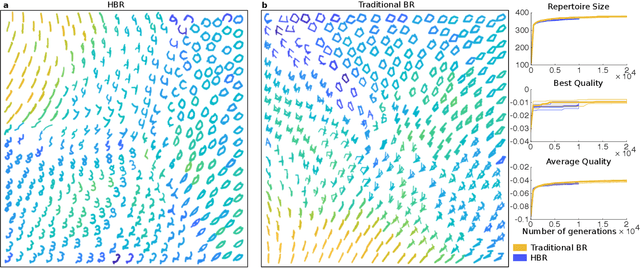
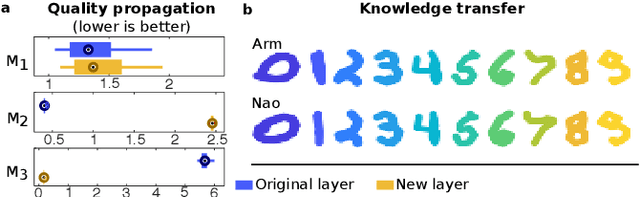
Enabling artificial agents to automatically learn complex, versatile and high-performing behaviors is a long-lasting challenge. This paper presents a step in this direction with hierarchical behavioral repertoires that stack several behavioral repertoires to generate sophisticated behaviors. Each repertoire of this architecture uses the lower repertoires to create complex behaviors as sequences of simpler ones, while only the lowest repertoire directly controls the agent's movements. This paper also introduces a novel approach to automatically define behavioral descriptors thanks to an unsupervised neural network that organizes the produced high-level behaviors. The experiments show that the proposed architecture enables a robot to learn how to draw digits in an unsupervised manner after having learned to draw lines and arcs. Compared to traditional behavioral repertoires, the proposed architecture reduces the dimensionality of the optimization problems by orders of magnitude and provides behaviors with a twice better fitness. More importantly, it enables the transfer of knowledge between robots: a hierarchical repertoire evolved for a robotic arm to draw digits can be transferred to a humanoid robot by simply changing the lowest layer of the hierarchy. This enables the humanoid to draw digits although it has never been trained for this task.
* GECCO 2018
Context-aware Deep Feature Compression for High-speed Visual Tracking
Mar 28, 2018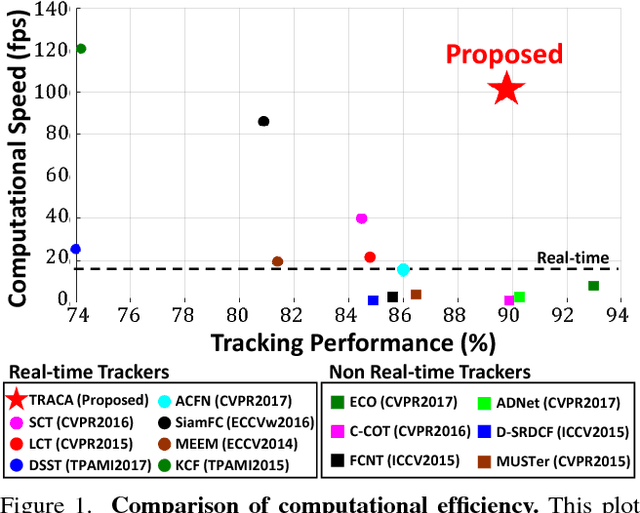
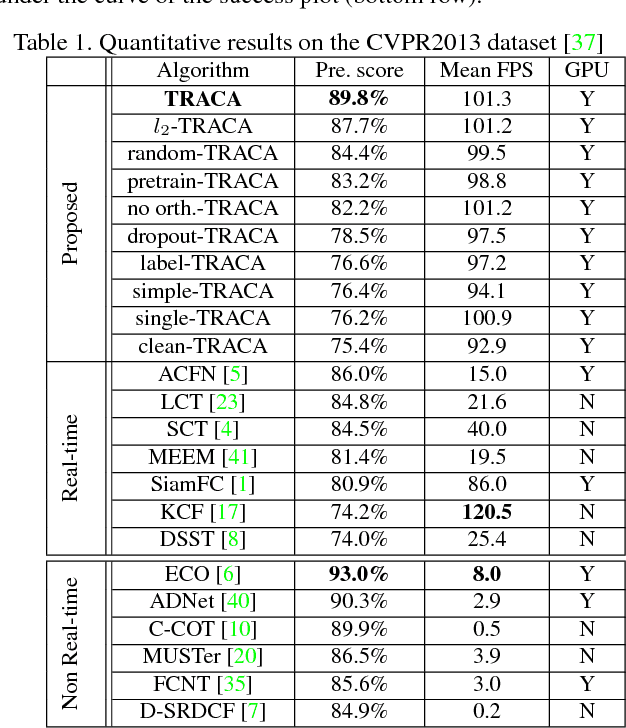
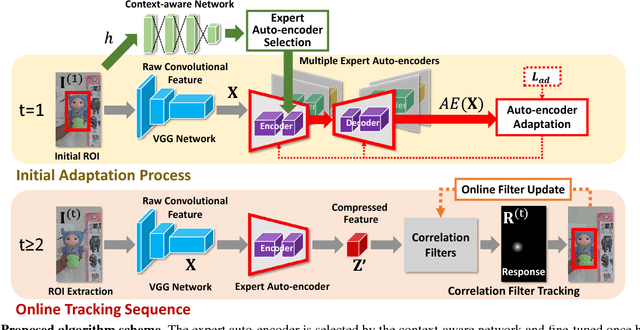
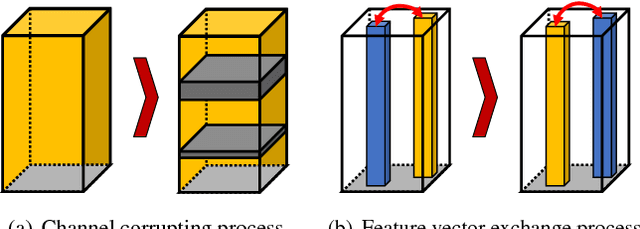
We propose a new context-aware correlation filter based tracking framework to achieve both high computational speed and state-of-the-art performance among real-time trackers. The major contribution to the high computational speed lies in the proposed deep feature compression that is achieved by a context-aware scheme utilizing multiple expert auto-encoders; a context in our framework refers to the coarse category of the tracking target according to appearance patterns. In the pre-training phase, one expert auto-encoder is trained per category. In the tracking phase, the best expert auto-encoder is selected for a given target, and only this auto-encoder is used. To achieve high tracking performance with the compressed feature map, we introduce extrinsic denoising processes and a new orthogonality loss term for pre-training and fine-tuning of the expert auto-encoders. We validate the proposed context-aware framework through a number of experiments, where our method achieves a comparable performance to state-of-the-art trackers which cannot run in real-time, while running at a significantly fast speed of over 100 fps.